简介
- 简介
- build 时使用http代理
- 镜像仓库
- local storage/docker镜像与容器存储目录
- 基础镜像选型的教训
- 警惕镜像占用的空间
- 多阶段构建
- 和ssh的是是非非
- build 过程
- COPY VS ADD
- tag
- docker 镜像下载加速
- 引用
build 时使用http代理
2019.4.3 补充
docker build --build-arg HTTPS_PROXY='http://userName:password@proxyAddress:port' \
--build-arg HTTP_PROXY='http://userName:password@proxyAddress:port' \
-t $IMAGE_NAGE .
当你在公司负责维护docker 镜像时,不同镜像的Dockerfile 为了支持协作及版本跟踪 一般会保存在git 库中。制作镜像 通常需要安装类似jdk/tomcat 等可执行文件,这些文件建议使用远程下载的方式(因为git 保存二进制文件 不太优雅),以安装tomcat 为例
RUN \
DIR=/tmp/tomcat && mkdir -p ${DIR} && cd ${DIR} && \
curl -sLO http://mirrors.tuna.tsinghua.edu.cn/apache/tomcat/tomcat-8/v8.5.40/bin/apache-tomcat-8.5.40.tar.gz &&\
tar -zxvf apache-tomcat-8.5.40.tar.gz -C /usr/local/ && \
mv /usr/local/apache-tomcat-8.5.40 /usr/local/tomcat && \
rm -rf ${DIR}
镜像仓库
2018.12.21 补充
image在docker registry 存储
DockOne技术分享(二十六):Docker Registry V1 to V2一个重要的视角,你可以观察registry daemon或container 在磁盘上的存储目录
| v1 | v2 | |
|---|---|---|
| 代码地址 | https://github.com/docker/docker-registry | https://github.com/docker/distribution |
| 存储最上层目录结构 | images 和repositories | blobs 和 repositories |
| 最叶子节点 | layer 文件系统的tar包 Ancestry 父亲 layer ID |
data |
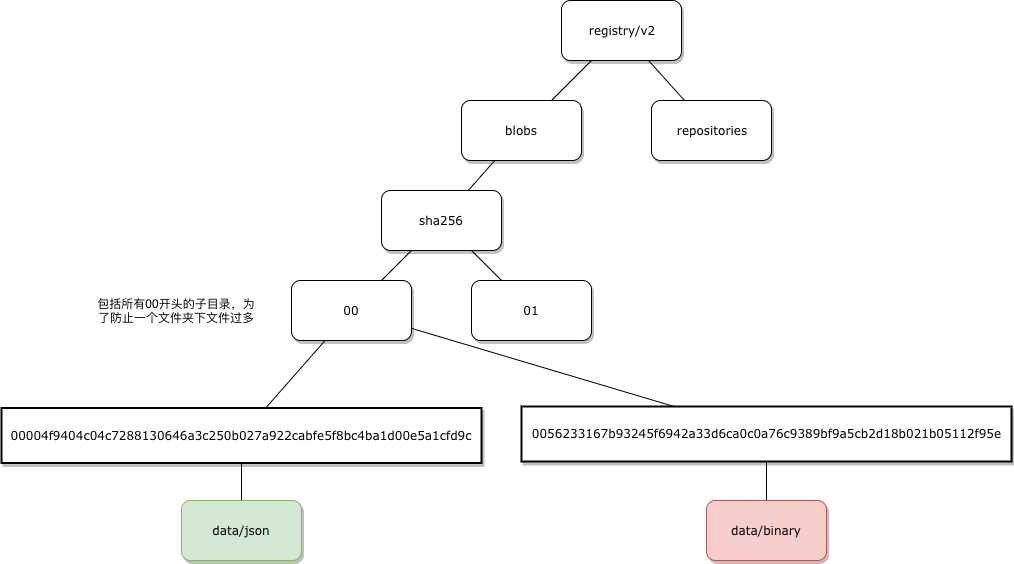
官方关于manifest 的解释Image Manifest Version 2, Schema 1
如何搭建私有镜像仓库执行 docker pull 实际上就是先获取到镜像的 manifests 信息,再拉取 blob。
api
汇总下来如下
- repository,经典存储库名称由2级路径构成,V2的api不强制要求这样的格式
- digest(摘要),摘要是镜像每个层的唯一标示
-
manifests
- v2 主要是提出了manifest, The new, self-contained image manifest simplifies image definition and improves security
- 一个docker image是由很多的layer组成,下载镜像时也是以layer为最小单元下载的。在v1的时代docker image,镜像结构有一种链表一样的组织,当下载完一个layer时,才能得到parent信息,然后再去下载parent layer。v2改变了这种结构,在image的manifest文件中存储了所有的layer信息,这样拿到所有的layer信息,就可以并行下载了
默认情况下,registry不允许删除镜像操作,需要在启动registry时指定环境变量REGISTRY_STORAGE_DELETE_ENABLED=true
源码分析
registry v2架构的的核心是一个web服务器,具体实现是用go语言的net/http包中的http.Server,在registry初始化时绑定了rest接口。请求会触发相应的handler,handler会从后端存储中取出具体的数据并写入response。
垃圾回收
In the context of the Docker registry, garbage collection is the process of removing blobs from the filesystem when they are no longer referenced by a manifest. Blobs can include both layers and manifests.
Filesystem layers are stored by their content address in the Registry. This has many advantages, one of which is that data is stored once and referred to by manifests.
Content Addressable Storage (CAS):Manifests are stored and retrieved in the registry by keying off a digest representing a hash of the contents. One of the advantages provided by CAS is security: if the contents are changed, then the digest no longer matches.
Layers are therefore shared amongst manifests; each manifest maintains a reference to the layer. As long as a layer is referenced by one manifest, it cannot be garbage collected.
Manifests and layers can be deleted with the registry API (refer to the API documentation here and here for details). This API removes references to the target and makes them eligible for garbage collection. It also makes them unable to be read via the API.
If a layer is deleted, it is removed from the filesystem when garbage collection is run. If a manifest is deleted the layers to which it refers are removed from the filesystem if no other manifests refers to them.
上文涉及到几个问题:
- image 是如在 docker distribution 上组织的?
- image 是分层的,所以image 肯定不是存储的最小单位,那是layer么?layer的存在形式是什么?image 和 layer之家的关系如何表示
- image 之间的依赖关系如何表示?
从这段话可以认为:
- image 在 docker distribution的表现形式为 manifest 和 blob,blob 包括manifest 和 layers,所以可以认为基本的存储是 manifest 和 layer
- manifest 和 layer 都有一个Content Address。layer 只存一份儿,可以被多个manifest 引用。只要还有一个 manifest 在引用layer, layer就不会被垃圾回收。 有点像jvm的垃圾回收和引用计数。
- registry API 中的删除 操作,是soft delete
- 对layer 来说, 是解除了 manifest 与layer的引用关系,使得layer 可以被删除
- 对manifest 来说,是解除了其与target的关系
- 真正物理删除要靠 garbage collection
对于docker 本地来说,可以通过docker rmi删除镜像,但对于docker distribition 来说,通过garbage collection 来防止镜像膨胀。
提炼一下
- 逻辑结构,一般体现逻辑概念:image,layer,manifest
- 物理结构,逻辑概念无关的通用概念 Blob,很多逻辑概念在存储上根本体现不到。以新的角度看数据结构 存储结构主要包括:顺序存储、链接存储、索引存储、散列存储 ,你光看存储结构根本就不知道树、图是什么鬼。
在v2 schema 下 逻辑结构
- layer是独立的,layer 之间不存在父子关系。layer 一以贯之的可以被多个image 共用。image 和 layer 之间是一对多关系
- 一对多关系由manifest 表述,一个manifest 可以视为一个image
存储结构
- Blob 是基本的存储单位,image 在存储结构上感知不到
- Blob 有两种形式,一个是文本(manifest json 字符串),一个是binary(tar.gz 文件)
local storage/docker镜像与容器存储目录
以virtualbox ubuntu 14.04为例
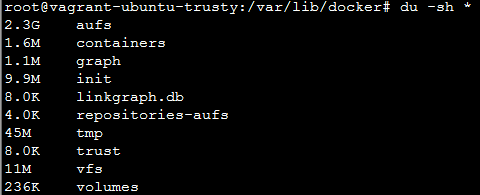
repositories-aufs这个文件输出的内容,跟”docker images”输出的是“一样的”。
graph中,有很多文件夹,名字是image/container的id。文件夹包括两个子文件:
- json 该镜像层的描述,有的还有“parent”表明上一层镜像的id
- layersize 该镜像层内部文件的总大小
aufs和vfs,一个是文件系统,一个是文件系统接口,从上图每个文件(夹)的大小可以看到,这两个文件夹是实际存储数据的地方。
不论image 的registry storage 还是 local storage 都在表述一个事儿:layer存储以及 layer 如何组装成一个image
基础镜像选型的教训
公司实践时,做docker 镜像的时候为了精简,用了alpine, 但是alpine的一些表现跟ubuntu 这些大家常见的OS不一样,几百号开发,光天天回答为啥不能xxx(参见jar冲突),就把人搞死了。
很多公司比如个推镜像体系 猪八戒网DevOps容器云与流水线均采用Centos 为base 镜像
所以,技术极客跟推广使用还是有很大区别的。
警惕镜像占用的空间
假设公司项目数有2k+,则使用docker后,一台物理机上可能跑过所有服务, 自然可能有2k+个镜像,庞大的镜像带来以下问题
- 占满物理机磁盘,笔者在jenkins + docker 打包机器上碰到过这种现象
- 虽未占满磁盘,但大量的镜像目录文件严重拖慢了docker pull 镜像的速度,进而导致调度系统(比如mesos+marathon)认为无法调度而将任务转移到别的机器上,导致某个主机空有资源但就是“接收”不了任务分派。
为此,我们要周期性的清理 docker 占用的磁盘空间。如何清理Docker占用的磁盘空间?
docker 的磁盘使用 包括:images/containers/volumnes,可以用docker system df 查看。
清理命令有两种选择:
- docker system prune命令可以用于清理磁盘,删除关闭的容器、无用的数据卷和网络,以及dangling镜像(即无tag的镜像)。
- docker system prune -a命令清理得更加彻底,可以将没有容器使用Docker镜像都删掉。
多阶段构建
Use multi-stage builds multi-stage builds 的重点不是multi-stage 而是 builds
先使用docker 将go文件编译为可执行文件
FROM golang:1.7.3
WORKDIR /go/src/github.com/alexellis/href-counter/
COPY app.go .
RUN go get -d -v golang.org/x/net/html \
&& CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o app .
因为笔者一直是直接做镜像,所以没这种感觉。不过这么做倒有一点好处:可执行文件的实际运行环境 可以不用跟 开发机相同。学名叫同构/异构镜像构建。
然后将可执行文件 做成镜像
FROM alpine:latest
RUN apk --no-cache add ca-certificates
WORKDIR /root/
COPY app .
CMD ["./app"]
和ssh的是是非非
2018.12.01 补充 ssh连接远程主机执行脚本的环境变量问题
背景:
- 容器启动时会运行sshd,所以可以ssh 到容器
- 镜像dockerfile中 包含
ENV PATH=${PATH}:/usr/local/jdk/bin docker exec -it container bash可以看到 PATH 环境变量中包含/usr/local/jdk/binssh root@xxx到容器内,观察 PATH 环境变量,则不包含/usr/local/jdk/bin
这个问题涉及到 bash的四种模式
- 通过ssh登陆到远程主机 属于bash 模式的一种:login + interactive
- 不同的模式,启动shell时会去查找并加载 不同而配置文件,比如
/etc/bash.bashrc、~/.bashrc、/etc/profile等 - login + interactive 模式启动shell时会 第一加载
/etc/profile /etc/profile文件内容默认有一句export PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
所以 docker exec 可以看到 正确的PATH 环境变量值,而ssh 到容器不可以,解决方法之一就是 制作镜像时 向/etc/profile 追加 一个export 命令
build 过程
cid=$(docker run -v /foo/bar debian:jessie)
image_id=$(docker commit $cid)
cid=$(docker run $image_id touch /foo/bar/baz)
docker commit $(cid) my_debian
image的build过程,粗略的说,就是以容器执行命令(docker run)和提交更改(docker commit)的过程
COPY VS ADD
将文件添加到镜像中有以下两种方式:
-
COPY 方式
COPY resources/jdk-7u79-linux-x64.tar.gz /tmp/ RUN tar -zxvf /tmp/jdk-7u79-linux-x64.tar.gz -C /usr/local RUN rm /tmp/jdk-7u79-linux-x64.tar.gz -
ADD 方式
ADD resources/jdk-7u79-linux-x64.tar.gz /usr/local/
两者效果一样,但COPY方式将占用三个layer,并大大增加image的size。一开始用ADD时,我还在奇怪,为什么docker自动将添加到其中的xxx.tar.gz解压,现在看来,能省空间喔。
tag
假设tomcat镜像有两个tag
- tomcat:7
- tomcat:6
当你docker push tomcat,不明确指定tag时,docker会将tomcat:7和tomcat:6都push到registry上。
所以,当你打算让docker image name携带版本信息时,版本信息加在name还是tag上,要慎重。
docker 镜像下载加速
两种方案
- 使用private registry
- 使用registry mirror,以使用daocloud的registry mirror为例,假设你的daocloud的用户名问
lisi,则DOCKER_OPTS=--registry-mirror=http://lisi.m.daocloud.io