简介
看源码就是 先摸清宏观路数(毕竟有些设计思想之类的东西,大概指明代码用力的方向),然后顺着几个功能点深挖下去,一个功能点一条点,辅之以一定的类图序列图。几条线搞清楚之后,宏观也会逐渐清晰。
47 advanced tutorials for mastering Kubernetes 设计k8s 的方方面面,未详细读
从技术实现角度的整体设计
A few things I’ve learned about Kubernetes 值得读三遍
从单机到集群到调度
一个逻辑链条是 kubelet ==> api server ==> scheduler。当你一想k8s有点懵的时候,可以从这个角度去发散。
- the “kubelet” is in charge of running containers on nodes
- If you tell the API server to run a container on a node, it will tell the kubelet to get it done (indirectly)
- the scheduler translates “run a container” to “run a container on node X”
kubelet/api server/scheduler 本身可能会变,但它们的功能以及 彼此的交互接口 不会变的太多,it’s a good place to start
etcd: Kubernetes’ brain
Every component in Kubernetes (the API server, the scheduler, the kubelet, the controller manager, whatever) is stateless. All of the state is stored in a key-value store called etcd, and communication between components often happens via etcd.
For example! Let’s say you want to run a container on Machine X. You do not ask the kubelet on that Machine X to run a container. That is not the Kubernetes way! Instead, this happens:
- you write into etcd, “This pod should run on Machine X”. (technically you never write to etcd directly, you do that through the API server, but we’ll get there later)
- the kublet on Machine X looks at etcd and thinks, “omg!! it says that pod should be running and I’m not running it! I will start right now!!”
Similarly, if you want to put a container somewhere but you don’t care where:
- you write into etcd “this pod should run somewhere”
- the scheduler looks at that and thinks “omg! there is an unscheduled pod! This must be fixed!“. It assigns the pod a machine (Machine Y) to run on
- like before, the kubelet on Machine Y sees that and thinks “omg! that is scheduled to run on my machine! Better do it now!!” When I understood that basically everything in Kubernetes works by watching etcd for stuff it has to do, doing it, and then writing the new state back into etcd, Kubernetes made a lot more sense to me.
Reasons Kubernetes is coolBecause all the components don’t keep any state in memory(stateless), you can just restart them at any time and that can help mitigate a variety of bugs.The only stateful thing you have to operate is etcd
源码包结构
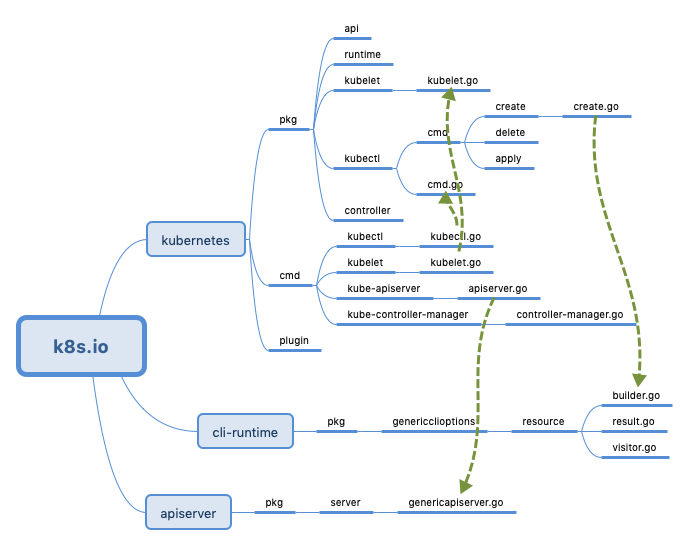
- pkg是kubernetes的主体代码,里面实现了kubernetes的主体逻辑
- cmd是kubernetes的所有后台进程的代码,主要是各个子模块的启动代码,具体的实现逻辑在pkg下
- plugin主要是kube-scheduler和一些插件
go get -d k8s.io/kubernetes
cd $GOPATH/src/k8s.io/kubernetes
然后使用ide 工具比如goland 等就可以打开Kubernetes 文件夹查看源码了。
感觉你 go get github.com/kubernetes 也没什么错,但因为代码中 都是 import k8s.io/kubernetes/xxx 所以推荐前者
从kubectl 开始
A Tour of the Kubernetes Source Code Part One: From kubectl to API Server
以kubectl create -f xx.yaml 为例,你会在pkg/kubectl/cmd/create 下找到一个create.go。类似的,所有kubectl 的命令 都可以在 pkg/kubectl/cmd 下找到。kubectl 命令行库 用的是 spf13/cobra
可以看到,阅读Kubernetes 源码需要一些go 语言基础、常用库、go上的设计模式等沉淀,否则会将技术细节与kubernetes 思想混在在一起
package结构
Go 常用的一些库 在介绍 spf13/cobra会提到 一个command line application 的推荐结构
appName/ cmd/
add.go
your.go
commands.go
here.go
main.go
但我们要注意几个问题
- 其实大部分golang 应用 都可以以command line application 的结构来组织
- k8s 是由 多个command line application 组成的集合,所以其package 结构又有一点不一样。
pkg/kubectl是根据 cobra 推荐样式来的,main.go 的角色由pkg/kubectl/cmd.go来承担(cmd.go 的方法被cmd/kubectl/kubectl.go引用),kubectl 具体命令实现在pkg/kubectl/cmd下
Builders and Visitors
背景
- 而kubectl本身并不包含对其核心资源的访问与控制,而是通过http通信与api-server进行交互实现资源的管理,所以kubectl 操作的最后落脚点 是发送 http 请求
- kubectl 读取用户输入(包括参数、yaml 文件、yaml http地址)后,肯定要在内部用一个数据结构来表示,然后针对这个数据结构 发送http 请求。
-
实际实现中,数据结构有倒是有,但是
- k8s 笼统的称之为 resource,但没有一个实际的resource 对象存在。
- resource 可能有多个,因为
kubectl create -f可以创建多个文件,便有了多个resource - resource 有多个处理步骤,比如对于
kubectl create -f http://xxx要先下载yaml 文件、校验、再发送http 请求
-
针对这几个问题
- k8s 没有使用一个 类似Resources 的对象来聚合所有 resource
- 针对一个resource 的多个处理步骤,k8s 也没有为resource 提供download、sendHttp、downloadAndSendHttp 之类的方法,而是通过对象的 聚合来 代替方法的顺序调用。
所以,k8s 采用了访问者 模式,利用其 动态双分派 特性,参见函数式编程的设计模式
Visitor 接口
type VisitorFunc func(*Info, error) error
// Visitor lets clients walk a list of resources.
type Visitor interface {
Visit(VisitorFunc) error
}
visitor 模式
这部分代码主要在 k8s.io/cli-runtime/pkg/genericclioptions/resource 包下,可以使用goland 单独打开看

以pkg/kubectl/cmd/create/create.go 为demo
// 根据 请求参数 构造 resource
r := f.NewBuilder().
Unstructured().
Schema(schema). // 简单赋值
ContinueOnError(). // 简单赋值
NamespaceParam(cmdNamespace).DefaultNamespace(). // 简单赋值
FilenameParam(enforceNamespace, &o.FilenameOptions). // 文件可以是http 也可以 本地文件,最终都是为了给 builder.path 赋值,path 是一个Visitor 集合
LabelSelectorParam(o.Selector). // 简单赋值
Flatten(). // 简单赋值
Do()
...
// 发送http 请求
err = r.Visit(func(info *resource.Info, err error) error {
...
if !o.DryRun {
if err := createAndRefresh(info); err != nil {
return cmdutil.AddSourceToErr("creating", info.Source, err)
}
}
...
return o.PrintObj(info.Object)
})
- Builder provides convenience functions for taking arguments and parameters from the command line and converting them to a list of resources to iterate over using the Visitor interface.
- Result contains helper methods for dealing with the outcome of a Builder. Info contains temporary info to execute a REST call, or show the results of an already completed REST call.
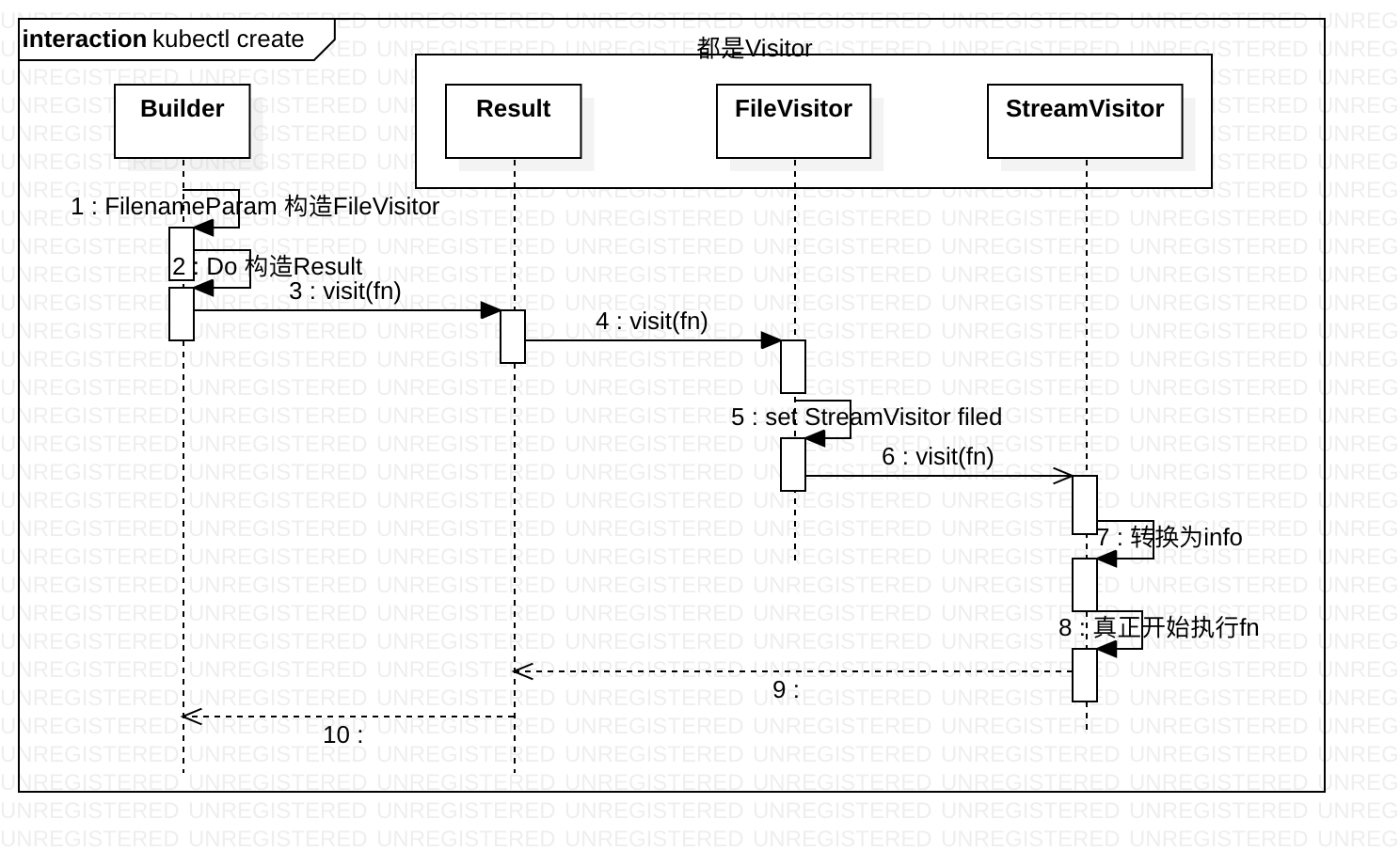
Builder build 了什么东西?将输入转换为 resource,还不只一个。每个resource 都实现了 Visitor 接口,可以接受 VisitorFunc。Result 持有 Builder 的结果——多个实现visitor 接口的resource ,并提供对它们的快捷 访问操作。
在Result 层面,一个resource/visitor 一般代表一个yaml 文件(无论local 还是http),一个resource 内部 是多个visitor 的纵向聚合,比如 URLVisitor.visit
type URLVisitor struct {
URL *url.URL
*StreamVisitor
HttpAttemptCount int
}
func (v *URLVisitor) Visit(fn VisitorFunc) error {
body, err := readHttpWithRetries(httpgetImpl, time.Second, v.URL.String(), v.HttpAttemptCount)
if err != nil {
return err
}
defer body.Close()
v.StreamVisitor.Reader = body
return v.StreamVisitor.Visit(fn)
}
URLVisitor.visit 自己实现了 读取http yaml 文件内容,然后通过StreamVisitor.Visit 负责后续的发送http 逻辑。
visitor 函数聚合
k8s.io/cli-runtime/pkg/genericclioptions/resource/interfaces.go
这里面比较有意思的 是 DecoratedVisitor (纵向聚合,扩充一个visitor的 visit 逻辑)和 VisitorList(横向聚合,将多个平级的visitor 聚合为1个)
type DecoratedVisitor struct {
visitor Visitor
decorators []VisitorFunc
}
func (v DecoratedVisitor) Visit(fn VisitorFunc) error {
return v.visitor.Visit(func(info *Info, err error) error {
if err != nil {
return err
}
for i := range v.decorators {
if err := v.decorators[i](info, nil); err != nil {
return err
}
}
return fn(info, nil)
})
}
DecoratedVisitor 封装了一个visitor, DecoratedVisitor.Visit 执行时 会先让 visitor 执行DecoratedVisitor 自己的私货VisitorFunc ,然后再执行 传入的VisitorFunc,相当于对函数逻辑做了一个聚合。
type VisitorList []Visitor
// Visit implements Visitor
func (l VisitorList) Visit(fn VisitorFunc) error {
for i := range l {
if err := l[i].Visit(fn); err != nil {
return err
}
}
return nil
}
VisitorList 则是将多个 Visitor 聚合成一个visitor,VisitorList.visit 执行时会依次执行 其包含的visitor的Visit 逻辑
回头看
整这么复杂 k8s.io/cli-runtime/pkg/genericclioptions/resource
-
对上层提供两个 抽象Builder 和 Result,上层的调用模式很固定
- 构造Builder、result
- result.visit
-
尽可能在通用层面 实现了kubectl 的所有逻辑,上层通过配置、传入function 即可个性化整体流程
其实最初看完这个实现,笔者在质疑这样做是否有必要,因为kubectl 就是一个发送http 请求的工具(http client)。从常规的实现角度看,create/deploy 等操作各干个的,然后共用一些抽象(比如pod)、工具类(比如HttpUtils) 就可以了。
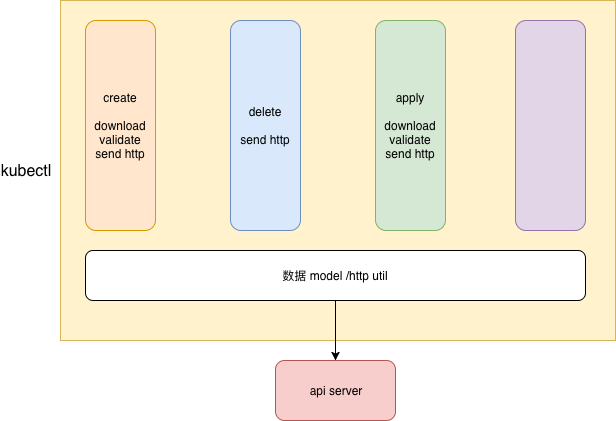
可以看到这个复用层次是比较浅的
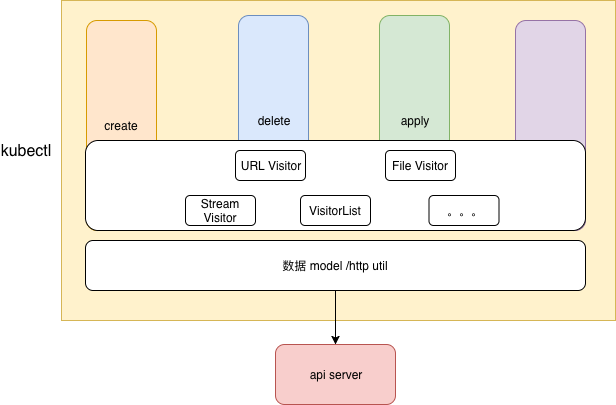
- k8s 将一些公共组件单独提取出来,作为一个库,有点layer的感觉,但还不完全是。
- 借助visitor 模式,完全依靠 函数聚合来聚合逻辑,或许要从函数式编程模式的一些角度来找找感觉。