简介
synchronized关键字
在java5.0之前,使线程安全的执行临界区代码,会用到synchronized关键字,可以达到以下效果:
- 如果临界区没被其它线程占用,则执行代码。
- 如果临界区被占用,则阻塞当前线程。
那么问题来了,如何实现synchronized关键字的效果呢?
- 如何标记临界区被占用?
- 临界区被占用后,当前线程如何被阻塞?
- 临界区被释放后,如何通知被阻塞的线程?
- 很明显,我们需要一个存储被阻塞线程的数据结构,这个数据结构是什么样子的?
从Java中synchronized的实现原理与应用 聊聊并发(二)——Java SE1.6中的Synchronized 可以看到:
-
synchronized 实现中,无锁、偏向锁、轻量级锁、重量级锁(使用操作系统锁)。中间两种锁不是“锁”,而是一种机制,减少获得锁和释放锁带来的性能消耗。
- JVM中monitor enter和monitor exit字节码依赖于底层的操作系统的Mutex Lock来实现的,但是由于使用Mutex Lock需要将当前线程挂起并从用户态切换到内核态来执行,这种切换的代价是非常昂贵的。所以monitor enter的时候,多个心眼儿,看看能不能不走操作系统。
- 每一个线程都有一个可用monitor record列表,JVM中创建对象时会在对象前面加上两个字大小的对象头mark word。Mark Word最后3bit是状态位,根据不同的状态位Mark Word中存放不同的内容。有时存储当前占用的线程id,有时存储某个线程monitor record 的地址。
- 线程会根据自己获取锁的情况更改 mark word的状态位。mark word 状态位本质上反应了锁的竞争激烈程度。若一直是一个线程自嗨,mark word存一下线程id即可。若是两个线程虽说都访问,但没发生争抢,或者自旋一下就拿到了,则哪个线程占用对象,mark word就指向哪个线程的monitor record。若是线程争抢的很厉害,则只好走操作系统锁流程了。
为什么提出一种新的锁方案
java5.0之后有了新的接口Lock,提供了一种无条件的,可轮询的,定时的以及可中断的锁获取操作,所有加锁和解锁的方法都是显式的。为什么有了内置锁,还要提供一种新的加锁方式呢?
-
效率问题
- synchronized是通过MonitorEnter和MonitorExit专用字节码指令来实现。因为java线程是靠操作系统原生线程实现的,挂起线程还涉及到内核态与用户态的转换(还要劳烦OS介入)。加锁时,使用synchronized并不是高效的办法,其配套的同步手段wait和notify也不是(提高效率可用Condition,这不是本文的重点)。
- 在java.util.concurrent包中的一些方法通过结合使用Java代码和使用sun.misc.Unsafe的实现本地调用。这样,同步的大部分工作可以由JVM线程内部解决。
-
内置锁不够灵活,比如取消、设置进入临界区的线程数量等
比如内置锁无法中断一个正在获取锁的线程,(正在获取锁的线程)在得不到锁时会无限等待下去。而Lock接口可以为我们提供更丰富的选择。
public interface Lock {void lock(); void lockInterruptibly() throws InterruptedException; boolean tryLock(); boolean tryLock(long time, TimeUnit unit) throws InterruptedException; void unlock(); Condition newCondition(); }
锁与同步器Synchronizer的关系
java的并发,锁其中一个很重要的工具。同时,编写复杂的并发程序,仅用锁是远远不够的,还需Semaphore,CountDownLatch和FutureTask等。在锁和各种同步工具类背后,有一个“看不见的手”:AbstractQueuedSynchronizer。
借用AbstractQueuedSynchronizer的介绍和原理分析中的描述:锁的API是面向使用者的,它定义了与锁交互的公共行为。但锁的实现是依托给同步器来完成;同步器面向的是线程访问和资源控制,它定义了线程对资源是否能够获取以及线程的排队等操作。锁和同步器很好的隔离了二者所需要关注的领域,严格意义上讲,同步器可以适用于除了锁以外的其他同步设施上。
AbstractQueuedSynchronizer作为一个同步器,显式的处理了上节提到的几个问题。
AbstractQueuedSynchronizer
AbstractQueuedSynchronizer的java类介绍:
Provides a framework for implementing blocking locks and related synchronizers (semaphores, events, etc) that rely on first-in-first-out (FIFO) wait queues. This class is designed to be a useful basis for most kinds of synchronizers that rely on a single atomic value to represent state. Subclasses must define the protected methods that change this state, and which define what that state means in terms of this object being acquired or released. Given these, the other methods in this class carry out all queuing and blocking mechanics. Subclasses can maintain other state fields, but only the atomically updated value manipulated using methods , and is tracked with respect to synchronization.
可以看到,AbstractQueuedSynchronizer并没有包办一切(否则就不会以Abstract开头了),而是通过继承的方式将同步器的工作划分成两个部分,在父类和子类中分别完成。
共享变量的值,对于不同的子类意味着不同的状态
- 对于ReentrantLock,它是所有者线程已经重复获取该锁的次数
- Semaphore,它表示剩余的许可数量
- FutureTask,它表示任务的状态(尚未开始,正在运行,已完成以及已取消)
父类和子类的工作分别是
- 子类负责修改共享变量(a single atomic value to represent state),其操作必须是原子的(通过getState()、setState()和compareAndSetState()方法),根据返回值影响父类的行为(是否挂起当前线程,是否恢复被阻塞线程)。
- AbstractQueuedSynchronizer负责线程阻塞队列(FIFO)的维护,根据预留给子类的方法的返回值判断线程阻塞和唤醒(queuing and blocking mechanics)
AbstractQueuedSynchronizer留给子类实现的方法,一般以try开头,父类中对应的方法会调用这些方法。类似于操作系统的PV操作,或者说:我们在本文开始提到的synchronized一些问题,acquire和release基本是用来顶替wait和notify的。
-
排他模式
protected boolean tryAcquire(int arg) // 根据当前状态,是否挂起线程(获取操作,还会影响共享变量值) protected boolean tryRelease(int arg) // 新的状态,是否允许唤醒某个线程 protected boolean isHeldExclusively() -
共享模式(允许有限的多个线程同时进入临界区)
protected int tryAcquireShared(int arg) protected boolean tryReleaseShared(int arg)
一般情况下,在tryAcquire中判断state值,判断是否阻塞线程,如果阻塞,cas增加state值,在tryRelease减少state值。
AbstractQueuedSynchronizer实现类示例
在AQS框架下,我们可以自定义一个锁的实现
public class Mutex{
private final Sync sync = new Sync();
public void signal(){sync.releaseShared(0);}
public void await() throws InterruptedException{
sync.acquireShared(0);
}
private class Sync extends AbstractQueuedSynchronizer{
protected int tryAcquireShared(int ignored){
// 共享变量为1表示锁空闲,为0表示锁被占用
return (getState() == 1) ? 1 : -1;
}
protected boolean tryReleaseShared(int ignored){
setState(1);
return true;
}
}
}
Mutex是面向用户的,用户使用Mutext时只需mutex.await和mutex.signal即可。同步器面向的是线程访问和资源控制,使用时除调用acquire和release方法外,还要设置具体的参数值,为数据的变化赋予意义(此处参数是没用的)。
从锁及其它同步工具类中抽取出同步器,这在我们抽象自己的代码时,有很强的借鉴意义。
AbstractQueuedSynchronizer子类的实现比较丰富,除了提供类似pv操作。比如,如果为子类添加成员的话
static final class Sync<V> extends AbstractQueuedSynchronizer{
private V value;
private Throwable exception;
V get() throws xxxException;
boolean set(V v);
}
Sync<V> sync = new Sync<V>();
此处Sync就可以作为一个类的包装类,ThreadLocal用来做一个线程内(不同方法间)数据传递,此处Sync就可以作为线程间的数据传递。
从队列开始说起
说起队列,笔者的直接反应是“有一个数组,一前一后两个指针,入队出队通过移动指针来解决”(队列的存储结构基于数组方式)。AQS中的队列(并且是一个双向队列)采用链表作为存储结构,通过节点中的next指针维护队列的完整。AbstractQueuedSynchronizer关于队列操作的部分如下:
public abstract class AbstractQueuedSynchronizer{
private transient volatile Node head;
private transient volatile Node tail;
Node {
int waitStatus;
Node prev;
Node next;
Node nextWaiter;
Thread thread;
}
// 在队列尾部插入节点,中间一些操作用到CAS以保证原子性
private Node addWaiter(Node mode){}
// 将一个Node的相关指向置为空,并不再让其它节点指向它,即可(GC)释放该节点
}
AbstractQueuedSynchronizer.acquire和Object.wait对比
AbstractQueuedSynchronizer.acquire
在排他模式下,线程执行一次acquire所需要经历的过程
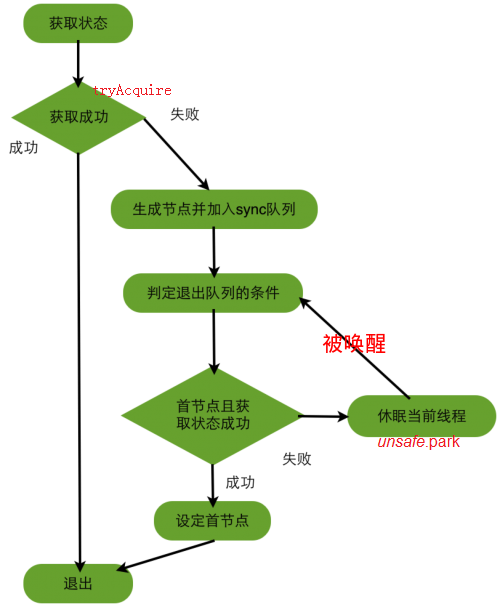
上图中的循环过程就是完成了自旋的过程,也正是有了这个循环,为支持超时和中断提供了条件。
判断退出队列的条件
- 当前线程对应队列节点是首节点。如果是,说明轮到自己了。
- 获取“状态”是否成功。如果是,说明上一个首节点已经“忙完了”
节点挂起后,何时被唤醒?前置(首)节点的release操作会唤醒当前节点。共享模式下,前置节点的唤醒也会间接唤醒当前节点。
AQS方法简介
AbstractQueuedSynchronizer支持多种工作模式及其组合,包括共享模式、排他模式、是否支持中断、是否超时等。
各个模式对应的方法如下(部分)
-
排他模式
public final void acquire(int arg) final boolean acquireQueued(final Node node, int arg) // 恢复锁的状态(“为0”),唤醒后继节点 public final boolean release(int arg) -
支持中断
// 每次“干活”前,先检查下当前线程的中断状态,如果当前线程被中断了,就放弃当前操作 public final void acquireInterruptibly(int arg) -
支持超时
// 每次“干活(循环)”前,先检查下剩余时间,在循环的最后更新下时间 public final boolean tryAcquireNanos(int arg, long nanosTimeout) -
共享模式
// 如果共享状态获取成功之后会判断后继节点是否是共享模式,如是就直接对其进行唤醒操作,也就是同时激发多个线程并发的运行。 public final void acquireShared(int arg) public final boolean releaseShared(int arg)
线程的阻塞和唤醒,使用LockSupport的park和unpark方法。