简介
阅读本文前,建议事先了解下
《Container-Networking-Docker-Kubernetes》笔记
计算机发送数据包的基本过程
-
如果要访问的目标IP跟自己是一个网段的(根据CIDR就可以判断出目标端IP和自己是否在一个网段内了),就不用经过网关了,先通过ARP协议获取目标端的MAC地址,源IP直接发送数据给目标端IP即可。
frame header frame body A mac B mac A ip B ip body 如何是一个局域网的, you can just send a packet with any random IP address on it, and as long as the MAC address is right it’ll get there.
-
如果访问的不是跟自己一个网段的,就会先发给网关(哪个网关由 The route table 确定),然后再由网关发送出去,网关就是路由器的一个网口,网关一般跟自己是在一个网段内的,通过ARP获得网关的mac地址,就可以发送出去了
frame header frame body A mac gateway mac A ip B ip body
主机路由对上述过程的影响
$ ip route
...
10.244.1.0/24 via 10.168.0.3 dev eth0
目的 IP 地址属于 10.244.1.0/24 网段的 IP 包,应该经过本机的 eth0 设备发出去(即:dev eth0);并且,它下一跳地址(next-hop)是 10.168.0.3(即:via 10.168.0.3)。
所谓下一跳地址就是:如果 IP 包从主机 A 发到主机 B,需要经过路由设备 X 的中转。那么 X 的 IP 地址就应该配置为主机 A 的下一跳地址。一旦A配置了下一跳地址,那么接下来,当 IP 包从网络层进入链路层封装成帧的时候,eth0 设备就会使用下一跳地址X_IP对应的 MAC 地址,作为该数据帧的目的 MAC 地址。
| frame header | frame body | |||
| A mac | X mac | A ip | B ip | body |
程序猿视角看网络提到:在一个网络数据包传输的过程中(跨网络+路由器),都是源/目标mac在变,源/目标ip都没变。
跨主机通信
there are two ways for Containers or VMs to communicate to each other.
- In Underlay network approach, VMs or Containers are directly exposed to host network. Bridge, macvlan and ipvlan network drivers are examples of this approach.
- In Overlay network approach, there is an additional level of encapsulation like VXLAN, NVGRE
Macvlan and IPvlan basicsBroadly, there are two ways for Containers or VMs to communicate to each other. In Underlay network approach, VMs or Containers are directly exposed to host network. Bridge, macvlan and ipvlan network drivers are examples of this approach. In Overlay network approach, there is an additional level of encapsulation like VXLAN, NVGRE between the Container/VM network and the underlay network.
A container networking overview“every container gets an IP” concept I was really confused and kind of concerned. How would this even work?! My computer only has one IP address! 平白无故变出那么多ip来,自然要玩很多花活儿
overlay 网络
建议参考下《Container-Networking-Docker-Kubernetes》笔记 一起学习
Flannel 支持三种后端实现,分别是: VXLAN;host-gw; UDP。而 UDP 模式,是 Flannel 项目最早支持的一种方式,却也是性能最差的一种方式。所以,这个模式目前已经被弃用。
我们在进行系统级编程的时候,有一个非常重要的优化原则,就是要减少用户态到内核态的切换次数,并且把核心的处理逻辑都放在内核态进行。这也是为什么,Flannel 后来支持的VXLAN 模式,逐渐成为了主流的容器网络方案的原因。用户态内核态的切换成本参见 os->c->java 多线程
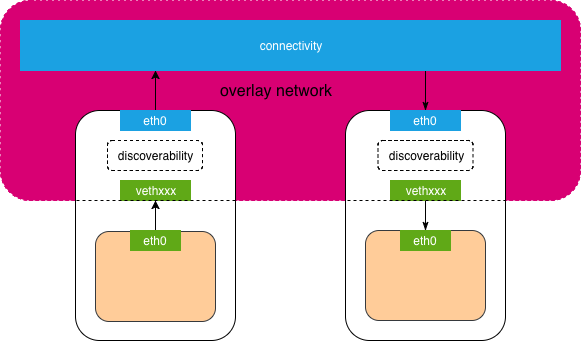
Network是一组可以相互通信的Endpoints,网络提供connectivity and discoverability(这句话是容器网络的纲,纲举目张). ip/mac 不是物理机独有的,主机内网络配置 (网卡 + iptables + 路由表 )加上网关,加上协议,就可以进行网络通信。
| 网络 | Endpoints | connectivity | discoverability |
|---|---|---|---|
| 物理机局域网络 | 物理机网卡 | 网线 + 交换机 | ARP广播,物理机内完成 |
| overlay 网络 | 容器 veth | 容器与宿主机network namespace连通,物理机连通 | 网络插件 + etcd,物理机内完成 |
这个 discoverability 宏观上有点微服务 服务发现的意思。
我们找一下覆盖网络的感觉
- 容器网卡不能直接发送/接收数据,而要通过宿主机网卡发送/接收数据
- 根据第一点,无论overlay 网络的所有方案,交换机都无法感知到容器的mac地址
基于上述两点,容器内数据包从发送方的角度看,无法直接用目标容器mac发送,便需要先发到目标容器所在的宿主机上。于是:
- overlay 网络主要有隧道 和 路由两种方式,无论哪种方式,“容器在哪个主机上“ 这个信息都必须专门维护
- 容器内数据包必须先发送目标容器所在的宿主机上,那么容器内原生的数据包便要进行改造(解封包或根据路由更改目标mac)
- 数据包到达目标宿主机上之后,目标宿主机要进行一定的操作转发到目标容器。
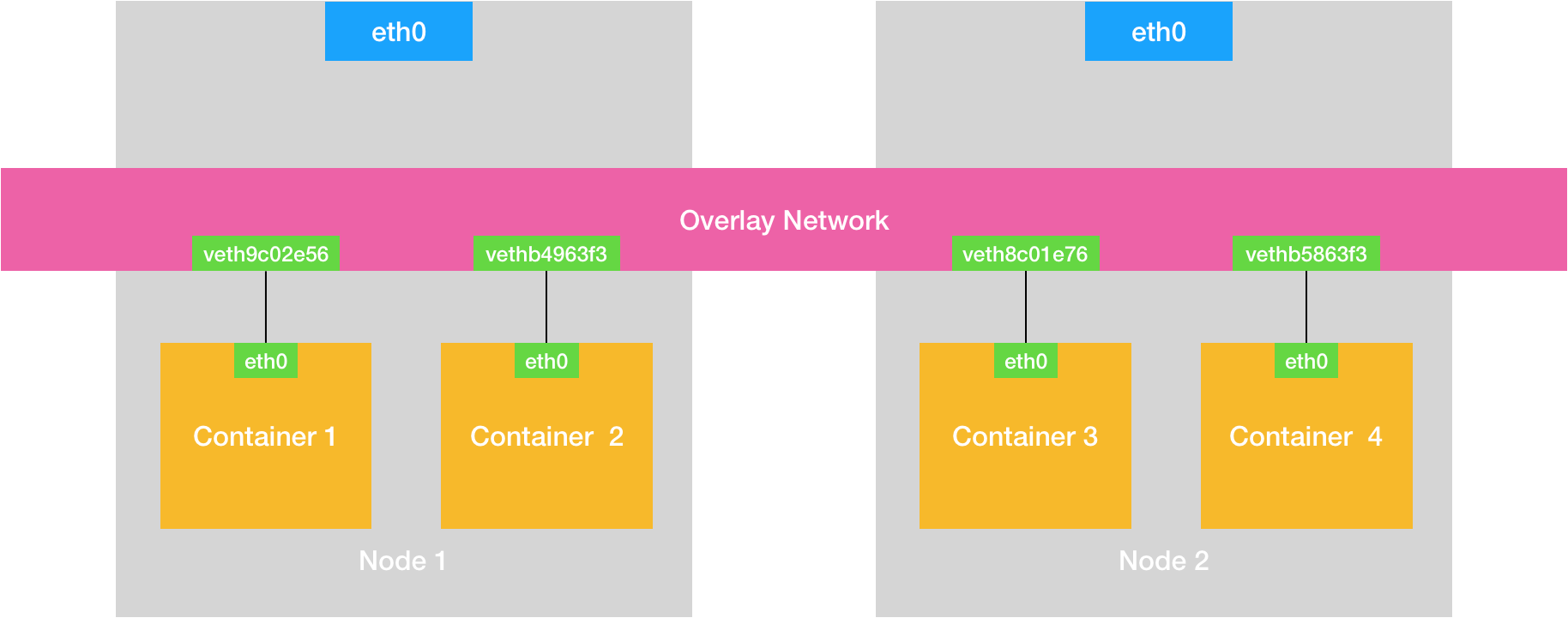
覆盖网络如何解决connectivity and discoverability?connectivity由物理机之间解决,discoverability由veth 与 宿主机eth 之间解决,将上图细化一下
有时觉得物理机内部 容器的veth 与 宿主机的eth0 之间塞个网桥、vtep、tun0 等虚拟设备 + 路由表等很复杂,但真实的网络世界,也不是一个交换机解决所有的问题。在数据中心网络中,什么三层交换机、二层交换机,交换机的搭配也是一门很深的学问。
隧道
隧道一般用到了解封包,那么问题来了,谁来解封包?怎么解封包?
| overlay network | 包格式 | 解封包设备 | 要求 |
|---|---|---|---|
| flannel + udp | ip数据包 package | flanneld 更新路由 + tun 解封包 | 宿主机三层连通 |
| flannel + vxlan | 二层数据帧 Ethernet frame | flanneld 更新路由 + VTEP解封包 | 宿主机二层互通 |
| calico + ipip | ip数据包 package | bgp 更新路由 + tunl0 解封包 | 宿主机三层连通 |
flannel + udp 和flannel + vxlan 有一个共性,那就是用户的容器都连接在 docker0网桥上。而网络插件则在宿主机上创建了一个特殊的设备(UDP 模式创建的是 TUN 设备,VXLAN 模式创建的则是 VTEP 设备),docker0 与这个设备之间,通过 IP 转发(路由表)进行协作。然后,网络插件真正要做的事情,则是通过某种方法,把不同宿主机上的特殊设备连通,从而达到容器跨主机通信的目的。
VTEP 等内核实现的设备 ,包括vlan、vxlan 等内核实现的机制、协议,其实与一般的网卡、网络协议栈、arp等是一样一样的,只是前者太基础了,进了课本,后者还比较新而已。
路由
路由方案的关键是谁来路由?路由信息怎么感知?
| overlay network | 路由设备 | 路由更新 | 要求 |
|---|---|---|---|
| flannel + host-gw | 宿主机 | flanneld | 宿主机二层连通 |
| calico + Node-to-Node Mesh | 宿主机 | bgp 更新路由 | 宿主机二层连通 |
| calico + 网关bgp | 网关 | bgp 更新路由 | 宿主机三层连通 |
-
flannel + udp/flannel + vxlan(tcp数据包),udp 和tcp 数据包首部大致相同
frame header frame body host1 mac host2 mac container1 mac container2 mac container1 ip container1 ip body -
flannel + host-gw/calico
frame header frame body container1 mac host2 mac container1 ip container2 ip body
A container networking overview How do routes get distributed?
Every container networking thing to runs some kind of daemon program on every box which is in charge of adding routes to the route table.
There are two main ways they do it:
- the routes are in an etcd cluster, and the program talks to the etcd cluster to figure out which routes to set
- use the BGP protocol to gossip to each other about routes, and a daemon (BIRD) listens for BGP messages on every box
underlay/physical 网络
| 容器的网卡 来自哪里? | 真正与外界通信的网卡是哪个? external connectivity | 容器与物理机网卡的关系及数据连通 | |
|---|---|---|---|
| bridge | veth | 物理机网卡 | veth pair 挂在bridge上,NAT 连通 物理机网卡 |
| macvlan | macvlan sub-interfaces | macvlan sub-interfaces | |
| ipvlan | ipvlan sub-interfaces | ipvlan sub-interfaces |
这个归类不好做,有好几个方面:
- 支持量级的大小
- 拆封包还是路由
- 交换机是否有感知
- 容器所在物理机/宿主机处于一个什么样的角色
- 是一个L3方案(只要物理机来通就行)还是L2方案,L3网络扩展和提供在过滤和隔离网络流量方面的细粒度控制。
- 选择网络时,IP地址管理IPAM,组播,广播,IPv6,负载均衡,服务发现,策略,服务质量,高级过滤和性能都是需要额外考虑的。问题是这些能力是否受到支持。即使您的runtime,编排引擎或插件支持容器网络功能,您的基础架构也可能不支持该功能
网络隔离
Kubernetes 对 Pod 进行“隔离”的手段,即:NetworkPolicy,NetworkPolicy 实际上只是宿主机上的一系列 iptables 规则。
在具体实现上,凡是支持 NetworkPolicy 的 CNI 网络插件,都维护着一个 NetworkPolicy Controller,通过控制循环的方式对 NetworkPolicy 对象的增删改查做出响应,然后在宿主机上完成 iptables 规则的配置工作。
个人微信订阅号
