简介
物质基础决定上层建筑,在计算机世界里,硬件作为“物质基础”深刻的影响着软件设计和性能。
国外一个大牛的博客 Mechanical Sympathy Hardware and software working together in harmony 讲的是底层硬件是如何运作的,以及与其协作而非相悖的编程方式。剖析Disruptor:为什么会这么快?(二)神奇的缓存行填充 作为一个开发者你可以逃避不去了解CPU、数据结构或者大O符号 —— 而我用了10年的职业生涯来忘记这些东西。但是现在看来,如果你知道这些知识并应用它,你能写出一些非常巧妙和非常快速的代码。
2019.4.12 补充:进程管理信息数据结构 二进制文件分段 ==> 进程分段 ==> 指令操作码/操作数 ==> cpu运算单元/数据单元 ==> cpu代码段寄存器/数据段寄存器/堆栈段寄存器等,从这个视角看,又有一种软硬件融合的味道。
为什么需要反码和补码
有界/越界/溢出与取模
在数学的理论中,数字可以有无穷大,也有无穷小。现实中的计算机系统不可能表示无穷大或者无穷小的数字,都有一个上限和下限。加法加越界了就成了 取模运算。
符号位
在实际的硬件系统中,**计算机 CPU 的运算器只实现了加法器88,而没有实现减法器。那么计算机如何做减法呢?我们可以通过加上一个负数来达到这个目的。如何让计算机理解哪些是正数,哪些是负数呢?人们把二进制数分为有符号数(signed)和无符号数(unsigned)。如果是有符号数,那么最高位就是符号位。如果是无符号数,那么最高位就不是符号位,而是二进制数字的一部分。有些编程语言,比如 Java,它所有和数字相关的数据类型都是有符号位的;而有些编程语言,比如 C 语言,它有诸如 unsigned int 这种无符号位的数据类型。
比取模更“狠”——有符号数的溢出
对于 n 位的数字类型,符号位是 1,后面 n-1 位全是 0,我们把这种情形表示为 -2^(n-1)。n 位数字的最大的正值,其符号位为 0,剩下的 n-1 位都1,再增大一个就变为了符号位为 1,剩下的 n-1 位都为0。也就是n位 有符号最大值 加1 就变成了 n位有符号数界限范围内最小的负数——上溢出之后,又从下限开始
是不是有点扑克牌的意思, A 可以作为10JQKA 的最大牌,也可以作为A23456 的最小牌。
| 下限 | 上限 | |
|---|---|---|
| n位无符号数 | 0 | 2^n-1 |
| n位有符号数 | -2^(n-1) | 2^(n-1)-1 |
取模 可以将(最大值+1) 变成下限值,对于无符号数是0 ,对于有符号数是负数。
减法靠补码
原码就是我们看到的二进制的原始表示,是不是可以直接使用负数的原码来进行减法计算呢?答案是否定的,因为负数的原码并不适用于减法操作(加负数操作)
因为取模的特性,我们知道 i = i + 模数。 那么 i-j = i-j + 模数 也是成立的,进而i-j = i + (模数 -j)。模数 -j 即补码 可以对应到计算机的 位取反 和 加 1 操作
本质就是
- 加法器不区分 符号位和数据位
- 越界 等于 取模,对于有符号位的取模,可以使得 正数 变成负数
我们经常使用朴素贝叶斯算法 过滤垃圾短信,P(A|B)=P(A) * P(B/A) / P(B) 这个公式在数学上平淡无奇,但工程价值在于:实践中右侧数据比 左侧数据更容易获得。 cpu减法器也是类似的道理,减法器 = CPU 位取反 + 加法器
CPU和内存
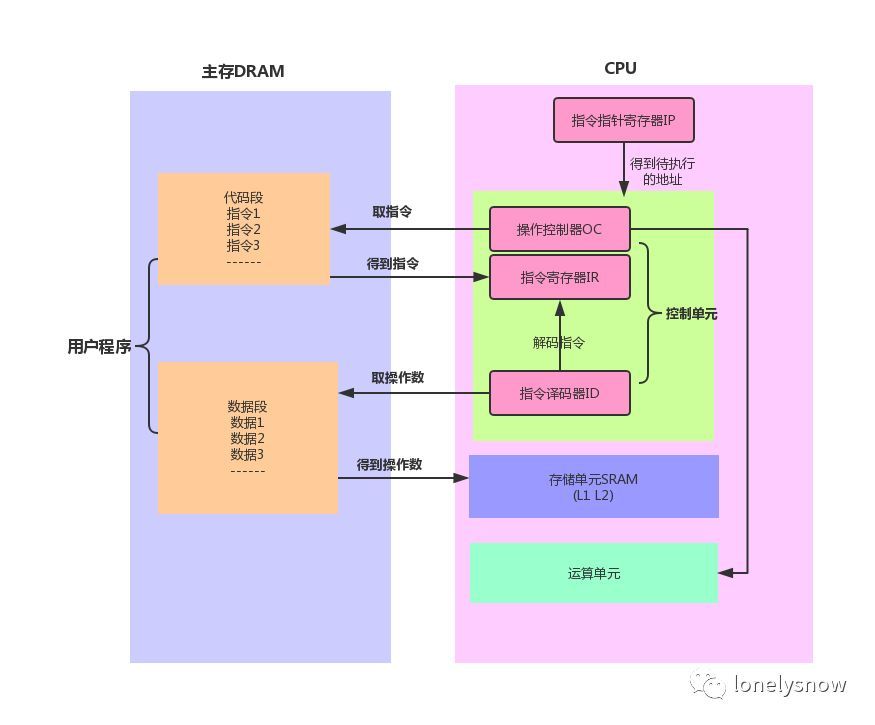
RAM 是随机访问内存,就是给一个地址就能访问到数据,而磁盘这种存储媒介必须顺序访问,而 RAM 又分为动态和静态两种,静态 RAM 由于集成度较低,一般容量小,速度快,而动态 RAM 集成度较高,主要通过给电容充电和放电实现,速度没有静态 RAM 快,所以一般将动态 RAM 做为主存,而静态 RAM 作为 CPU 和主存之间的高速缓存 (cache),用来屏蔽 CPU 和主存速度上的差异,也就是我们经常看到的 L1 , L2 缓存。每一级别缓存速度变低,容量变大。
CPU 的指令执行
为什么可以流水线/乱序执行?因为cpu 内部部件很多,负责不同的指令 ==> 不同指令可以并行执行。
取址,译码,执行,这是一个指令的执行过程,所有指令都会严格按照这个顺序执行,但是多个指令之间其实是可以并行的,对于单核 CPU 来说,同一时刻只能有一条指令能够占有执行单元运行,这里说的执行是 CPU 指令处理 (取指,译码,执行) 三步骤中的第三步,也就是运算单元的计算任务,所以为了提升 CPU 的指令处理速度,所以需要保证运算单元在执行前的准备工作都完成,这样运算单元就可以一直处于运算中,而刚刚的串行流程中,取指,解码的时候运算单元是空闲的,而且取指和解码如果没有命中高速缓存还需要从主存取,而主存的速度和 CPU 不在一个级别上,所以指令流水线 可以大大提高 CPU 的处理速度
缓存速度的差异
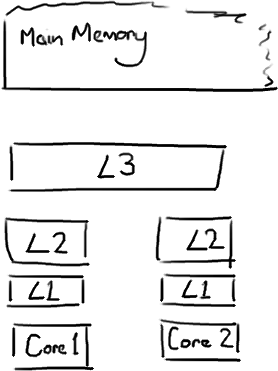
| 从CPU到 | 大约需要的 CPU 周期 | 大约需要的时间 |
|---|---|---|
| 主存 | 约60-80纳秒 | |
| QPI 总线传输(between sockets, not drawn) | 约20ns | |
| L3 cache | 约40-45 cycles, | 约15ns |
| L2 cache | 约10 cycles, | 约3ns |
| L1 cache | 约3-4 cycles, | 约1ns |
| 寄存器 | 1 cycle |
当CPU执行运算的时候,它先去L1查找所需的数据,再去L2,然后是L3,最后如果这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。如果你的目标是让端到端的延迟只有 10毫秒,而其中花80纳秒去主存拿一些未命中数据的过程将占很重的一块。如果你在做一些很频繁的事,你要确保数据在L1缓存中。
缓存的存取——缓存行
cpu和内存的速度差异 ==> 缓存 ==> 多级缓存 ==> Cache是由很多个cache line组成的。每个cache line通常是64字节,并且它有效地引用主内存中的一块儿地址。CPU每次从主存中拉取数据时,会把相邻的数据也存入同一个cache line。也就是说,假设一个cache line 对应内存地址是0x1000,存着一个volatile变量,你改了这个变量,那么跟它挨着的另一个变量(地址为0x1008)也会失效(假设它们同属于一个java对象内存结构,或都是某个数组的元素)因为整个cache line被标记为失效了。下次访问第二个变量时,便需要从内存中加载到缓存,再加载到cpu。从某种程度上可以说:cpu一直是批量访问缓存/内存的。
因此,缓存行中的64byte 数据,一个失效全失效,有时会带来一些性能问题。
JVM4——《深入拆解java 虚拟机》笔记 2018年07月20日因为 缓存行,jvm 使用了字段内存对齐机制。
volatile 字段和缓存行也有一番故事
多级缓存带来的问题
- 所谓线程 安全,最后可以归结到 并发读写 问题。参见 多线程
- 所谓数据结构,最后可以归结到 读写效率的 权衡问题。 参见hbase 泛谈 数据信息 和 结构信息(提高读写效率)混在一起,因为磁盘的缘故, 顺序写即可提高读效率。而查询/读效率 的提高花活儿就比较多了,并且通常 会降低写效率。
基于共享内存的数据通信问题从某种视角来看,共享内存模型下的并发问题都是“共享内存,但不共享寄存器/L1/L2缓存”导致的。
多级缓存问题的部分解决——内存屏障
Compiler 和 cpu 经常搞一些 optimizations,这种单线程视角下的优化在多线程环境下是不合时宜的,为此要用 memory barriers 来禁止 Compiler 和 cpu 搞这些小动作。 For purposes here, I assume that the compiler and the hardware don’t introduce funky optimizations (such as eliminating some “redundant” variable reads, a valid optimization under a single-thread assumption).
硬件为了加快速度,会弄各种缓存,然后就有一个缓存/副本一致性问题,也会定一些一致性规则(什么时候同步之类)。但基本就是,你不明确要求,硬件就当缓存是有效的。那么就有了打掉缓存的指令(即强制同步),然后编译器/runtime 支持该指令,最终反映在语言层面上。
Java和操作系统交互细节插入内存屏障的指令,会根据指令类型不同有不同的效果,例如在 monitorexit 释放锁后会强制刷新缓存,而 volatile 对应的内存屏障会在每次写入后强制刷新到主存,并且由于 volatile 字段的特性,编译器无法将其分配到寄存器,所以每次都是从主存读取,所以 volatile 适用于读多写少得场景
资源的有限性和需求的无限性
| 计算能力 | 需求 | 备注 | ||
|---|---|---|---|---|
| 软硬件 | cpu | 创建线程的业务是无限的 | 用一个数据结构 表示和存放你要执行的任务/线程/进程,任尓干着急,我调度系统按既有的节奏来。 | |
| java线程池 | 线程池管理的线程 | 要干的活儿是无限的 | 用一个runnable对象表示一个任务,线程池线程依次从队列中取出任务来执行 | 线程池管理的线程数可以扩大和缩小 |
| goroutine | goroutine调度器管理的线程 | 要干的活儿是无限的 | 用协程表示一个任务,线程从各自的队列里取出任务执行 | A线程干完了,还可以偷B线程队列的活儿干 |
为什么会有人觉得优化没有必要,因为他们不理解有多耗时
Teach Yourself Programming in Ten Years
Remember that there is a “computer” in “computer science”. Know how long it takes your computer to execute an instruction, fetch a word from memory (with and without a cache miss), read consecutive words from disk, and seek to a new location on disk.
Approximate timing for various operations on a typical PC:
| 耗时 | |
|---|---|
| execute typical instruction | 1/1,000,000,000 sec = 1 nanosec |
| fetch from L1 cache memory | 0.5 nanosec |
| branch misprediction | 5 nanosec |
| fetch from L2 cache memory | 7 nanosec |
| Mutex lock/unlock | 25 nanosec |
| fetch from main memory | 100 nanosec |
| send 2K bytes over 1Gbps network | 20,000 nanosec |
| read 1MB sequentially from memory | 250,000 nanosec |
| fetch from new disk location (seek) | 8,000,000 nanosec |
| read 1MB sequentially from disk | 20,000,000 nanosec |
| send packet US to Europe and back | 150 milliseconds = 150,000,000 nanosec |
| 上下文切换 | 数千个CPU时钟周期,1微秒 |
线程切换的成本
不仅创建线程的代价高,线程切换的开销也很高
- 线程切换只能在内核态完成,如果当前用户处于用户态,则必然引起用户态与内核态的切换。
- 上下文切换,前面说线程信息需要用一个task_struct保存,线程切换时,必然需要将旧线程的task_struct从内核切出,将新线程的切入,带来上下文切换。除此之外,还需要切换寄存器、程序计数器、线程栈(包括操作栈、数据栈)等。2019.03.22补充:《反应式设计模式》尽管CPU已经越来越快,但更多的内部状态已经抵消了纯执行速度上带来的进步,使得上下文切换大约需要耗费1微秒的时间(数千个CPU时钟周期),这一点在二十年来几乎没有大的改进。
- 执行线程调度算法,线程1放弃cpu ==> 线程调度算法找下一个线程 ==> 线程2
- 缓存缺失,切换线程,需要执行新逻辑。如果二者的访问的地址空间不相近,则会引起缓存缺失。 PS “进程切换”的代价更大巨大,linux线程切换和进程切换当你改变虚拟内存空间的时候,处理的页表缓冲(processor’s Translation Lookaside Buffer (TLB))或者相当的神马东西会被全部刷新,这将导致内存的访问在一段时间内相当的低效。
用户态与内核态切换有什么代价呢?
Understanding User and Kernel Mode
- 在操作系统中,In Kernel mode, the executing code has complete and unrestricted access to the underlying hardware. It can execute any CPU instruction and reference any memory address. 而用户态可以访问的指令和地址空间是受限的
- 用户态和内核态的切换通常涉及到内存的复制,比如内核态read 得到的数据返回给 用户态,因为用户态访问不了内核态的read 返回数据。
- jvm 则再插一腿,因为jvm 数据不仅在用户态,jvm 还希望数据是由jvm heap管理,所以对于read 操作来讲,数据从内核态 ==> 用户态 ==> jvm heap 经历了两次复制,netty 中允许使用堆外内存(对于linux来说,jvm heap和堆外内存都在进程的堆内存之内) 减少一次复制
- linux 和jvm 都可以使用 mmap来减少用户态和内核态的内存复制,但一是应用场景有限,二是代码复杂度提升了好多。
单核CPU技术瓶颈 ==> CPU 向多核发展 ==> 多台服务器
2019.3.28 补充
- 语言层面,golang协程、java9 支持反应式等
- 架构层面,全异步化、反应式架构、分布式计算
通过语言层、框架层提出新的模型,引导写出并行度高的代码