前言
最近一阵听了一两个深度学习的讲座,有些不明觉厉,特总结一下
为什么要深度学习?从计算机编程的角度讲,解决问题的手段一般有两种
- 将”规则”代码化
- 穷举,利用”规则”干掉不符合条件的
问题是,对于有些东西,无法用规则来描述,或者即便能够描述,对计算能力的要求也过高.这迫使人们使用新的方法来解决问题,即学习人脑的思维方式.
三百多页ppt,就说比较好的学习材料李宏毅 / 一天搞懂深度學習
陆奇最新演讲:没有学习能力,看再多世界也没用 绝对高屋建瓴,推荐多看几遍。
《智能商业》如果我们将数据看做数据时代的一桶高标号汽油,那算法无疑就是这台引擎。机器学习是算法一次决定性的跃升,也正是在这次跃升中,数据对算法的巨大被充分显现出来。任何一个算法模型,尤其是能够自我学习、自我优化的算法模型,都承担着在成千上万可能的因素中寻找出所隐藏的联系的艰巨任务。工业革命使得体力劳动自动化,信息革命使得脑力劳动自动化,而机器学习使得自动化过程本身自动化。
人脑神经网络
一个人在出生之前,脑中的1000亿个神经元已经几乎全部准备好,而神经元之间的连接网络则是十分稀疏的。因为婴儿未能意识思考,故此,他只会凭外界的刺激而制造连接网络。
任何声音、景物、身体活动,只要是新的(第一次),都会使得脑里某些神经元的树突和轴突生长,与其他神经元连接,构成新的网络。同样的刺激第二次出现时,会使第一次建立的网络再次活跃。就是说,新网络只能在有新刺激的情况下产生。一个人的一生之中,不断有新的网络产生出来,同时有旧的网络萎缩、消失。
一个旧的网络,对同样的刺激会特别敏感,每次都会比前一次启动得更快、更有力。多次之后,这个网络便会深刻到成为习惯或本能了。这便是学习和记忆的成因。
人工智能 ==> 机器学习 ==> 深度学习
大多数机器学习的目标是为特定场景开发预测引擎,一个算法将接收到一个域的信息(例如,一个人过去观看过的电影),权衡输入做出一个有用的预测(未来想看的不同电影的概率)
常用的有超过15种机器学习方法,每种方法使用不同的算法结构以基于接收的数据优化预测。
《神经网络与深度学习》小结
主线:
- 神经元如何模拟
- 神经元之间如何连接
- 简单神经网络
- 多层神经网络,分层是人脑学习的基本规律
模拟一个神经元:
- 信号源处理:
s=p1w1+p2w2+p3w3+pnwn+b - 传递函数:f(s)
各个变量的含义
- p代表树突,一个输入信号源
- w代表树突的强度权重
- f(s),比如s是一个任意整数值,而要求的输出只能是0或1两个值,这就需要f(s)做一个转换。
神经元之间的连接不是固定不变的,在人的学习和成长过程中,一些新的连接会被逐渐建立起来,还有一些连接可能会消失。外界刺激就是神经网络的输入,在接收刺激后,刺激信号将传递到整个网络中,影响所有的神经元状态,神经元之间彼此连接并相互制约影响,不断调整彼此间的连接强度,直到达到稳定的状态,并最终对刺激做出反应。神经元之间的关系变迁形成了生物体的学习过程。
训练过程:
- 在上述神经元的表达式中w和b随机确定,p、s根据训练数据确定,f(s)有固定的几种选型,貌似根据经验确定
- 根据实际输出与s的误差,校正w、b
据总结,可以得出本书线索
- 单层神经网络:确定输入特征,单层,根据一定的数据训练即可
- 多层神经网络(浅层学习):确定输入特征,一层中间层,输出层,确定每层神经元数量(大于输入特征数,具体值依赖对精度和运行速度的权衡),根据一定的数据训练即可。训练算法:BP算法。BP算法可以训练五层(三个中间层)以内的神经网络。
-
深度神经网络(深度学习):输入特征,多层(五层以上)中间层(分层或分级处理是大脑识别一个物体的主要过程),输出层。涉及到特征选取(基于经验无法确定的话,便要学习特征)、中间层数确定(根据经验)、单层训练、回归训练等问题。
深度学习首先利用无监督学习对每一层进行逐层预训练去学习特征;每次单独训练一层,并将训练结果作为更高一层的输入;然后到最上层改用监督学习从上到下进行微调去学习模型。
任何事物都可以划分成粒度合适的浅层特征(或者通过了解,或者通过特征学习),这些浅层特征可以作为第二层输入特征。
自动编码器
如何学习特征,用到了自编码器。参考文章
自动编码器基于这样一个事实:原始input(设为x)经过加权(W、b)、映射/传递函数(Sigmoid)之后得到y,再对y反向加权映射回来成为z。
通过反复迭代训练(W、b),使得误差函数最小,即尽可能保证z近似于x,即完美重构了x。
那么可以说(W、b)是成功的,很好的学习了input中的关键特征,不然也不会重构得如此完美。Vincent在2010年的论文中做了研究,发现只要训练W就可以了。
其它材料
利用机器学习,我们至少能解决两个大类的问题:
- 分类(Classification)
- 回归(Regression)。
为了解决这些问题,机器学习就像一个工具箱,为我们提供了很多现成的的算法框架,比如:LR, 决策树,随机森林,Gradient boosting等等,还有近两年大热的深度学习的各种算法,但要想做到深入的话呢,只是会使用这些现成的算法库还不够,还需要在底层的数学原理上有所把握。比如
- 研究优化理论,才能够有更好的思路去设计和优化目标函数;
- 研究统计学,才能够理解机器学习本质的由来,理解为什么机器学习的方法能够使得模型一步步地逼近真实的数据分布;
- 研究线性代数,才能够更灵活地使用矩阵这一数学工具,提高了性能且表达简洁,才能够更好地理解机器学习中涉及到的维数灾难及降维问题;
- 研究信息论,才能够准确地度量不同概率分布之间的差异。
AI 在国内的发展
如何看待张潼老师离职腾讯? - 姚冬的回答 - 知乎 中国过去三十年,IT行业应用的技术基本都是美国那边已经成熟了的技术,已经在欧美普遍使用,甚至有些已经形成盈利性产业了。AI 是我们第一次和全球同步遇到一次新技术浪潮,AI技术在欧美也没有成熟,中国的IT企业其实基本没有落后多少,我们第一次感受到了新技术发展初期带来的各种问题。比如 新技术在实践中比旧技术表现还差,新技术不可靠,新技术成本太高,找不到落地用途等等。AI技术很新,也就意味着问题很多,但是并不意味着技术没前途,只是需要些时间去发展完善。
邵浩:大家现在都在谈人工智能技术,而且很多人都会把人工智能和 AlphaGo 以及深度学习划上等号。其实人工智能涵盖的学科范围是非常广泛的,包括心理学、神经科学、哲学、认知科学等等。我们目前看到的大量成果都只是深度学习和大数据的化学反应。而且,大量的人工智能应用还都是人工 + 智能,离真正的认知智能差距甚远。如何利用技术赋能产品,得到用户和资本的认可,才是最重要的
小结
本段可能有错误,会随着学习的深入逐步调整。
笔者是java开发,暂时无意对深度学习进行深入学习,但通过对相关材料的手机,基本确定了深度学习为什么可用?
- 模拟人工神经网络,用数学的方式模拟了神经元。
- 神经网络的组成机制:多个中间层、加上输入输出,构成神经网络。上一层输出是下一层的输入,不可跨层连接。正好对上了“分层是人脑学习的基本规律”
- 训练,定义神经元的输入输出,初始随机设置(W,b)随后不断迭代,根据误差调整(W,b)
- 逐层训练,不同场景下(训练数据是否带标签(一般是分类结果)),训练方法不同(用作反馈作用的误差的定义方式不同)
2018.11.19 补充,最近笔者掌握了几个信息
- 中国最近兴起了一个产业,活跃于十八线县城及农村, 比如给你几十万张图片,标记出图片中所有的垃圾桶。然后位于北京的人工智能it 公司通过机器学习 就可以识别各种垃圾桶。这其实就是模拟了人的学习过程,一开始认为蓝色的是垃圾桶,后来发现跟颜色没关系。后来认为圆的也是垃圾桶, 后来发现跟形状没关系,等见得足够多,机器就会有一个模糊的认知:能装东西的、较深的、桶形都可以是垃圾桶。
- 一个技术分享,分享人提到人工智能的当前阶段:有多少人工,就有多少智能。
对架构的影响
从技术演变的角度看互联网后台架构到了2017之后,前面千奇百怪的后端体系基本上都趋同了。Kafka的实时消息队列,Spark的流处理(当然现在也可以换成Flink,不过大部分应该还是Spark),然后后端的存储,基于Hive的数据分析查询,然后根据业务的模型训练平台。各个公司反正都差不多这一套,在具体细节上根据业务有所差异,或者有些实力强大的公司会把中间一些环节替换成自己的实现,不过不管怎么千变万化,整体思路基本都一致了。个人认为,Machine Learning的很大一个好处,是简化业务逻辑,简化后台流程,不然一套业务一套实现,各种数据和业务规则很难用一个整体的技术平台来完成。
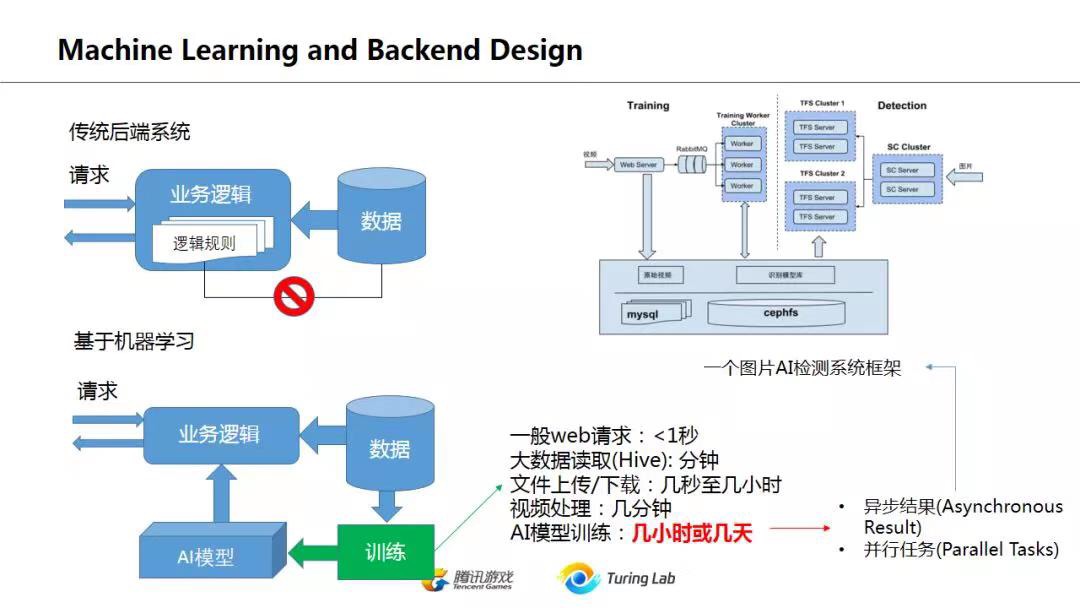
在传统后端系统中,业务逻辑其实和数据是客观分离的,逻辑规则和数据之间并不存在客观联系,而是人为主观加入,并没形成闭环,如上图左上所示。而基于机器学习的平台,这个闭环就形成了,从业务数据->AI模型->业务逻辑->影响用户行为->新的业务数据这个流程是自给自足的。这在很多推荐系统中表现得很明显,通过用户行为数据训练模型,模型对页面信息流进行调整,从而影响用户行为,然后用新的用户行为数据再次调整模型。而在机器学习之前,这些观察工作是交给运营人员去手工猜测调整。PS:从图示看,不是完全接管系统(与用户直接交互),而是接管系统的配置部分
现代的后端数据处理越来越偏向于DAG的形态,Spark不说了,DAG是最大特色;神经网络本身也可以看作是一个DAG(RNN其实也可以看作无数个单向DNN的组合);TensorFlow也是强调其Graph是DAG,另外编程模式上,Reactive编程也很受追捧。无论如何,数据,数据的跟踪Tracking,数据的流向,是现代后台系统的核心问题,只有Dataflow和Data Pipeline清晰了,整个后台架构才会清楚。
一文读懂深度学习:从神经元到BERT
拟合
形象的说,拟和就是把平面上一系列的点,用一条光滑的曲线连接起来.因为这条曲线有无数种可能,从而有各种拟和方法.拟和的曲线一般可以用函数表示.根据这个函数的不同有不同的拟和的名字.