前言
从表到里学习JVM实现要了解JVM是如何实现的,首先必须要知道JVM到底是什么、不是什么,表面上应该提供怎样的功能。
大纲
- jvm 在java 体系中的位置
- 类的加载
- 类的执行
- 类的回收
jvm 在java 体系中的位置
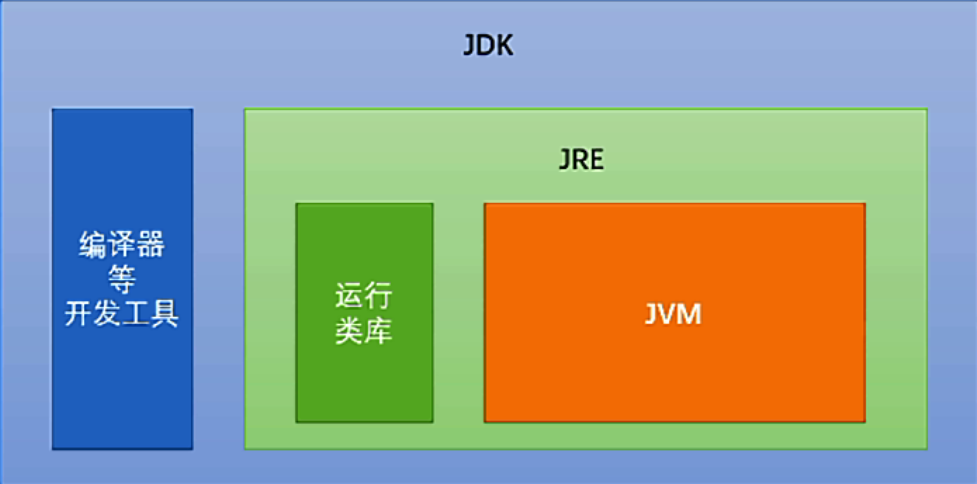
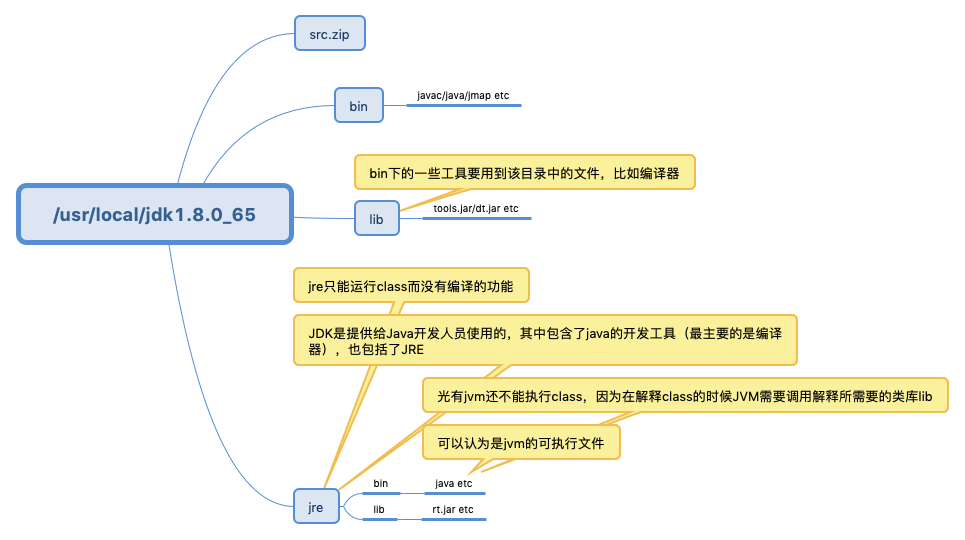
jdk 安装目录含义
Class loaders are responsible for loading Java classes during runtime dynamically to the JVM (Java Virtual Machine). Also, they are part of the JRE (Java Runtime Environment). Hence, the JVM doesn’t need to know about the underlying files or file systems in order to run Java programs thanks to class loaders. 潜台词:Class loaders 是jre 类库的一部分但不是JVM 的一部分
类加载——按类名加载
与c/c++语言不同,c的二进制代码是c代码 + 库函数 编译链接的结果,运行时直接被加载到内存,当然也可以先加载一部分,通过缺页机制按页加载,加载哪一页跟地址有关系。而对于java,实际的“可执行文件”是jvm,像shell一样是个解释器,jvm加载java 代码开始执行,就像shell读入人的指令开始执行。换句话说,如果条件允许,jvm启动起来,像shell一样空转都是可以的。
所以java有一个类加载过程,按名称找到Class文件并加载到内存,并对数据进行校验,转化解析和初始化,最终形成可以被虚拟机直接使用的java类型,这就是虚拟机的类加载机制。
JVM类加载器与ClassNotFoundException和NoClassDefFoundError在”加载“阶段,虚拟机需要完成以下三件事:
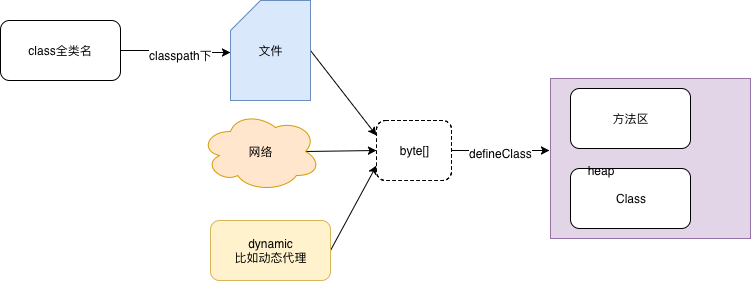
- 通过一个类的全限定名来获取此类的二进制字节流。类似的 maven的基本概念 中提到
URL construction scheme概念,根据一个jar 的groupId + artifactId + version 即可构造一个http url ,从maven remote Repository 下载jar 文件。 - 将字节流代表的静态存储结构转换为方法区的运行时数据结构
- 在内存中创建一个代表此类的java.lang.Class对象,作为方法区此类的各种数据的访问入口。

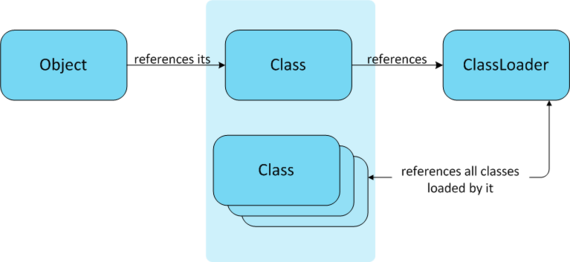
类加载器的双亲委派模型
ClassLoader源码注释:The ClassLoader class uses a delegation model to search for classes and resources.

双亲委派模型要求除了顶层的启动类加载器外,其余的类加载器都必须有自己的父类加载器,类加载器间的父子关系不会以继承关系实现,而是以组合的方式来复用父类加载的代码。
双亲委派模型的工作过程:当一个类加载器收到类加载请求的时候,它会首先把这个请求委托给父类加载器去执行,因此所有的类加载请求最终都会传送到顶层的启动类加载器中,只有当父类加载器也无法找到时才会交给自己去加载。
双亲委派模型的关键就是定义了类的加载过程,先尝试用父类加载器加载,再使用自定义加载器加载,以确保关键的类不被篡改。
使用场景:
- 热部署
- 代码加密
- 类层次划分
延迟加载
class X{
static{ System.out.println("init class X..."); }
int foo(){ return 1; }
Y bar(){ return new Y(); }
}
The most basic API is ClassLoader.loadClass(String name, boolean resolve)
Class classX = classLoader.loadClass("X", resolve);
If resolve is true, it will also try to load all classes referenced by X. In this case, Y will also be loaded. If resolve is false, Y will not be loaded at this point.
ClassNotFoundException和NoClassDefFoundError
Why am I getting a NoClassDefFoundError in Java?
- ClassNotFoundException This exception indicates that the class was not found on the classpath.
- NoClassDefFoundError, This is caused when there is a class file that your code depends on and it is present at compile time but not found at runtime. Look for differences in your build time and runtime classpaths. 引起的原因比较少见,还未掌握到精髓。
ClassLoader 隔离
笔者曾写过一个框架,用户在代码中通过注解使用。注解参数包括类的全类名(用户自定义的策略类),框架通过注解拿到用户的全类名,加载类,然后调用执行。
但当框架给scala小组使用时,scala小组因使用的play框架的classloader是spring classload的子类。用户自定义策略类是scala实现的,写在用户的项目中。
框架实现主流程,其中的某个环节,load 用户自定义的策略类执行。此时,框架代码Class.forName(class name)去load scala class name就力不从心了。为何呀?
- 当在class A中使用了class B时,JVM默认会用class A的class loader去加载class B。
- 每个class loader 有一个自己的search class 文件的classpath 范围。
- class的 加载不是一次性加载完毕的,而是根据需要延迟加载的(上文提到过)。
- 如果class B 不在class loader的classpath search 范围,则会报ClassNotFoundException
在 Java 虚拟机中,类的唯一性是由类加载器实例以及类的全名一同确定的(。即便是同一串字节流,经由不同的类加载器加载,也会得到两个不同的类。在大型应用中,往往借助这一特性,来运行同一个类的不同版本。
与Spring ioc 隔离的对比 Spring IOC 级联容器原理探究。PS:有意思的是,classloader 和 spring ioc 都称之为容器,都具有隔离功能,这背后是否有一个统一的逻辑在?都是class loader,只是class 来源不同,加载后的组织方式不同
JVM内存区域新画法
我觉得《深入理解java虚拟机》,那张jvm内存区域图只是体现了内存区域的组成,我这个可能更好点:
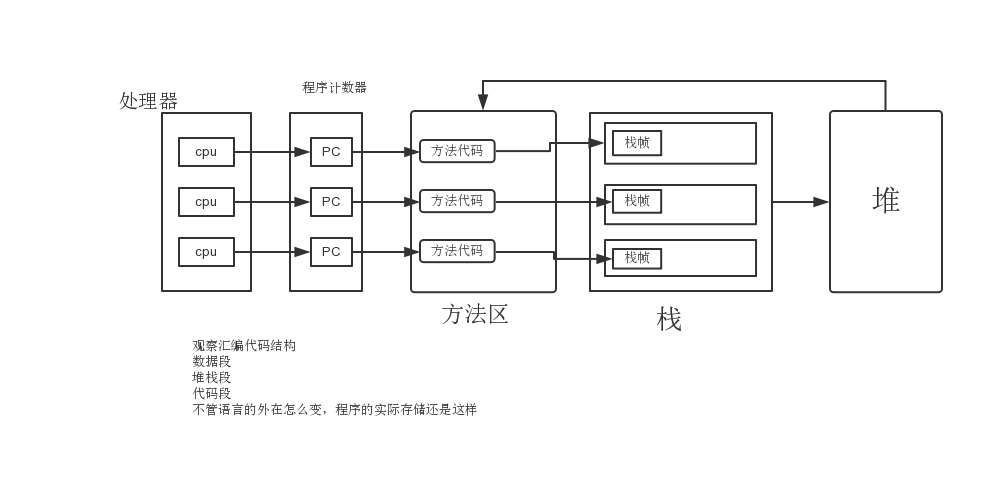
一个cpu对应一个线程,一个线程一个栈,或者反过来说,一个栈对应一个线程,所有栈组成栈区。我们从cpu的根据pc指向的指令的一次执行开始:
- cpu执行pc指向方法区的指令
- 指令=操作码+操作数,jvm的指令执行是基于栈的,所以需要从栈帧中的“栈”区域获取操作数,栈的操作数从栈帧中的“局部变量表”和堆中的对象实例数据得到。
- 当在一个方法中调用新的方法时,根据栈帧中的对象引用找到对象在堆中的实例数据,进而根据对象实例数据中的方法表部分找到方法在方法区中的地址。根据方法区中的数据在当前线程私有区域创建新的栈帧,切换PC,开始新的执行。
PermGen ==> Metaspace
Permgen vs Metaspace in JavaPermGen (Permanent Generation) is a special heap space separated from the main memory heap.
- The JVM keeps track of loaded class metadata in the PermGen.
- all the static content: static methods,primitive variables,references to the static objects
- bytecode,names,JIT information
- before java7,the String Pool
With its limited memory size, PermGen is involved in generating the famous OutOfMemoryError. What is a PermGen leak?
Metaspace is a new memory space – starting from the Java 8 version; it has replaced the older PermGen memory space. The garbage collector now automatically triggers cleaning of the dead classes once the class metadata usage reaches its maximum metaspace size.with this improvement, JVM reduces the chance to get the OutOfMemory error.
垃圾收集算法
不同的区域存储不同性质的数据,除了程序计数器区域不会OOM外,其它的都有可能因为存储本区域数据过多而OOM。
jvm 提供自动垃圾回收机制,但免费的其实是最贵的,一些追求性能的框架会自己进行内存管理。资源的分配与回收——池
如何判断对象已经死亡
说白了,判断还有“引用”引用它么?
-
引用计数法
记录对象被引用的次数
-
可达性分析算法
以一系列GC Roots对象作为起点,从这写节点向下检索,当GC Roots到这些对象不可达时,则证明此对象是不可用的。
回收已死对象所占内存区域
当我们知道哪些对象可以回收时,它们分散在堆的各个地方,如何提高回收效率呢?一次回收完成后,理想状态是:内存是“整齐”的,活着的在一边,空闲的在一边。
-
标记-清除算法
- 实现: 第一遍,标记堆中哪些对象需要被回收;第二遍,回收被标记的对象。
- 特点:效率不高,一次回收后,堆区碎片化
-
复制算法
- 实现:将区域分成两块(或多块),先紧着一块使用,这块用完后,将活着的对象复制到另一块,然后回收这一整块。
- 特点:一部分区域会被浪费,如果对象都是“朝生夕死”的,则非常适合
-
标记-整理算法
- 实现:让所有活着的对象都向边界一端移动,清理端边界以外的堆区域
-
分代收集算法
- 实现:将堆区根据对象生存期分为几块,比如分为新生代和老年代,新生代采用“复制算法”,老年代采用“标记-清理”或“标记-整理”算法。
极客时间《深入拆解Java虚拟机》垃圾回收的三种方式
- 清除sweep,将死亡对象占据的内存标记为空闲。
- 压缩,将存活的对象聚在一起
- 复制,将内存两等分, 说白了是一个以空间换时间的思路。
基本假设:部分的 Java 对象只存活一小段时间,而存活下来的小部分对象则会存活很长一段时间。这个假设造就了 Java 虚拟机的分代回收思想。PS:想提高效率就要限定问题域(优化都是针对特定场景的优化),限定问题域就要充分的发掘待解决问题的特征。
上面三种回收算法,各有各的优缺点,既然优缺点不可避免,那就是将它们用在特定的场合扬长避短。java 虚拟机将堆分为新生代和老年代,并且对不同代采用不同的垃圾回收算法