简介
AQS其实就是java.util.concurrent.locks.AbstractQueuedSynchronizer。这个类是整个java.util.concurrent的核心之一,是理解整个java并发包的突破口。
有些时候,名词限制了我们对事物的认识。我们谈到锁、信号量这些,分析它们如何实现,或许走入了一个误区。Locks, Mutexes, and Semaphores: Types of Synchronization Objects 中认为锁是一个抽象概念,包括:
- 竞态条件。只有一个进入,还是多个进入,还是读写进入,线程能否重复获取自己已占用的锁
- 获取锁失败时的反应。提示失败、自旋还是直接阻塞,阻塞能不能被打断
按照这些不同,人们给他mutex、信号量等等命名
所以,本文更愿意将锁描述为:抽象并发问题、提供并发支持。
硬件对并发的支持
实现原子操作:
- 关中断指令、内存屏障指令、停止相关流水线指令
- 对于单核cpu,禁止抢占。
- 对于SMP,提供lock 指令。lock指令是一种前缀,它可与其他指令联合,用来维持总线的锁存信号直到与其联合的指令执行完为止。比如基于AT&T的汇编指令
LOCK_PREFIX xaddw %w0,%1,xaddw 表示先交换源操作数和目的操作数,然后两个操作数求和,存入目的寄存器。为了防止这个过程被打断,加了LOCK_PREFIX的宏(修饰lock指令)。
这些指令,辅助一定的算法,就可以包装一个自旋锁、读写锁、顺序锁出来。os中,lock一词主要指自旋锁。注意,自旋锁时,线程从来没有停止运行过。
操作系统对并发的支持
操作系统内部,本就存在对资源的并发访问。
通过对硬件指令的包装,os提供原子整数操作等系统调用。本质上,通过硬件指令,可以提供对一个变量的独占访问。
int atomic_read(const atomic_t *v)
// 将v设置为i
int atomic_set(atomic_t *v,int id);
通过对硬件指令的封装,操作系统可以封装一个自旋锁出来。
- 获取锁spin_lock_irq:用变量标记是否被其他线程占用,变量的独占访问,发现占用后自旋,结合关中断指令。
- 释放锁spin_unlock_irq:独占的将变量标记为未访问状态
那么在获取锁与释放锁之间,可以实现一个临界区。
spin_lock_irq();
// 临界区
spin_unlock_irq();
操作系统中,semaphore与自旋锁类似的概念,只有得到信号量的进程才能执行临界区的代码;不同的是获取不到信号量时,进程不会原地打转而是进入休眠等待状态(自己更改自己的状态位)
struct semaphore{
spinlock_t lock;
unsigned int count;
struct list_head wait_list;
}
// 获取信号量,会导致睡眠
void down(struct semaphore *sem);
// 获取信号量,会导致睡眠,但睡眠可被信号打断
int down_interruptible(struct semaphore *sem);
// 无论是否获得,都立即返回,返回值不同,不会导致睡眠
int down_trylock(struct semaphore *sem);
// 释放信号量
void up(struct semaphore *sem))
通过自旋锁,os可以保证count 修改的原子性。线程尝试修改count的值,根据修改后count值,决定是否挂起当前进程,进而提供semaphore和mutex(类似于semaphore=1)等抽象。也就是说,semaphore = 自旋锁 + 线程挂起/恢复。
jvm 线程 映射到 linux 线程
Understanding Linux Process States
| 进程的基本状态 | 运行 | 就绪 | 阻塞 | 退出 |
|---|---|---|---|---|
| Linux | TASK_RUNNING | TASK_INTERRUPTIBLE、TASK_UNINTERRUPTIBLE | TASK_STOPPED/TASK_TRACED、TASK_DEAD/EXIT_ZOMBIE | |
| java | RUNNABLE | BLOCKED、WAITING、TIMED_WAITING | TERMINATED |
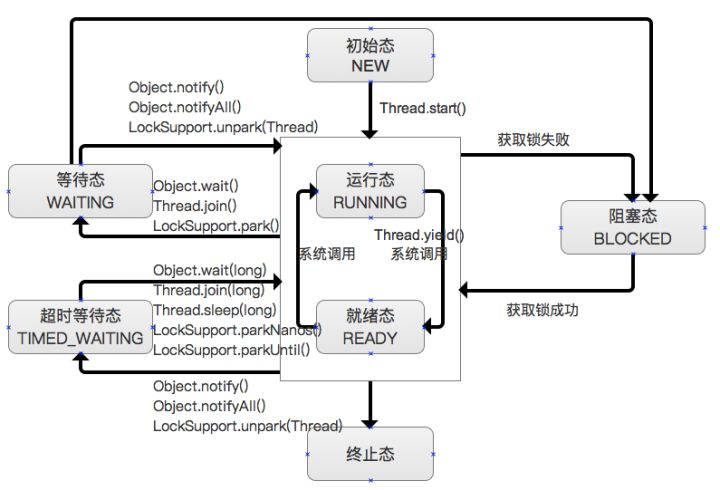
PS: JVM3——java内存模型 提到jvm 内存模型和硬件模型的不同:jvm 和 物理机 对“内存/存储” 有不同的划分,jvm 中没有cpu、cpu core 等抽象存在,也没有寄存器、cpu cache、main memory 的区分,因此 stack、heap 数据 可能分布在 寄存器、cpu cache、main memory 等位置。因此,jvm 执行时,存在jvm 内存操作到 物理内存操作的转换,同样的线程状态 也有类似类似的转换。
从中可以发现,linux没按os课本上的来,java没按os的来。为了管理进程时方便,都会在进程基本状态里细分几种状态。这里主要讲下java中的blocked、waiting
- blocked,过去分词,被卡住的。线程进入这个状态完全是无辜的,只要别的线程退出临界区,jvm自动解除线程的blocked状态
- waiting,主动卡住自己,别的线程调用notify后,jvm解除线程的waiting状态
- time_wating,通过
Thread.sleep()进入该状态。相当于使用某个时间资源作为锁对象,当时间达到时,触发线程回到工作状态。
从linux内核来看, BLOCKED、WAITING、TIMED_WAITING都是等待状态。做这样的区分,是jvm出于管理的需要(两个原因的线程放两个队列里管理,如果别的线程运行出了synchronized这段代码,jvm只需要去blocked队列,放个出来。而某人调用了notify(),jvm只需要去waitting队列里取个出来。),本质上是:who when how唤醒线程。
Java线程中wait状态和block状态的区别? - 赵老师的回答 - 知乎
linux 内核如何实现阻塞操作:
static ssize_t xxx_read(struct file *file, const char *buffer, size_t count, loff_t *ppos){
DECLARE_WAITQUEUE(wait, current); /*定义等待队列节点,与当前进程绑定 */
add_wait_queue(&read_waitq, &wait); /*添加节点(当前进程)到等待队列中*/
do {
if (rd_flag == 1) {
if (file->f_flags &O_NONBLOCK) { /*判断文件的flag,是否非阻塞 */
ret = - EAGAIN;
goto out;
}
__set_current_state(TASK_INTERRUPTIBLE);/*标记当前进程为睡眠*/
schedule(); /*交出处理器,调度其他进程*/
}while (rd_flag == 0);
/*读设备*/
device_read(...);
rd_flag == 0;/*设置状态为不可读*/
out:
remove_wait_queue(&read_waitq, &wait);/* 将节点(当前进程)移出等待队列 */
set_current_state(TASK_RUNNING);/*标记进程状态为 TASK_RUNNING*/
return ret;
}
这段代码貌似有问题,但说明了一点:linux 线程(本身就是一个轻量级进程)是没有BLOCKED 状态的,其实现是将linux 线程状态置为TASK_INTERRUPTIBLE 并加入 等待队列。Linux进程上下文切换过程context_switch详解–Linux进程的管理与调度(二十一)
linux 线程也没有TIMED_WAITING 状态,sleep实现原理
几个常识:
- 代码最后都是指令序列
- 用户态内核态 不切换cpu
| 从上到下 | 常规java code | synchronized java code | volatile java code |
|---|---|---|---|
| 编译 | 编译器加点私货 | monitor enter/exist | 除了其变量定义的时候有一个Volatile外,之后的字节码跟有无Volatile完全一样 |
| class 字节码 | 扩充后的class 字节码 | ||
| 运行 | jvm加点私货 | 锁升级:自旋/偏向锁/轻量级锁/重量级锁 | |
| 机器码 | 扩充后的机器码 | 加入了lock指令,查询IA32手册,它的作用是使得本CPU的Cache写入了内存,该写入动作也会引起别的CPU invalidate其Cache | |
| 用户态 | |||
| 系统调用 | mutex系统调用 | ||
| 内核态 | |||
| 可能用到了 semaphore struct | |||
| 线程加入等待队列 + 修改自己的状态 + 触发调度 |
操作系统提供的手段:
| 可以保护的内容 | 临界区描述 | 执行体竞争失败的后果 | |
|---|---|---|---|
| 硬件 | 一个内存的值 | 某时间只可以执行一条指令 | 没什么后果,继续执行 |
| os-自旋 | 变量/代码 | 多用于修改变量(毕竟lock指令太贵了) | 自旋 |
| os-信号量 | 变量/代码 | 代码段不可以同时执行 | 挂起(修改状态位) |
一个复杂项目由n行代码实现,一行代码由n多系统调用实现,一个系统调用由n多指令实现。那么从线程安全的角度看:锁住系统总线,某个时间只有一条指令执行 ==> 安全的修改一个变量 ==> 提供一个临界区。通过向上封装,临界区的粒度不断地扩大。
语言层面模拟os 实现
硬件提供了一些支持,并通过系统调用等 将一些原子性操作的能力直接暴露给了语言层。
cas
锁实现
final ReentrantLock lock = this.lock;lock.lock();
try {
这个区域的代码可以认为是线程安全的
} finally {
lock.unlock();
}
cas实现
for (;;) {
int current = get();
这个区域的代码可以认为是线程安全的
int next = current + delta;
if (compareAndSet(current, next))
return current;
}
- 使用操作系统 原生的锁 类似于使用悲观锁 修改变量。cas 则相当于 乐观锁修改变量。
-
Disruptor论文中讲述了我们所做的一个实验。这个测试程序调用了一个函数,该函数会对一个64位的计数器循环自增5亿次。
场景 耗时 单线程无锁 300ms 单线程有锁(实际没有竞争) 10000ms 两线程有锁 224000ms 单线程cas 5700ms
内存屏障
什么是内存屏障?它是一个CPU指令
- 插入一个内存屏障,相当于告诉CPU和编译器先于这个命令的必须先执行,后于这个命令的必须后执行
- 强制更新一次不同CPU的缓存。例如,一个写屏障会把这个屏障前写入的数据刷新到缓存,这样任何试图读取该数据的线程将得到最新值
volatile,Java内存模型将在写操作后插入一个写屏障指令,在读操作前插入一个读屏障指令。
说白了,这是除cas 之外,又一个暴露在 java 层面的指令。
volatile 也是有成本的 剖析Disruptor:为什么会这么快?(二)神奇的缓存行填充
| 从CPU到 | 大约需要的 CPU 周期 | 大约需要的时间 |
|---|---|---|
| 主存 | 约60-80纳秒 | |
| QPI 总线传输(between sockets, not drawn) | 约20ns | |
| L3 cache | 约40-45 cycles | 约15ns |
| L2 cache | 约10 cycles | 约3ns |
| L1 cache | 约3-4 cycles | 约1ns |
| 寄存器 | 1 cycle |
另一个材料
2018.7.16 补充 聊聊原子变量、锁、内存屏障那点事
当一个执行中的程序的数据被多个执行流并发访问的时候,就会涉及到同步(Synchronization)的问题。同步的目的是保证不同执行流对共享数据并发操作的一致性。说白了,还是并发读写问题。
-
下图看着 跟
实例 ==> local cache ==> db一样,跟db 线程读写db 也一样。所以还是一个并发读写问题。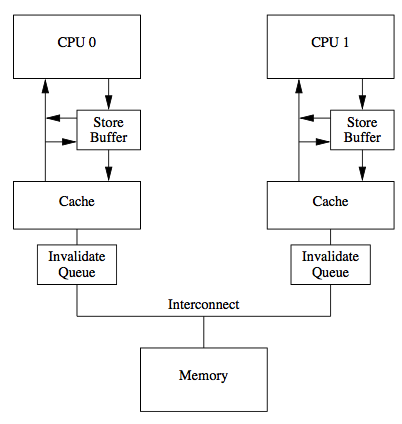
并且,缓存一拿就是一个缓存行(cache line),这个innodb 一读就是一个page 是一样的。
-
实际上无锁的代码仅仅是不需要显式的Mutex来完成,但是存在数据竞争(Data Races)的情况下也会涉及到同步(Synchronization)的问题。从某种意义上来讲,所谓的无锁,仅仅只是颗粒度特别小的“锁”罢了,从代码层面上逐渐降低级别到CPU的指令级别而已,总会在某个层级上付出等待的代价,除非逻辑上彼此完全无关
回到笔者常问的一个面试问题:volatile int 修饰的 i++ 线程安全么?
- 加了volatile 也不安全,因为 i++ 不是原子操作
- 那么 使用cas(i,i+1),因为cas 是原子操作
volatile 满足了可见性和有序性,cas 满足原子性,三个条件满足,则认为是线程安全的。
所以,我们要线程安全的修改 一个变量的值,有两种方法
- 加一个锁,计算机内置的实现了 线程安全的读写锁变量并阻塞线程
- 满足三个基本特性来操作变量
一个博客系列的整理
并发的核心:
- 一个是有序性,可见性,原子性. 从底层角度, 指令重排和内存屏障,CPU的内存模型的理解.
- 另一个是线程的管理, 阻塞, 唤醒, 相关的线程队列管理(内核空间或用户空间)
并发相关的知识栈
- 硬件只是、cpu cache等
- 指令重排序、内存屏障,cpu 内存模型等
- x86_64 相关的指令:lock、cas等
- linux 进程/线程的实现,提供的快速同步/互斥机制 futex(fast userspace muTeXes)
- 并发基础原语 pthread_mutex/pthread_cond 在 glibc 的实现。这是C++ 的实现基础
- java 内存模型,java 并发基础原语 在 jvm hotspot 上的实现
- java.util.concurrent
从中可以看到
- 内存模型,有cpu 层次的,java 层次的
- 并发原语,有cpu 层次的,linux 层次的,glibc/c++ 层次的,java 层次的。 首先cpu 层次根本没有 并发的概念,限定的是cpu 核心。glibc 限定的是pthread,java 限定的是Thread
所有这一切,讲的都是共享内存模式的并发。 所以 go 的协程让程序猿 少学多少东西。
- Why wait(), notify(), notifyAll() must be called inside a synchronized method/block?
- 粗略的说,monitor = lock + entry list(新进来的线程发现锁被占用,进来排队) + wait list(线程发现自己缺点啥东西,主动掉wait,进入该队列)
-
object.wait =
- 将线程 放入wait list 用户空间
- 释放锁 用户空间
- 前两步代码中 涉及到 OrderAccess 等,估计是限定指令重排序的
- pthread_cond_wait 进入内核空间
- linux futex 系统调用 一个新的同步机制,了解下。
- switch_to 线程A中执行switch_to,则linux 保存上下文,执行其它线程。相当于让出cpu 的效果
[并发系列-2] 为什么要有Condition Variable?
- 为什么有了mutex,还需要condition? mutex 是保护资源的,condition 是限定 线程执行顺序的
- 为什么condition 要跟锁一起用?但“判断条件,加入休息队列”两个操作之间,consumer 前脚刚判断没啥消费,还没加入呢,producer生产了一个产品,notify了一下,这就尴尬了(学名就是:条件变量的 判断过程 不能有data racing(数据竞争))。
[并发系列-3] 从AQS到futex(一): AQS和LockSupport
aqs 包括两个队列,同步队列和wait队列,这点和synchronized实现基本是一致的。
AQS/同步器的基本构成,第一和第三jvm/java层处理,第二个委托os层处理
- 同步状态(原子性);
- 线程的阻塞与解除阻塞(block/unblock);
- 队列的管理;
[并发系列-4] 从AQS到futex(二): HotSpot的JavaThread和Parker
JDK中的LockSupport只是用来block(park,阻塞)/unblock(unpark,唤醒)线程, 线程队列的管理是JDK的AQS处理的. 从Java层来看, 只需要(glibc或os层)mutex/cond提供个操作系统的block/unblock API即可.
[并发系列-5] 从AQS到futex(三): glibc(NPTL)的mutex/cond实现
[并发系列-6] 从AQS到futex(四): Futex/Critical Section介绍
aqs 作者关于aqs的论文The java.util.concurrent Synchronizer Framework 中文版 The j.u.c Synchronizer Framework翻译(一)背景与需求
文章从AQS到HotSpot, 再到glibc, 最后到内核的futex. 纵向一条线深入下来, 粗略地了解下各个层次的实现。小结起来,有以下几个点:
- 同步器的基本概念及基本组成
-
各平台(glibc、java)为效率考虑,并未直接使用内核提供的同步机制。都试图将同步器的一部分放在自己语言层面,另一部分交给内核。java 既不用glibc的,也不用内核的。
- 内核陷入成本较高,cas的成本都有人嫌高
- 很多时候,竞争状态不是很剧烈,一些简单的check 操作就省去了block 的必要
- 内核提供的接口功能不够丰富,比如block 时间、可中断等等
- aqs 维护一个同步状态值,线程的block 依靠glibc/内核,block 操作本质上是靠内核的mutex等实现,但此时,内核mutex 状态值跟 aqs的状态值就不是一个意思了。内核 mutex 的状态值单纯的标记了是否被占用。同步相关的 waiting list 和 mutet 的队列 含义也不同。
类似的底层已实现的能力不用,非要亲自实现一下的情况:linux 内核中,semaphore = 自旋锁 + 线程挂起/恢复,自旋锁通过自旋 也有 线程挂起的效果,但semaphore 只用自旋锁保护 count 变量设置的安全性,挂起的效果自己实现。为何呀?也是嫌spinlock_t 代价太高。
struct semaphore{
spinlock_t lock;
unsigned int count;
struct list_head wait_list;
}
futex
#include <linux/futex.h>
#include <sys/time.h>
int futex (int *uaddr, int op, int val, const struct timespec *timeout,int *uaddr2, int val3);
#define __NR_futex 240 // 系统调用号
- uaddr,用户态下共享内存的地址,里面存放的是一个对齐的整型计数器 参见futex 原理
- op:存放着操作类型,如最基本的两种 FUTEX_WAIT和FUTEX_WAKE。
-
具体含义由操作类型op决定
- FUTEX_WAKE 时,val 表示唤醒 val 个 等待在uaddr 上的进程
-
FUTEX_WAIT,原子性的检查 uaddr 计数器的值是否为 val
- 如果是,则让进程休眠,直到FUTEX_WAKE 或 timeout