前言
Java Memory Model 提到 The Java virtual machine is a model of a whole computer so this model naturally includes a memory model - AKA the Java memory model. 因为jvm 是一个完整的计算机模型,因此java内存模型 很自然的包含了一个内存模型。
那么同样的道理,jvm 作为 a model of a whole computer,便与os 有许多相似的地方,包括并不限于:
- 针对os 编程的可执行文件,主要指其背后代表的文件格式、编译、链接、加载 等机制
- 可执行文件 的如何被执行,主要指 指令系统及之上的 方法调用等
- 指令执行依存 的内存模型
这三者是三个不同的部分,又相互关联,比如jvm基于栈的解释器与jvm 内存模型 相互依存。
2018.4.21 补充
有一种说法:jvm是os的补充,而非重新造一个os。希望以这个角度为出发点,重新看待本文。
2018.10.22 补充
- jvm 内存模型与物理机/os内存模型的映射 JVM3——java内存模型
- jvm 线程 与 linux 进程/线程模型的映射 AQS1——并发相关的硬件与内核支持
- java io 与 linux io 模型的映射 java io涉及到的一些linux知识
- jvm 一些高级指令(以支持java 高级语法) 对 机器指令的映射 JVM4——《深入拆解java 虚拟机》笔记
2019.03.22 补充
Java crashesThe virtual machine is responsible for emulating a CPU, managing memory and devices, just like the operating system does for native applications (MS Office, web browsers etc).
断断续续的在java内存、多线程、io这块写了几篇博客,跨度有两三年,回顾起来,发现它们正好构成了看待jvm的绝佳方式。you can’t connect the dots looking forward; you can only connect them looking backwards.
我们知道,c 语言代码gcc编译后可以直接执行,其语言与汇编代码具有比较直接的对应关系,笔者个人感觉C比汇编语言主要增强了两点:
- 变量的概念,内存分配变成了变量声明。
- 函数的概念,栈 + cpu出入栈寄存器 + 指令 封装出了函数概念,使得代码有机会(低水平的)模块化编程,简化了大规模开发的复杂度。
class 文件中有类似 monitorenter/monitorexit、invokedynamic 等指令,用以支持synchronized关键字、多态等关键特性,那jvm 做了哪些工作以支持高级指令,使得与java code/字节码 与汇编code 的对应关系不那么明显?从中我们可以在语言的发展道路上受到哪些启发呢?
内存布局
Linux内核基础知识进程内存布局
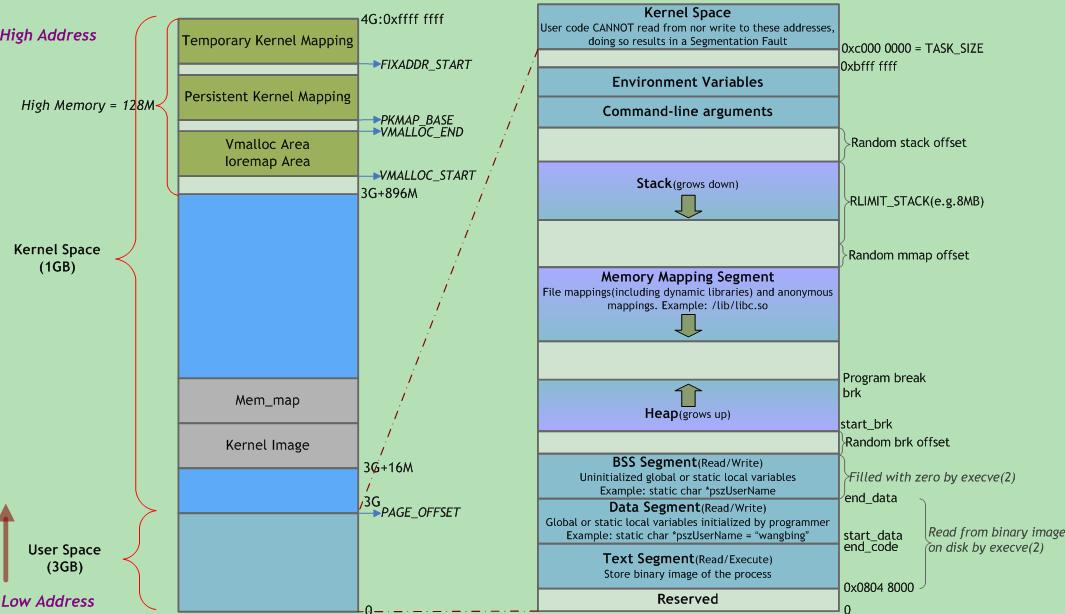
左右两侧均表示虚拟地址空间,左侧以描述内核空间为主,右侧以描述用户空间为主。右侧底部有一块区域“read from binary image on disk by execve(2)”,即来自可执行文件加载,jvm的方法区来自class文件加载,那么 方法区、堆、栈 便可以一一对上号了。
“可执行文件”
在linux中,可执行文件没有唯一的后缀名,本文以”可执行文件”统称。
| java | os | |
|---|---|---|
| jvm | linux os | |
| class 文件 | 可执行文件 |
两者有很多相象的地方,但毕竟机理不同,class文件和可执行文件的不同正是两个os机理不同的反映。而本质上的不同,则要追溯到java的起源:面向网络,为了让“可执行文件”在网络上传输并在不同的系统上执行,发散出很多机制。
class文件格式
因为指令中包含了操作数,可执行文件不只是指令的堆砌。
操作数大部分是地址引用,寄存器(或栈)成了存储引用的地方,作为cpu和内存的“中转站”。还有一些符号引用,需要在指令之前,描述这些符号引用。
class文件中包含方法和属性信息,这些数据为反射机制提供的基础。
class文件的加载
加载的本质,从磁盘上加载,得到的是一个字节数组,然后按照自己的内存模型,把字节数组中对应的数据放到对应的地方。
程序和可执行文件 本身,都将“方法之类”的数据共享,“数据之类”的数据保存多份。
“可执行文件的” 执行
基于栈和基于寄存器
Virtual Machine Showdown: Stack Versus Registers
虚拟机随谈(一):解释器,树遍历解释器,基于栈与基于寄存器,大杂烩
- 典型的RISC架构会要求除load和store以外,其它用于运算的指令的源与目标都要是寄存器。
a += b;对应 x86 就是add a, b - 基于栈的解释器,
a += b;对应jvm 就是iconst_1 iconst_2 iadd istore_0
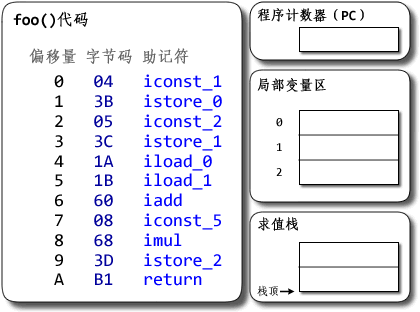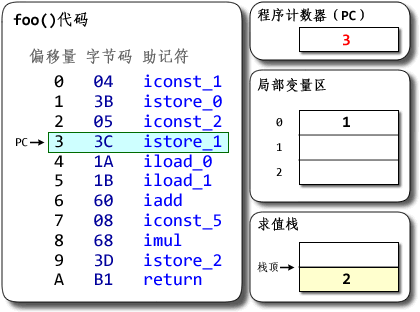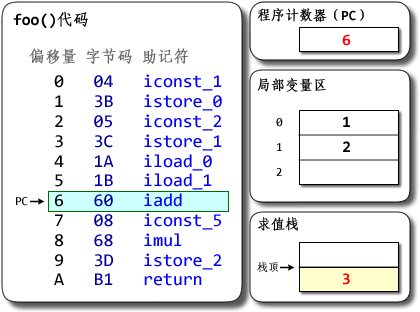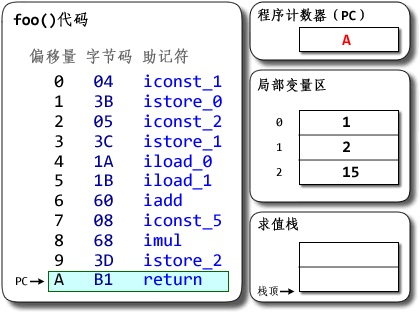
大多数的处理器架构,都有实现硬件栈。有专门的栈指针寄存器,以及特定的硬件指令来完成 入栈/出栈 的操作。当然,硬件栈的主要作用是支持函数调用而不是所有的命令处理。
基于栈的解释器
java是一种跨平台的编程语言,为了跨平台,jvm抽象出了一套内存模型和基于栈的解释器,进而创建一套在该模型基础上运行的字节码指令。(这也是本文不像其它书籍一样先从”class文件格式”讲起的原因)
-
为了跨平台,不能假定平台特性,因此抽象出一个新的层次来屏蔽平台特性,因此推出了基于栈的解释器,与以往基于寄存器的cpu执行有所区别。
-
字节码指令 = 操作码 + 操作数,(操作数可以是立即数,可以存在栈中,也可以是指向堆的引用(引用存在栈中))传统的指令 = 操作码 + 操作数,(操作数据可以是立即数,可以存在寄存器中,也可以是指向内存的引用)此处jvm的栈,说的是栈帧,跟传统的栈还是有不同的,粗略的讲,我们可以说在jvm体系中,用栈替代了原来寄存器的功能。这句话的不准确在于,对于传统cpu执行,线程之间共用的寄存器,只不过在线程切换时,借助了pcb(进程控制块或线程控制块,存储在线程数据所在内存页中),pcb保存了现场环境,比如寄存器数据。轮到某个线程执行时,恢复现场环境,为寄存器赋上pcb对应的值,cpu按照pc指向的指令的执行。
而在jvm体系中,每个线程的栈空间是私有的,栈一直在内存中(无论其对应的线程是否正在执行),轮到某个线程执行时,线程对应的栈(确切的说是栈顶的栈帧)成为“当前栈”(无需重新初始化),执行pc指向的方法区中的指令。
-
类似的编译优化策略
同一段代码,编译器可以给出不同的字节码(最后执行效果是一样的),还可以在此基础上进行优化。比如,对于传统os,将内存中的变量缓存到寄存器。对于jvm,将堆中对象的某个实例属性缓存到线程对应的栈。而c语言和java语言是通过共享内存,而不是共享寄存器或线程的私有栈来进行线程“交流”的,因此就会带来线程安全问题。因此,c语言和java语言都有volatile关键字。(虽然这不能完全解决线程安全问题)