简介
本文来自对极客时间《深入剖析kubernetes》的学习,作者本身对k8s 有一定的基础,但认为同样一个事情 听听别人 如何理解、表述 是很有裨益的,尤其是作者 还是k8s 领域的大牛。
作者在开篇中提到的几个问题 ,也是笔者一直的疑惑
- 容器技术纷繁复杂,“牵一发而动全身”的主线 在哪里
- Linux 内核、分布式系统、网络、存储等方方面面的知识,并不会在docker 和 k8s 的文档中交代清楚。可偏偏就是它们,才是真正掌握容器技术体系的精髓所在,是我们需要悉心修炼的内功。
一个很长但精彩的故事
打包发布阶段
在docker 之前有一个 cloud foundry Paas项目,使用cf push 将用户的可执行文件和 启动脚本打进一个压缩包内,上传到cloud foundry 的存储中,然后cloud foundry 会通过调度器选择一个可以运行这个应用的虚拟机,然后通知这个机器上的agent 把应用压缩包下载下来启动。由于需要在一个虚拟机中 启动不同用户的应用,cloud foundry为客户的应用单独创建一个称作沙盒的隔离环境,然后在沙盒中启动这些应用进程。
PaaS 主要是提供了一种名叫“应用托管”的能力。虚拟机技术发展 ==> 客户不自己维护物理机、转而购买虚拟机服务,按需使用 ==> 应用需要部署到云端 ==> 部署时云端虚拟机和本地环境不一致。所以产生了两种思路
- 将云端虚拟机 做的尽量与 本地环境一样
- 无论本地还是云端,代码都跑在 约定的环境里 ==> docker 镜像的精髓
与《尽在双11》作者提到的 “docker 最重要的特质是docker 镜像” 一致,docker 镜像提供了一种非常便利的打包机制。
农村包围城市
为应对docker 一家在容器领域一家独大的情况,google 等制定了一套标准和规范OCI,意在将容器运行时和镜像的实现从Docker 项目中完全剥离出来。然并卵,Docker 是容器领域事实上的标准。为此,google 将战争引向容器之上的平台层(或者说PaaS层),发起了一个名为CNCF(Cloud Native Computing Foundation)的基金会。所谓平台层,就是除容器化、容器编排之外,推动容器监控、存储层、日志手机、微服务(lstio)等项目百花争鸣,与kubernetes 融为一体。
此时,kubernetes 对docker 依赖的只是一个 OCI 接口,docker 仍然是容器化的基础组件,但其 重要性在 平台化的 角度下已经大大下降了。若是kubernetes 说不支持 docker?那么。。。
笔者负责将公司的测试环境docker化,一直为是否使用kubernetes 替换mesos 而纠结,从现在看:
- 单从“测试/线上环境容器化” 来看,docker/mesos 也是够用的。
- 但从“测试/线上环境PaaS化”的角度看,打包发布不是全部,加上编排也不是。整个过程中,容器化只是手段。当我在说PaaS时,我在说什么
java 是一个单机版的业务逻辑实现语言,但在微服务架构成为标配的今天,服务发现、日志监控报警、熔断等也成为必备组件(spring cloud 提供了完整的一套)。如果这些组件 都可以使用协议来定义,那么最后用不用java 来写业务逻辑就不是那么重要了。
docker
有哪些容器与虚拟机表现不一致的问题? 本质上还是共享内核带来的问题
- 很多资源无法隔离,也就是说隔离是不彻底的。比如宿主机的 时间,你设置为0时区,我设置为东八区,肯定乱套了
- 很多linux 命令依赖 /proc,比如top,而 容器内/proc 反应的是 宿主机的信息
对于大多数开发者而言,他们对应用依赖的理解,一直局限在编程语言层面,比如golang的godeps.json。容器镜像 打包的不只是应用, 还有整个操作系统的文件和目录。这就意味着,应用以及它运行所需要的所有依赖,都被封装在了一起,进而成为“沙盒”的一部分。参见 linux 文件系统
默认情况下,Docker 会为你提供一个隐含的ENTRYPOINT,即/bin/sh -c。所以在不指定ENTRYPOINT时,CMD的内容就是ENTRYPOINT 的参数。因此,一个不成文的约定是称docker 容器的启动进程为ENTRYPOINT 进程。
一个进程的每种Linux namespace 都可以在对应的/proc/进程号/ns/ 下有一个对应的虚拟文件,并且链接到一个真实的namespace 文件上。通过/proc/进程号/ns/ 可以感知到进程的所有linux namespace;一个进程 可以选择加入到一个已经存在的namespace 当中;也就是可以加入到一个“namespace” 所在的容器中。这便是docker exec、两个容器共享network namespace 的原理。
一个 容器,可以被如下看待
- 在docker registry 上 由manifest + 一组blob/layer 构成的镜像文件
- 一组union mount 在
/var/lib/docker/aufs/mnt上的rootfs - 一个由namespace + cgroup 构成的隔离环境,即container runtime
kubernetes——从容器到容器云
containerize 不是终点
对于大多数用户来说,需求是确定的:提供一个容器镜像,请在一个给定的集群上把这个应用运行起来。从这个角度看,k8s相对swarm、mesos 等并没有特别的优势。
运维的同学都知道,一般公司内的服务器会分为 应用集群、数据集群等,分别用来跑业务应用 和 大数据组件(比如hadoop、spark)等。为何呢?一个是物理机配置不一样;一个是依赖服务不一样,比如应用集群每台主机都会配一个日志采集监控agent,数据集群每台主机也有类似的agent,但因为业务属性不一样,监控的侧重点不一样,所以agent 逻辑不一样。进而,应用集群的服务 不可以随便部署在 数据集群的机器上。容器云之后,服务可以随意编排和移动, 那么物理机就单纯是提供计算了, 服务是否部署在某个机器上 只跟这个机器是否空闲有关,跟机器的划分(应用集群还是大数据集群)无关了。
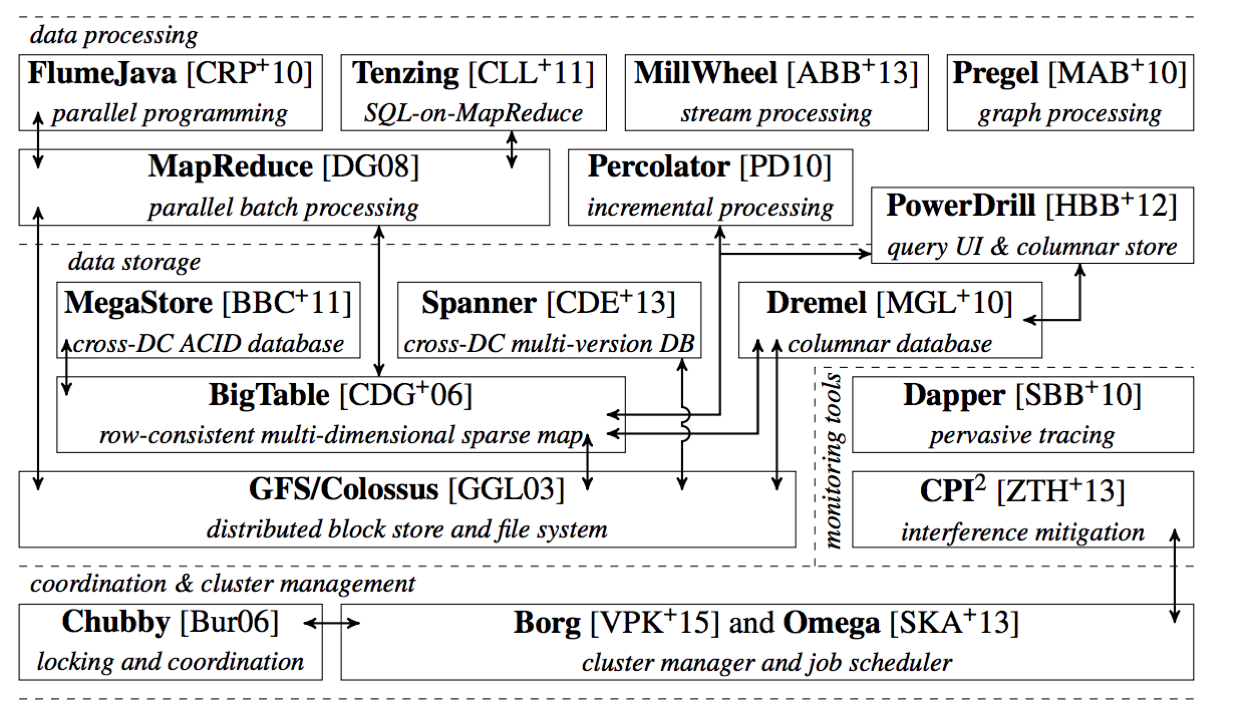
PS:从Borg 在google 基础设施的定位看,或许我们学习k8s,不是它有什么功能,所以我用k8s来做什么事儿。而是打算为它赋予什么样的职责,所以需要k8s具备什么样的能力。 k8s 要做的不是dockerize,也不是containerize,而是作为一个集群操作系统,为此重新定义了可执行文件、进程、存储的形态。
终点是什么
要支持这么多应用,将它们容器化,便要对应用的关系、形态等分门别类,在更高的层次将它们统一进来。
-
任务与任务的几种关系
- 没有关系
- 访问关系,比如web 与 db 的依赖。对应提出了service 的概念
- 紧密关系,比如一个微服务日志采集监控报警 agent 与 一个微服务microservice的关系,agent 读取microservice 产生的文件。对应提出了pod 的概念
- 任务的形态,有状态、无状态、定时运行等
-
如何描述上述信息。k8s中的api对象 有两种
- 待编排的对象,比如Pod、Job、CronJob 等用来描述你的应用
- 服务对象,比如Service、Secret 等,负责具体的平台级功能
为什么k8s会胜出
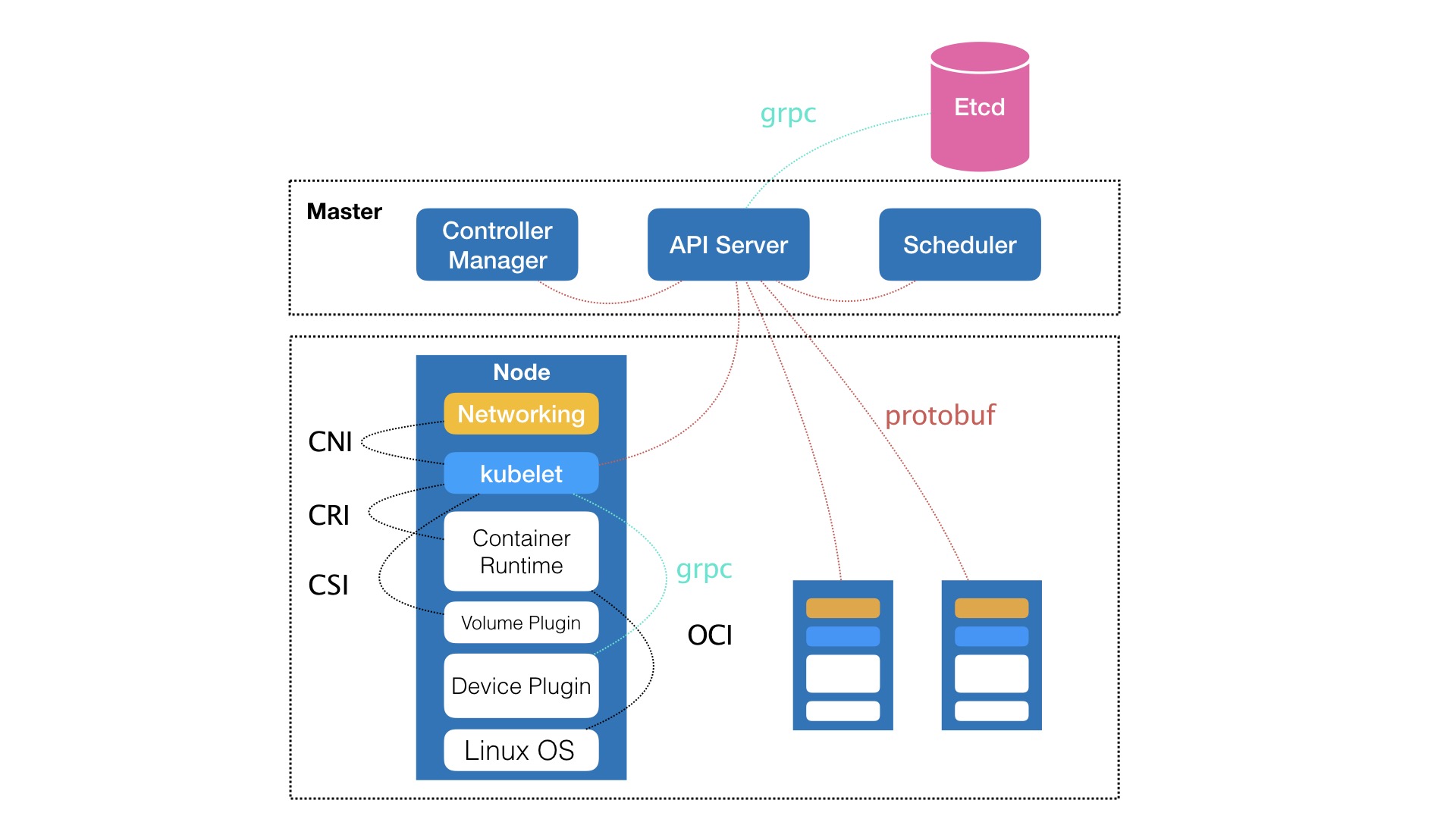
PS:笔者一直对CNI、CSI 有点困惑,为什么不将其纳入到container runtime/oci 的范畴。在此猜测一番
- oci 的两个部分:runtime spec 和 image spec,runtime spec不说了oci就是干这事儿的。对于后者,image spec 若是不统一,runtime spec 也没法统一,更何况docker image才是 docker 的最大创新点,所以干脆放一起了。
- docker 给人的错觉是 创建容器 与 配置容器volume/network 是一起的,其实呢,完全可以在容器启动之后,通过csi、cni 驱动相关工具(比如容器引擎)去做。
- 若是oci 纳入了CSI 和 CNI,则oci 就不是一个单机跑的小工具了。csi和cni 都需要对全局状态有所感知,比如提供一个ipam driver 来维护已分配/未分配的ip。当然,将CNI、CSI 从OCI中剥离,由k8s 在编排/调度层直接操纵,使其最大限度了减少了对container runtime 的依赖性。
2018.9.20 补充,笔者通过私信问了作者,回答是:CNI、CSI 属于PaaS层。
k8s 强在哪里
- 看k8s的组件图,包括master 和node
- node 运行kubelet 对容器进行管理,这与其他调度系统并无不同。
- 所以k8s和其它调度系统有什么区别?区别就在master,k8s的master包括三大组件,而mesos、swarm 只提供了其中的scheduler 类似的功能。
为什么k8s 好?理念的先进性,先进性体现在两点:
-
kubernetes脱胎于Borg,Borg在的时候还没docker呢?所以天然的,Borg及其衍生的kubernetes 从未将docker 作为架构的核心,而仅仅将它作为一个container runtime 实现,k8s的核心是cni、csi、cri、oci等。相对的,mesos是docker的使用者,也必然是docker特性的迁就者。docker之于mesos,像西欧的国王与领主;docker之于k8s,像是皇帝与巡抚。都是从上到下管理民众,但皇帝却可以在巡抚之外,搞出总督、河道总督、御史之类的东东,以灵活的应对各种问题。因为本质上资源在皇帝,而不是巡抚手中。比如,k8s想管理有状态服务,提出了csi,而不管docker有什么“看法”。k8s的大部分特性,不是说原来的docker或者后来的mesos做不到,而是对于mesos来说,一些需求若是docker本身不支持,mesos基本也实现不了。
-
k8s系统的梳理了任务的形态以及任务之间的关系,并为未来留有余地,提供了声明式的api。所谓声明式api,一个小的体会就是,比如web 和 mysql 容器部署在一起
- 对于swarm,就是指明这两个容器部署在一起, link 在一起。也就是,你看了swarm的部署文件,目标和实现原理是一致的。
- 对于k8s,就是指明两个容器属于 同一个pod就行了。如果你初学的k8s,连这个效果是如何实现的都不知道,目标和原理不是直接对应的。k8s 中针对不同需求,类似pod的组件 很多
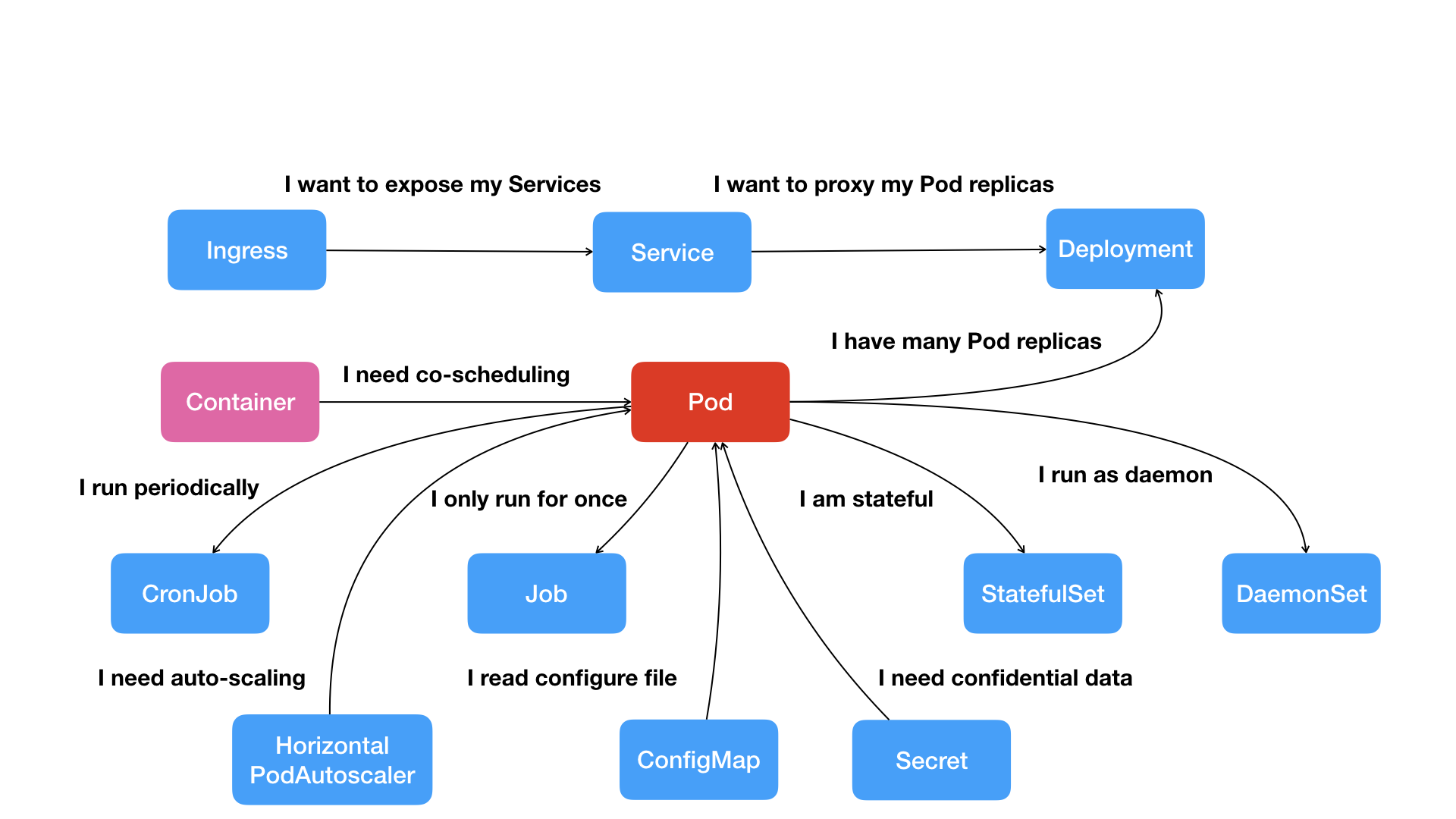
声明式的好处 在ansible学习 ansible 与其它集群操作工具saltstack等的对比中也有体现。
kubernetes 真正的价值,在于提供了一套基于容器构建分布式系统的基础依赖。k8s提供了一种宏观抽象,作为一个集群操作系统,运行各种类型的应用。
k8s 部署
kubelet 这个奇怪的名字,来自于Borg项目里的同源组件Borglet
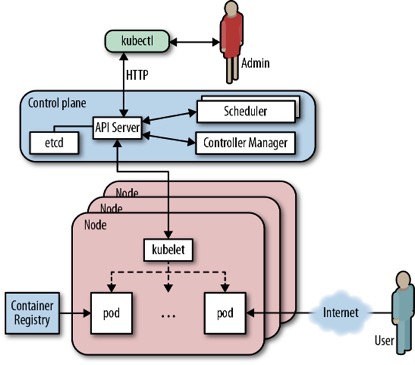
部署跟k8s的运行机制分不开,具体的说就是
| 部署什么 | 如何部署 | |
|---|---|---|
| master节点 | 三大组件 | 容器 |
| node节点 | kubelet | 直接运行 |
| 插件,比如kube-proxy/dns/网络/可视化/存储 | 容器 | |
| zk | 看个人喜欢 |
当应用本身发生变化时 开发和运维可以通过容器和镜像来进行同步。 当应用部署参数发生变化时,这些yaml 文件就是它们相互沟通和信任的媒介。
关联内容参见 在CoreOS集群上搭建Kubernetes
kubernetes objects
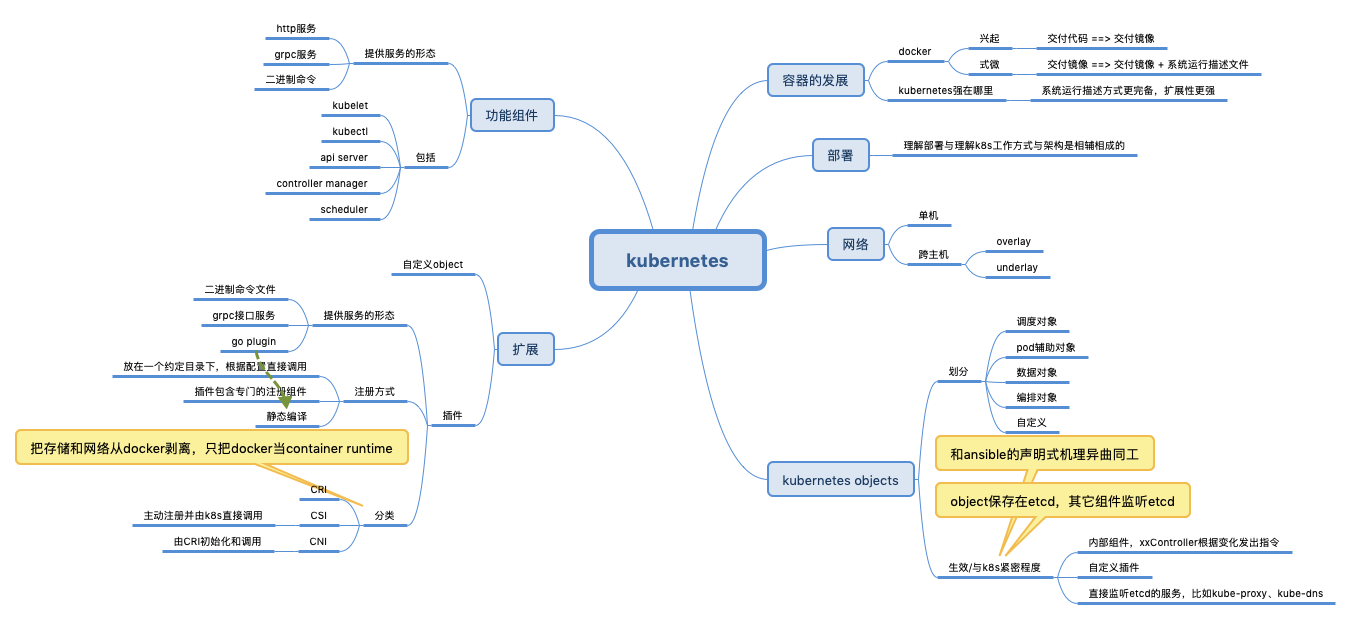
yaml配置参见kubernetes yaml配置
| 现在 | 未来 |
|---|---|
| 进程 | 容器 |
| 进程组 | pod |
| 可执行文件 | 镜像 |
| 操作系统 | kubernetes |
在细讲k8s的具体技术时,文章的主要脉络:

小结
认知的几点规律任何知识体系都是分层的,k8s也不例外,理念 ==> 核心组件 apiserver,kuberlet,controler ==> pod、rs之类。Kubernetes 项目的成功,是成千上万云计算平台上的开发者用脚投票的结果。云计算平台上的开发者们所关心的,并不是调度,也不是资源管管理,更不是网络或者存储,他们关心的只有一件事,那就是 Kubernetes 的 API。也就是声明式 API 和控制器模式;这个 API 独有的编程范式,即 Controller 和 Operator。declarative API的内涵参见Kubernetes源码分析——apiserver
Kubernetes 项目的本质其实只有一个,那就是“控制器模式”。这个思想,不仅仅是 Kubernetes 项目里每一个组件的“设计模板”,也是 Kubernetes 项目能够将开发者们紧紧团结到自己身边的重要原因。作为一个云计算平台的用户,能够用一个 YAML 文件表达我开发的应用的最终运行状态,并且自动地对我的应用进行运维和管理。这种信赖关系,就是连接Kubernetes 项目和开发者们最重要的纽带。
作者的另一篇文章后Kubernetes时代,2019的容器技术生态会发生些什么?不同于一个只能生产资源的集群管理工具,Kubernetes 项目最大的价值,乃在于它从一开始就提倡的声明式 API 和以此为基础“控制器”模式。Kubernetes 项目为使用者提供了宝贵的 API 可扩展能力和良好的 API 编程范式,催生出了一个完全基于 Kubernetes API 构建出来的上层应用服务生态。可以说,正是这个生态的逐步完善与日趋成熟,才确立了 Kubernetes 项目如今在云平台领域牢不可破的领导地位,也间接宣告了竞品方案的边缘化。
未来:应用交付的革命不会停止Kubernetes 项目一直在做的,其实是在进一步清晰和明确“应用交付”这个亘古不变的话题。只不过,相比于交付一个容器和容器镜像, Kubernetes 项目正在尝试明确的定义云时代“应用”的概念。在这里,应用是一组容器的有机组合,同时也包括了应用运行所需的网络、存储的需求的描述。而像这样一个“描述”应用的 YAML 文件,放在 etcd 里存起来,然后通过控制器模型驱动整个基础设施的状态不断地向用户声明的状态逼近,就是 Kubernetes 的核心工作原理了。PS: 以后你给公有云一个yaml 文件就可以发布自己的应用了。

笔者个人微信订阅号
