前言
近来负责的项目,接到运维反馈的一个问题,mysql 并发过高,同时数据量较大,导致主库和从库同步延迟比较大。
因为当下sql 是一条一条发给sql的,性能较低,因此计划通过批量方式优化性能。
难点:
- 搞懂原理
- 尽最大可能减少对现有代码的更改
批量优化的原理
介绍MySQL Jdbc驱动的rewriteBatchedStatements参数 要点如下:
- MySQL Jdbc驱动在默认情况下会无视executeBatch
- 只有把rewriteBatchedStatements参数置为true, 驱动才会帮你批量执行SQL
jdbc:mysql://ip:port/db?rewriteBatchedStatements=true
如何批量执行呢?
未打开rewriteBatchedStatements时,根据wireshark嗅探出的mysql报文可以看出,
batchDelete(10条记录) => 发送10次delete 请求
batchUpdate(10条记录) => 发送10次update 请求
batchInsert(10条记录) => 发送10次insert 请求
打开rewriteBatchedStatements后,根据wireshark嗅探出的mysql报文可以看出
batchDelete(10条记录) => 发送一次请求,内容为”delete from t where id = 1; delete from t where id = 2; delete from t where id = 3; ….”
batchUpdate(10条记录) => 发送一次请求,内容为”update t set … where id = 1; update t set … where id = 2; update t set … where id = 3 …”
batchInsert(10条记录) => 发送一次请求,内容为”insert into t (…) values (…) , (…), (…)”
对delete和update,驱动所做的事就是把多条sql语句累积起来再一次性发出去;而对于insert,驱动则会把多条sql语句重写成一条风格很酷的sql语句,然后再发出去。 官方文档说,这种insert写法可以提高性能(”This is considerably faster (many times faster in some cases) than using separate single-row INSERT statements”)
代码方案
- sql 层面上,使用case
- java 代码层面上,executeBatch
- jdbc driver 层面上 加 rewriteBatchedStatements 参数
- jdbc framework 层面使用 batch 机制
jdbc
jdbc 原生代码的 批量执行
// Create statement object
Statement stmt = conn.createStatement();
// Set auto-commit to false
conn.setAutoCommit(false);
// Create SQL statement
String SQL = "INSERT INTO Employees (id, first, last, age) " +
"VALUES(200,'Zia', 'Ali', 30)";
// Add above SQL statement in the batch.
stmt.addBatch(SQL);
// Create one more SQL statement
String SQL = "INSERT INTO Employees (id, first, last, age) " +
"VALUES(201,'Raj', 'Kumar', 35)";
// Add above SQL statement in the batch.
stmt.addBatch(SQL);
// Create one more SQL statement
String SQL = "UPDATE Employees SET age = 35 " +
"WHERE id = 100";
// Add above SQL statement in the batch.
stmt.addBatch(SQL);
// Create an int[] to hold returned values
int[] count = stmt.executeBatch();
//Explicitly commit statements to apply changes
conn.commit();
ibatis
公司最早基于 ibatis 弄了一套数据访问 方面的代码生成工具,ibatis 虽老,但大部分时候够用。
Performing Batch processing with iBATIS and Spring
ibatis 两个核心类
SqlMapClient,由FactoryBean构建,传入sql文件地址及dataSource对象, 包括以下方法, SqlMapSession 负责实际的crud 操作
SqlMapSession openSession();SqlMapSession openSession(Connection var1);
/** @deprecated */
SqlMapSession getSession();
void flushDataCache();
void flushDataCache(String var1);
SqlMapClientTemplate的核心是T execute(SqlMapClientCallback<T> action) 方法,其基本逻辑是
- 获取SqlMapSession
- 选取java.sql.Connection,或者是SqlMapSession 或者 从spring context 中获取(以支持@Transactional 事务)
- 关联Connection 和 SqlMapSession
session.setUserConnection(springCon); - action.doInSqlMapClient(session)
- release connetion 和 close session
可以看到
- 其基本套路 跟jdbc 是一样一样的,只是SqlMapSession 封装了 sql 的获取的部分
- SqlMapClientCallback 在java 中就是一个 函数引用,execute 就是一个高阶函数
因此ibatis 提供 批量操作的思路 为
- dao 类中提供
int insertBatch(List<T> elements)方法 -
执行execute 方法,SqlMapClientCallback 中的逻辑 与jdbc 大致一样
getSqlMapClientTemplate().execute(new SqlMapClientCallback() { public Object doInSqlMapClient(SqlMapExecutor executor) throws SQLException { executor.startBatch(); executor.update("insertSomething", "myParamValue"); executor.update("insertSomethingElse", "myOtherParamValue"); executor.executeBatch(); return null; } });
mybatis
因此从代码上看,mybatis 相对 ibtatis 最大程度上屏蔽了 批量处理的 细节。
- foreach 标签
- ExecutorType.BATCH
自己实现一个框架
笔者尝试写了一个框架,在不影响代码逻辑的前提下,通过拦截 数据操作的执行,将sql 语句存储到 队列中。
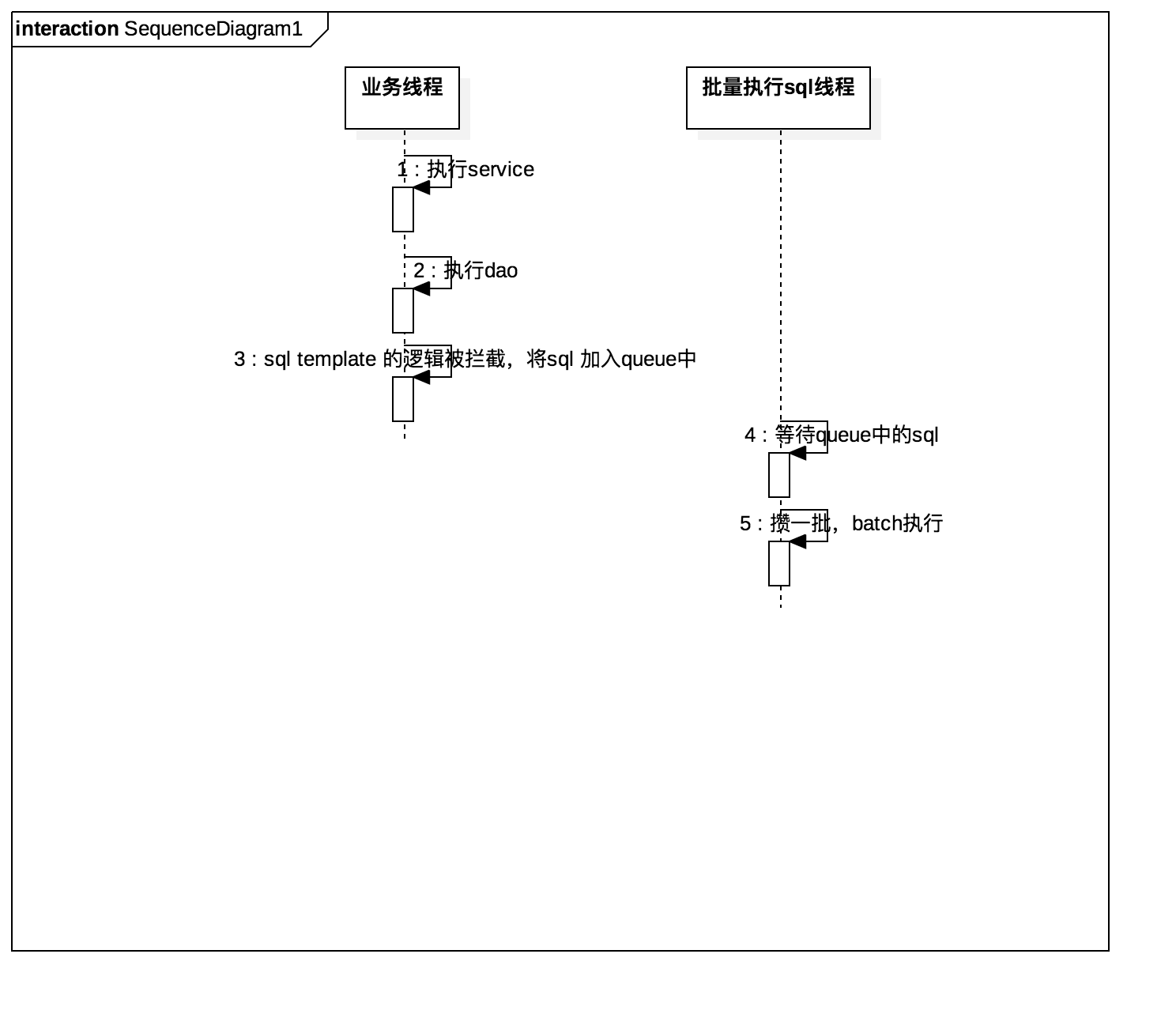
批量处理 分为整体批量和分类批量,缺点如下:
-
整体批量,即批量操作时,按原来的操作序列,可能insert、update、delete 交替进行,sql 语句也不一定都在一个表中。
- 不能使用事务
- 因为操作被延迟进行,所以db 操作无法立即反馈
-
分类批量,insert/update/delete 分类批量,除了继承整体批量的缺点外
- 操作序列的实际顺序 与 业务调用顺序 可能被打乱,会干扰业务逻辑的正确性
所谓的ibatis 批量,其基本原理(不准确):
- SqlMapExecutor.startBatch
- SqlMapExecutor.insert(sql), 为sql 创建 PreparedStatement,执行PreparedStatement.addBatch(sql),同一个Batch内有一个Batch 对象维护 PreparedStatement 列表
- SqlMapExecutor.insert(sql)
- SqlMapExecutor.executeBatch(); Batch 内的所有 PreparedStatement 执行 executeBatch
整体批量情况下,查看com.ibatis.sqlmap.engine.execution.SqlExecutor.Batch.addBatch(StatementScope statementScope, Connection conn, String sql, Object[] parameters) 代码可知,连续两次sql 不一样(参数不算)时,ibatis 会为 sql 创建新的 PreparedStatement,而批量 也是 在一个PreparedStatement内批量才有意义的。
也就是
ibatis batch start
PreparedStatement batch1 ==> sql1
PreparedStatement batch2 ==> sql2,sql3,sql4
PreparedStatement batch3 ==> sql5,sql6
ibatis batch end
若是要保持 业务调用 sql 的顺序,可以使用Statement,可以insert,update,delete 随便来,但相对PreparedStatement有可能会引起性能下降。
实践心得
- query 无需批量,insert 有时不能批量,因为某些场景下,先检查本地再插入,因为插入的延后,导致重复数据或唯一索引冲突。因此 通常对update/delete 批量,因为他们通常有where 条件,大多数时候延迟一点没关系
- 要处理 分库分表情况。事先按分表+insert/update/delete 对sql 分组
- 批量策略,批量阈值 + 间隔相结合,符合一个条件便立即处理累积数据。在条件都不符合前,重启项目对导致数据丢失。要么处理这种情况,要么批量阈值/间隔设置的小点
性能评估
如何评估 批量化操作之后,mysql的负载下降?是否可以最终解决主库与从库同步延迟大的问题?