前言(未完成)
建议先阅读下《Apache Kafka源码分析》——Producer与Consumer
重新理解kafka
Apache Kafka 是消息引擎系统,也是一个分布式流处理平台(Distributed Streaming Platform)
官网上明确标识 Kafka Streams 是一个用于搭建实时流处理的客户端库而非是一个完整的功能系统。这就是说,你不能期望着 Kafka 提供类似于集群调度、弹性部署等开箱即用的运维特性。坦率来说,这的确是一个“双刃剑”的设计,也是 Kafka 社区“剑走偏锋”不正面 PK 其他流计算框架的特意考量。大型公司的流处理平台一定是大规模部署的,因此具备集群调度功能以及灵活的部署方案是不可或缺的要素。但毕竟这世界上还存在着很多中小企业,它们的流处理数据量并不巨大,逻辑也并不复杂,部署几台或十几台机器足以应付。
kafka 较新的1.0 和 2.0 也主要集中于kafka streams的改进。
消费端优化
多线程 消费
从spring kafka 源码分析 可以看到, spring-kafka 仅使用了一个线程来 操作consumer 从broker 拉取消息,一个线程够用么? 是否可以通过加线程 提高consumer的消费能力呢?
【原创】探讨kafka的分区数与多线程消费 一个消费线程可以对应若干个分区,但一个分区只能被一个consumer 消费 + consumer 对象是线程不安全的==> 一个分区只能被具体某一个消费线程消费。因此,topic 的分区数必须大于一个(由server.properties 的 num.partitions 控制),否则消费端再怎么折腾,也用不了多线程。
【原创】Kafka Consumer多线程实例KafkaConsumer和KafkaProducer不同,后者是线程安全的,因此我们鼓励用户在多个线程中共享一个KafkaProducer实例,这样通常都要比每个线程维护一个KafkaProducer实例效率要高。但对于KafkaConsumer而言,它不是线程安全的,所以实现多线程时通常由两种实现方法:
-
每个线程维护一个KafkaConsumer,多个consumer 可以subscribe 同一个topic
consumer.subscribe(Arrays.asList(topic));,如果consumer的数量大于Topic中partition的数量就会有的consumer接不到数据。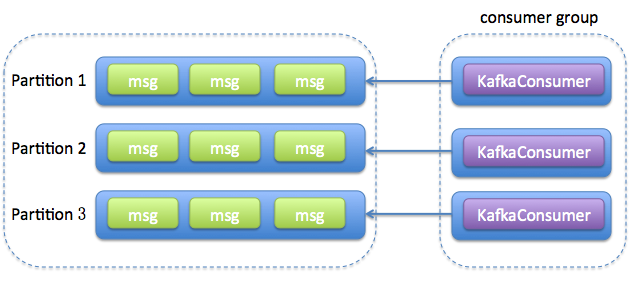
-
维护一个或多个KafkaConsumer,同时维护多个事件处理线程(worker thread)
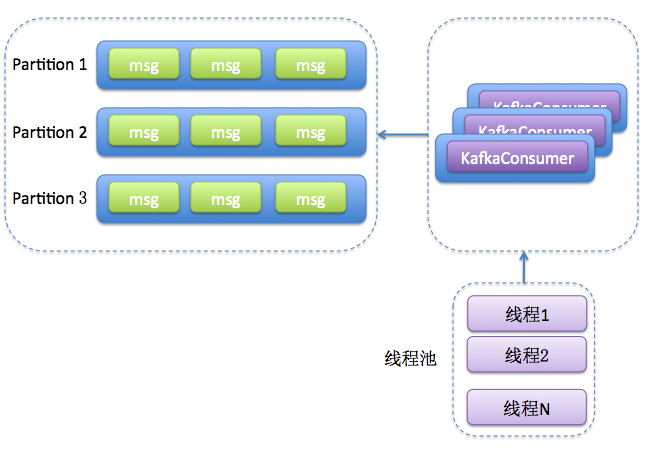
多线程消费的变迁
Why We Replaced Our Kafka Connector with a Kafka Consumer 结合kafka 源码中 ConsumerConnector 被标记为Deprecated 来看,kafka的消费端一开始用的是 ConsumerConnector,现在开始推荐使用 KafkaConsumer
Map<String, Integer> topicCountMap = new HashMap<String, Integer>(); // 一个Topic启动几个消费者线程,会生成几个KafkaStream。
topicCountMap.put(topic, new Integer(KafkaStream的数量));
Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap);
List<KafkaStream<byte[], byte[]>> topicList = consumerMap.get(topic);
for (KafkaStream<byte[], byte[]> kafkaStream : topicList) {
ConsumerIterator<byte[], byte[]> it = stream.iterator();
while (it.hasNext()) {
System.out.println("Receive->[" + new String(it.next().message()) + "]");
}
}
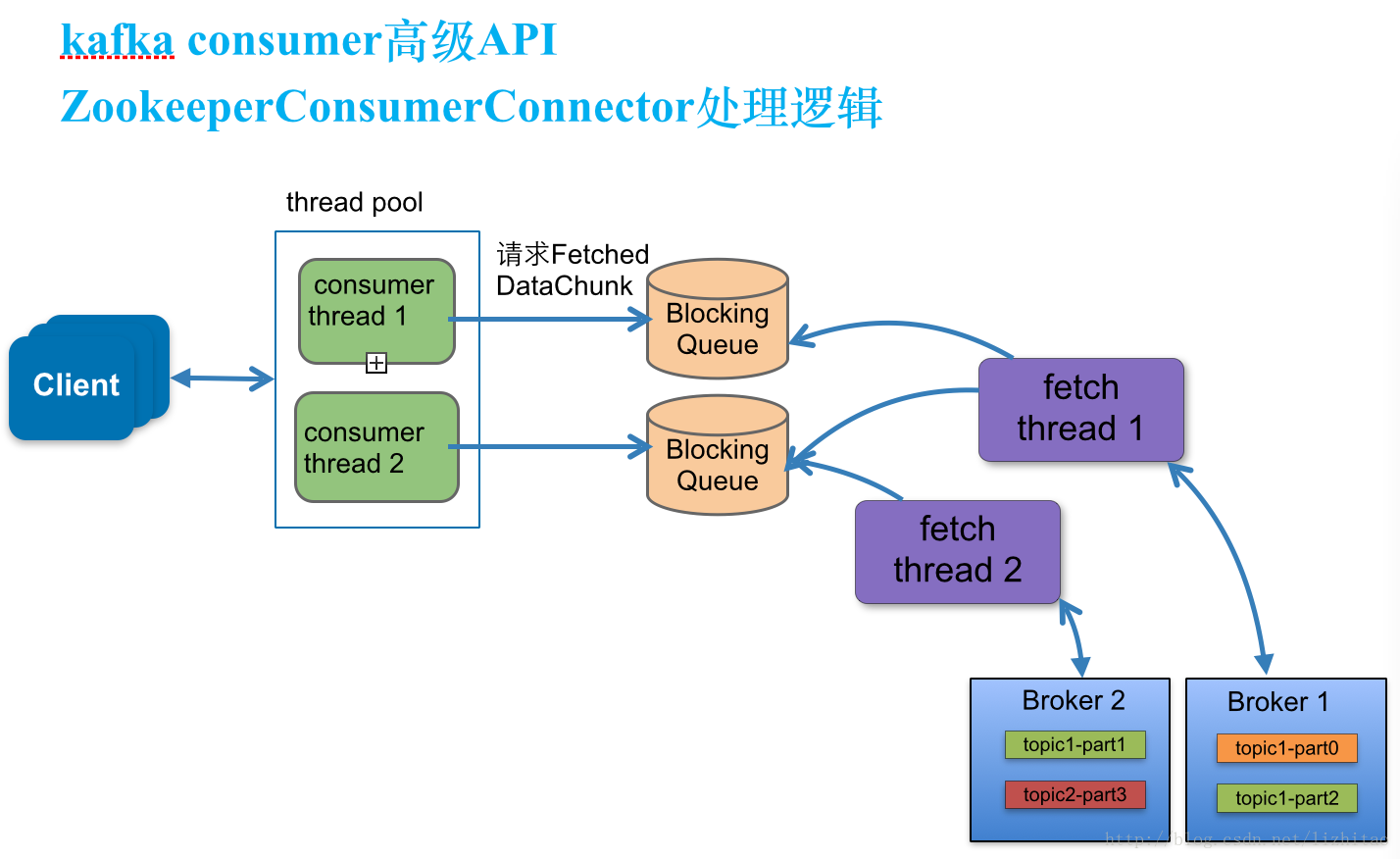
fetcher线程数和topic所在多少台broker有关。一个Topic启动几个消费者线程,会生成几个KafkaStream。一个KafkaStream对应的是一个Queue(有界的LinkedBlockingQueue)
什么时候commit 消息
消费慢的坑(未完成)
kafka消费太慢,误以为consumer挂掉,一直rebalance。背后的原理
生产端优化
一条消息大小不能超过1M
批量发送
其它
- kafka 的版本号分为两个部分:编译 Kafka 源代码的 Scala 编译器版本;kafka 自身版本。