简介
本文主要聊一下 分布式系统(尤其指分布式计算系统)的 基本组成和理论问题
一个有意思的事情是现在已经不提倡使用Master-Slave 来指代这种主从关系了,毕竟 Slave 有奴隶的意思,在美国这种严禁种族歧视的国度,这种表述有点政治不正确了,所以目前大部分的系统都改成 Leader-Follower 了。
从哪里入手
有没有一个 知识体系/架构、描述方式,能将分布式的各类知识都汇总起来?当你碰到一个知识点,可以place it in context
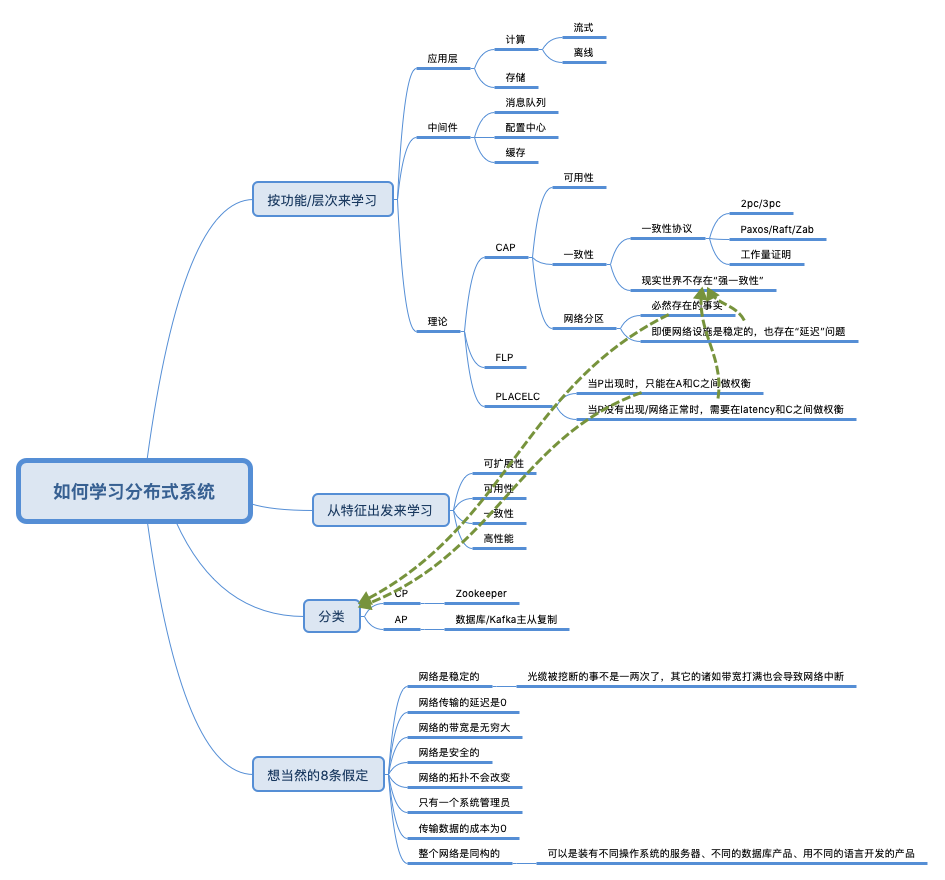
分布式学习最佳实践:从分布式系统的特征开始(附思维导图) 作者分享了“如何学习分布式系统”的探索历程, 深有体会。
当一个知识点很复杂时,如何学习它,也是一门学问
一个大型网站就是一个分布式系统,包含诸多组件,每一个组件也都是一个分布式系统,比如分布式存储就是一个分布式系统,消息队列就是一个分布式系统。
为什么说从思考分布式的特征出发,是一个可行的、系统的、循序渐进的学习方式呢?
- 先有问题,才会去思考解决问题的办法
- 解决一个问题,常常会引入新的问题。比如提高可用性 ==> 影响可用性的因素/冗余 ==> 一致性问题 ==> 可靠节点和不可靠节点的一致性问题
-
这是一个深度优先遍历的过程(按层次应该算广度优先遍历——知道所有组件,然后找共同点),在这个过程中我们始终知道
- 自己已经掌握了哪些知识;
- 还有哪些是已经知道,但未了解的知识;
- 哪些是空白
脑图来自作者
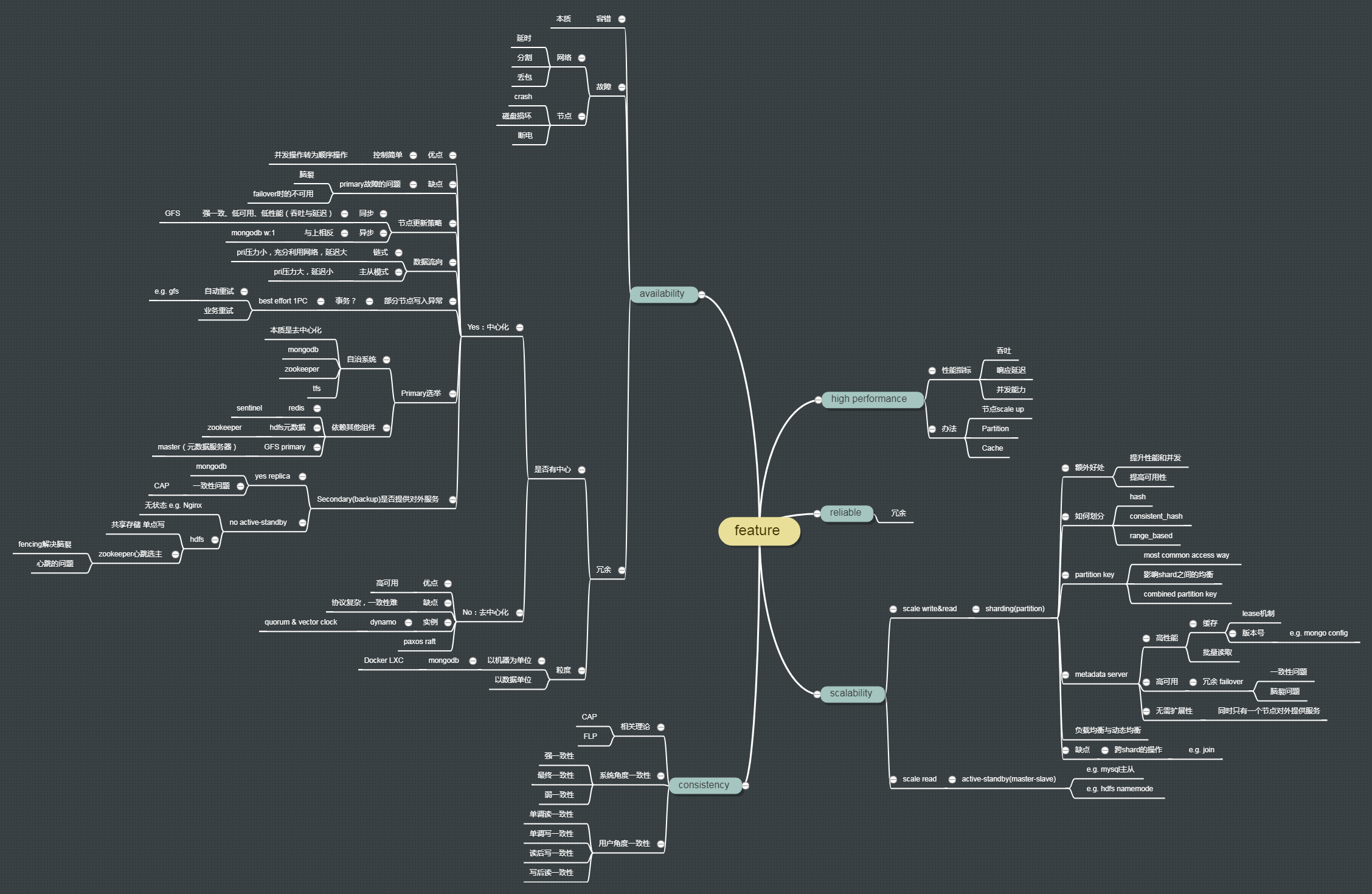
大咖文章
2018.11.25 补充 可能是讲分布式系统最到位的一篇文章回答了几个问题:
- “分布式系统”等于 SOA、ESB、微服务这些东西吗?
- “分布式系统”是各种中间件吗?中间件起到的是标准化的作用。中间件只是承载这些标准化想法的介质、工具,可以起到引导和约束的效果,以此起到大大降低系统复杂度和协作成本的作用。为了在软件系统的迭代过程中,避免将精力过多地花费在某个子功能下众多差异不大的选项中。
- 海市蜃楼般的“分布式系统”
我们先思考一下“软件”是什么。 软件的本质是一套代码,而代码只是一段文字,除了提供文字所表述的信息之外,本身无法“动”起来。但是,想让它“动”起来,使其能够完成一件我们指定的事情,前提是需要一个宿主来给予它生命。这个宿主就是计算机,它可以让代码变成一连串可执行的“动作”,然后通过数据这个“燃料”的触发,“动”起来。这个持续的活动过程,又被描述为一个运行中的“进程”。
所以,“单程序 + 单数据库”为什么也是分布式系统这个问题就很明白了。因为我们所编写的程序运行时所在的进程,和程序中使用到的数据库所在的进程,并不是同一个。也因此导致了,让这两个进程(系统)完成各自的部分,而后最终完成一件完整的事,变得不再像由单个个体独自完成这件事那么简单。所以,我们可以这么理解,涉及多个进程协作才能提供一个完整功能的系统就是“分布式系统”。
希望你在学习分布式系统的时候,不要因追逐“术”而丢了“道”。没有“道”只有“术”是空壳,最终会走火入魔,学得越多,会越混乱,到处都是矛盾和疑惑。
- 分治
- 冗余,为了提高可靠性
- 再连接,如何将拆分后的各个节点再次连接起来,从模式上来说,主要是去中心化与中心化之分。前者完全消除了中心节点故障带来的全盘出错的风险,却带来了更高的节点间协作成本。后者通过中心节点的集中式管理大大降低了协作成本,但是一旦中心节点故障则全盘出错。
不要沉迷与具体的算法
distributed-systems-theory-for-the-distributed-systems-engineer 文中提到:
My response of old might have been “well, here’s the FLP paper, and here’s the Paxos paper, and here’s the Byzantine generals(拜占庭将军) paper…”, and I’d have prescribed(嘱咐、规定) a laundry list of primary source material which would have taken at least six months to get through if you rushed. But I’ve come to thinking that recommending a ton of theoretical papers is often precisely the wrong way to go about learning distributed systems theory (unless you are in a PhD program). Papers are usually deep, usually complex, and require both serious study, and usually significant experience to glean(捡拾) their important contributions and to place them in context. What good is requiring that level of expertise of engineers?
也就是说,具体学习某一个分布式算法用处有限。一个很难理解,一个是你很难 place them in contex(它们在解决分布式问题中的作用)。
分布式系统不可能三角——CAP
以下来自对两个付费专栏的整理
左耳听风
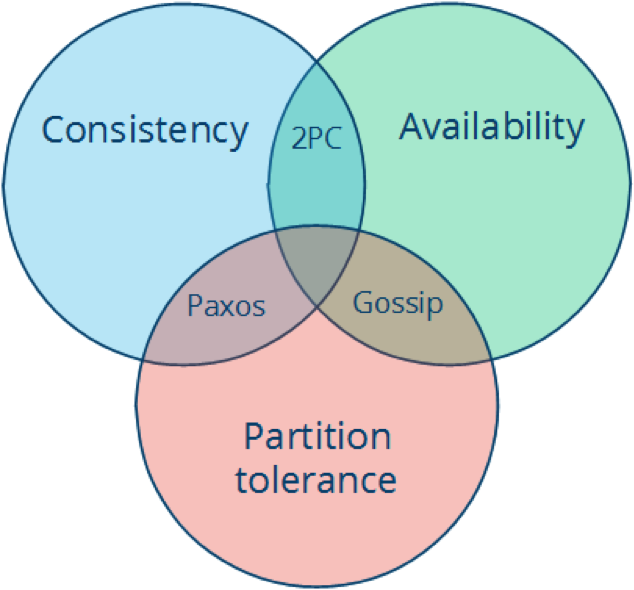
从0到1学架构
下文来自 李运华 极客时间中的付费专栏《从0到1学架构》。
Robert Greiner (http://robertgreiner.com/about/) 对CAP 的理解也经历了一个过程,他写了两篇文章来阐述CAP理论,第一篇被标记为outdated
| 第一版 | 第二版 | |
|---|---|---|
| 地址 | http://robertgreiner.com/2014/06/cap-theorem-explained/ | http://robertgreiner.com/2014/08/cap-theorem-revisited/ |
| 理论定义 | Any distributed system cannot guaranty C, A, and P simultaneously. | In a distributed system (a collection of interconnected nodes that share data.), you can only have two out of the following three guarantees across a write/read pair: Consistency, Availability, and Partition Tolerance - one of them must be sacrificed. |
| 中文 | 在一个分布式系统(指互相连接并共享数据的节点的集合)中,当涉及读写操作时,只能保证一致性(Consistence)、可用性(Availability)、分区容错性(Partition Tolerance)三者中的两个,另外一个必须被牺牲。 | |
| 一致性 | all nodes see the same data at the same time | A read is guaranteed to return the most recent write for a given client 总能读到 最新写入的新值 |
| 可用性 | Every request gets a response on success/failure | A non-failing node will return a reasonable response within a reasonable amount of time (no error or timeout) |
| 分区容忍性 | System continues to work despite message loss or partial failure | The system will continue to function when network partitions occur |
李运华 文中 关于Robert Greiner 两篇文章的对比 建议细读: 要点如下
- 不是所有的分布式系统都有 cap问题,必须interconnected 和 share data。比如一个简单的微服务系统 没有share data,便没有cap 问题。
- 强调了write/read pair 。这跟上一点是一脉相承的。cap 关注的是对数据的读写操作,而不是分布式系统的所有功能。
其它材料
从CAP理论到Paxos算法 基本要点:
- cap 着力点。网络分区是既成的现实,于是只能在可用性和一致性两者间做出选择。在工程上,我们关注的往往是如何在保持相对一致性的前提下,提高系统的可用性。
- 还是读写问题。多线程 提到,多线程本质是一个并发读写问题,数据库系统中,为了描述并发读写的安全程度,还提出了隔离性的概念。具体到cap 理论上,副本一致性本质是并发读写问题(A主机写入的数据,B主机多长时间可以读到)。2pc/3pc 本质解决的也是如此 ==> A主机写入的数据,成功与失败,B主机多长时间可以读到,然后决定自己的行为。