前言 (未完成)
存储结构
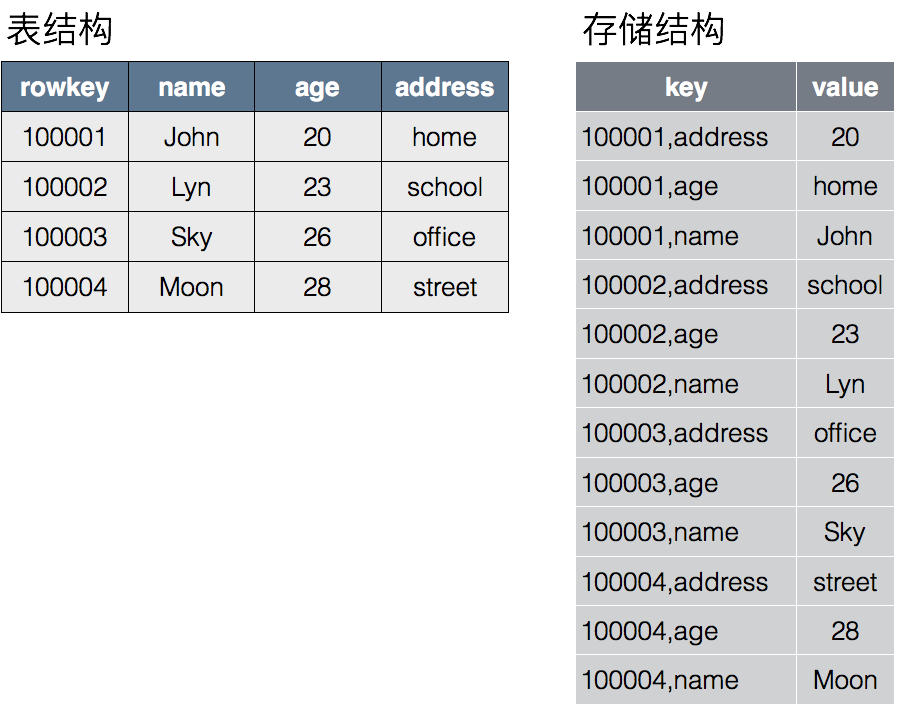
- HBase会按Rowkey的范围,将一张大表切成多个region
- 每行中的每一列在存储文件中都会以Key-value的形式存在于文件中。其中Key的结构为:行主键 + 列名,Value为列的值。存储数据按row-key排序。数据信息 和 结构信息(提高读写效率)混在一起,因为磁盘的缘故, 顺序写即可提高读效率。而查询/读效率 的提高花活儿就比较多了,并且通常 会降低写效率。 所谓 数据结构 或许精髓便是如此吧。
LSM tree
Log Structured Merge Trees(LSM) 原理
- 磁盘随机操作慢,顺序读写快
- 我们要避免随机读写,最好设计成顺序读写
- 顺序写的话,读取就很难受了 ==> 需要数据 结构(哈希、B+树等)提供 更多信息来 提高读效率 ==> 数据结构进而影响 写效率
- 比如mysql 的B+树,新增/更新数据,都要更新B+树的特定节点,学名叫:update-in-place。即 更新/新增一个数据,先找到数据所在的位置,然后进行操作。如果读写 数据key 值的随机性比较大的话,也就是key 分散在不同 树节点 中,则会引起 多次 树节点数据 载入到内存。
- 如果想不 update-in-place,一种方式是Copy-On-Write Tree。更新之前是一个B+树,更新之后,是一个新的B+树。但是因为每个写操作都要重写树结构,放大了写操作(干的活儿多了),降低了写性能。
- 另一种方式 将所有操作(主要是update 和 add) 顺序化。比如以前是将add1、update2、add3 这个操作序列 更新到B+树中,现在,原有的B+树还在,将add1、update2、add3 根据 key 组成一个新的B+树(此时在内存中操作B+树,所以不用担心效率),B+树到一定规模就刷新到磁盘上成一个文件。
- 以前对于一个数据表,只有一个B+树,现在有多个B+树文件(hbase)。读取时,就会逆序的一个一个检查B+树文件,直到key 被找到。 B+树文件越多,读取效率越低,因此会周期性的合并B+树文件
- 因为B+树文件 有一段在内存的空档期,为了防止数据丢失,自然就有一个WAL机制。
该策略 有一个问题是,大量的B+树文件被创建,在它们被合并之前,读效率很低。那么 出现了 Levelled Compaction(比如 LevelDB,其文件的存储结构可以参考redis 的skip list) ,通过优化 合并过程来提高 性能。