简介
kafka 官方需求 Kafka Improvement Proposals KIP-349: Priorities for Source Topics
背景,我们希望kafka 可以支持“优先级”特性:即便队列里已经有了很多消息,但是高优先级消息可以“插队”进而立即被消费。自然地,在kafka 的概念里,我们建立多个topic,一个topic代表一个优先级,每个consumer 有一个或多个consumer(下文统一简化为一个consumer),那么难点就转换为“如何对 不同优先级的consumer 进行封装处理”了。
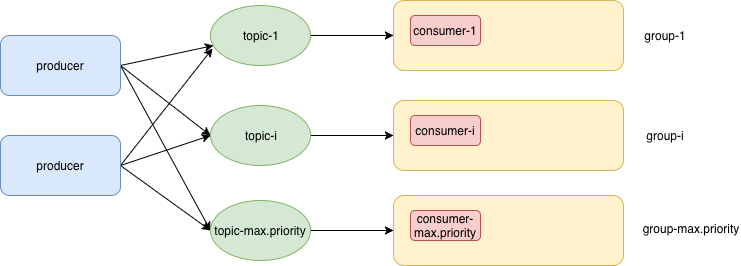
- 优先级以数字表示,值越高优先级越高
- 一个topic 对应有一个优先级,对应一个consumer
内部使用优先级队列重新缓冲
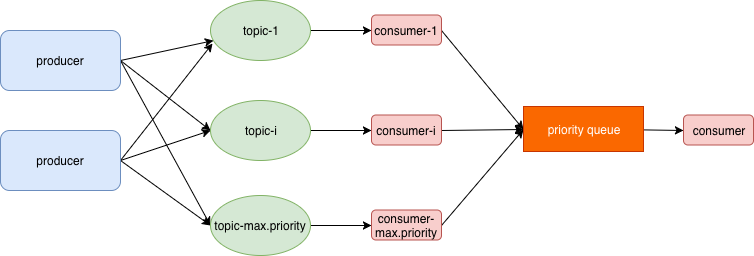
java 自带的PriorityBlockingQueue 无界队列,如果消费者消费速速不够快的话,“波峰”涌入,可能会导致内存OOM,因此要使用有界优先级阻塞队列。
对于 有界优先级阻塞队列 ,存在的风险
- 如果consumer 消费速度不够快,则priority queue 大部分时间处于满的状态,进而堵塞
- priority queue 可以保证 已经插入的消息 按照priority 排队,但不能保证阻塞的几个插入方按优先级插入。
优先级从高到低依次拉取,优先级越高拉取“配额”越大
下文主要来自对flipkart-incubator/priority-kafka-client的源码分析


This client provides abstraction to implement Kafka’s Producer<K, V> and Consumer<K, V> with priority support. PriorityKafkaProducer 和 CapacityBurstPriorityKafkaConsumer 只是聚合了KafkaProducer 和 KafkaConsumer成员 ,其本身仍符合KafkaProducer 和 KafkaConsumer 接口
CapacityBurstPriorityKafkaConsumer 的类描述
- regulates(管理、控制) capacity (record processing rate) across priority levels. 跨优先级管控 记录消费速度
- When we discuss about priority topic XYZ and consumer group ABC, here XYZ and ABC are the logical names. For every logical priority topic XYZ one must define max supported priority level via the config ClientConfigs#MAX_PRIORITY_CONFIG property.This property is used as the capacity lever(杠杆) for tuning(调音、调谐) processing rate across priorities. Every object of the class maintains KafkaConsumer instance for every priority level topic [0, ${max.priority - 1}].
循环拉取
CapacityBurstPriorityKafkaConsumer聚合多个优先级的consumer,先不考虑优先级,循环拉取逻辑如下:
// 同时维护多个consumer
private Map<Integer, KafkaConsumer<K, V>> consumers;
public ConsumerRecords<K, V> poll(long pollTimeoutMs) {
Map<TopicPartition, List<ConsumerRecord<K, V>>> consumerRecords =
new HashMap<TopicPartition, List<ConsumerRecord<K, V>>>();
long start = System.currentTimeMillis();
do {
// 每一次整体“拉取”,都调用每个“子”consumer 拉取一次
for (int i = maxPriority - 1; i >= 0; --i) {
ConsumerRecords<K, V> records = consumers.get(i).poll(0);
for (TopicPartition partition : records.partitions()) {
consumerRecords.put(partition, records.records(partition));
}
}
} while (consumerRecords.isEmpty() && System.currentTimeMillis() < (start + pollTimeoutMs));
...
}
从上述代码可以看到, 单纯的循环拉取,只是做到了一次循环范围内先消费优先级高的,再消费优先级低的。消费次序有高低之分,但消费机会是均等的,无法做到当高中低都有消息待消费时,集中全力先消费高优先级的消息。
设定一次拉取多少个
// CapacityBurstPriorityKafkaConsumer.java
void updateMaxPollRecords(KafkaConsumer<K, V> consumer, int maxPollRecords) {
try {
Field fetcherField = org.apache.kafka.clients.consumer.KafkaConsumer.class.getDeclaredField(FETCHER_FIELD);
fetcherField.setAccessible(true);
Fetcher fetcher = (Fetcher) fetcherField.get(consumer);
Field maxPollRecordsField = Fetcher.class.getDeclaredField(MAX_POLL_RECORDS_FIELD);
maxPollRecordsField.setAccessible(true);
maxPollRecordsField.set(fetcher, maxPollRecords);
} catch (Exception e) {
throw new IllegalStateException(e);
}
}
KafkaConsumer 包括fetcher 成员,通过设置fetcher.maxPollRecords 可以让consumers.poll(0) 受控的拉取fetcher.maxPollRecords 个消息
ConsumerRecords<K, V> Consumer.poll(long pollTimeoutMs)指明线程如果没有数据时等待多长时间,0表示不等待立即返回。fetcher.maxPollRecords控制一个poll()调用返回的记录数,这个可以用来控制应用在拉取循环中的处理数据量。
一次拉取多少, 如何在各个优先级之间分配
CapacityBurstPriorityKafkaConsumer 配置
| Config | Mandatory | Description |
|---|---|---|
| max.priority | Yes | Defines max priority |
| group.id | Yes | Defines logical group ID for the consumer |
| max.poll.records | Yes | Defines max records to be polled across priority levels |
| max.poll.history.window.size | No | This is window length to track historical counts of records obtained from poll(). Defaulted to 6 |
| min.poll.window.maxout.threshold | No | This is threshold on how many historical counts os records obtained from poll() maxed out w.r.t. max.poll.records config. Defaulted to 4 |
Rest of the configs are similar to that of KafkaConsumer. |
CapacityBurstPriorityKafkaConsumer.poll 一次可以拉取的记录数由max.poll.records 配置,max.poll.recordsproperty is split across priority topic consumers based on maxPollRecordsDistributor - defaulted to ExpMaxPollRecordsDistributor. max.poll.records 按一定算法 split 分摊给 各个consumer
Map<Integer, Integer> ExpMaxPollRecordsDistributor.distribution(maxPriority,maxPollRecords) 假设输入是 3,50 则输出为{2=29, 1=14, 0=7}
- 一共50个“名额”,3个优先级,优先级越高分的越多
- 一种分配方式是指数分配(Exponential distribution of maxPollRecords across all priorities (upto maxPriority)),即高一个优先级的“配额”是低一个优先级“配额”的2倍。当然,你也可以选择 高一个优先级的“配额”比低一个优先级的多1个。
根据实际情况调整配额
For example say we have:
max.priority = 3;
max.poll.records = 50;
maxPollRecordsDistributor = ExpMaxPollRecordsDistributor.instance();
max.poll.history.window.size = 6; // 窗口长度
min.poll.window.maxout.threshold = 4;
以上述配置为例, 3个优先级总额50的流量 分配是{2=29, 1=14, 0=7} ,你规定了配额,但上游的消息大多数时候都不是按配额 进来的。比如,你给priority=2 的“流量”最高,但如果 priority=2 的消息量一直不多,此时就应该多给priority=1/0 多一些被消费的机会。
Case 1: FIFO view of poll window is
2 - [29, 29, 29, 29, 29, 29]; //近6次循环实际读取的数据量
1 - [14, 14, 14, 14, 14, 14];
0 - [7, 7, 7, 7, 7, 7];
In this case every priority level topic consumer will retain its
capacity and not burst as everyone is eligible to burst but no
one is ready to give away reserved capacity.
理想状态,上游消息 一直按配额 发送
Case 2: FIFO view of poll window is
2 - [29, 29, 29, 29, 29, 29];
1 - [14, 14, 14, 11, 10, 9];
0 - [7, 7, 7, 7, 7, 7];
In this case every priority level topic consumer will retain its
capacity and not burst as everyone is eligible to burst but no
one is ready to give away(赠送) reserved capacity.
priority=2和priority=0 按配额发送,priority=1 有点“后劲不足”。但因为 priority=1 在min.poll.window.maxout.threshold = 4 的范围内 最大消息量仍是14,所以“按兵不动”再等等看
Case 3: FIFO view of poll window is
2 - [29, 29, 29, 29, 29, 29];
1 - [10, 10, 7, 10, 9, 0];
0 - [7, 7, 7, 7, 7, 7];
In this case priority level 2 topic consumer will burst into
priority level 1 topic consumer's capacity and steal (14 - 10 = 4),
hence increasing its capacity or max.poll.records property to
(29 + 4 = 33).
priority=2和priority=0 按配额发送, priority=1 在min.poll.window.maxout.threshold = 4 的范围内 最大实际读取数量10 低于配额,则其空出来的14-10 个配合给priority=2
Case 3: FIFO view of poll window is
2 - [20, 25, 25, 20, 15, 10];
1 - [10, 10, 7, 10, 9, 0];
0 - [7, 7, 7, 7, 7, 7];
In this case priority level 0 topic consumer will burst into
priority level 2 and 1 topic consumer capacities and steal
(29 - 25 = 4 and 14 - 10 = 4), hence increasing its capacity
or max.poll.records property to (7 + 8 = 15).
整个机制有点“自适应”的感觉,设定一个初始配额{2=29, 1=14, 0=7},然后根据实际拉取数量,校正下一次的配额(预定拉取数量)。