haproxy快速入门
前言
本文是关于我对haproxy的一些理解,将持续更新,如有错误和建议,请及时反馈到270235378@qq.com。具体的细节请参见官方文档 http://www.haproxy.org/
概述
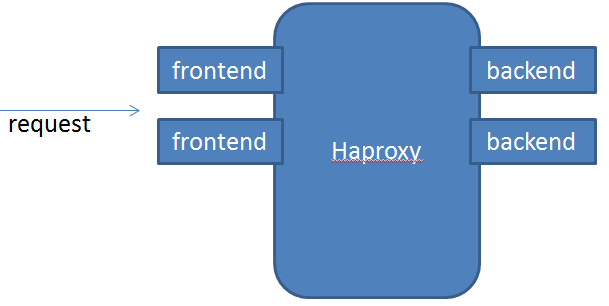
HAProxy是一款提供高可用性、负载均衡以及基于TCP(第四层)和HTTP(第七层)应用的代理软件,HAProxy是完全免费的、借助HAProxy可以快速并且可靠的提供基于TCP和HTTP应用的代理解决方案。
而我个人的理解是,haproxy会监听request请求的ip端口,负责将request映射到“后端”,同时做一些其它工作比如监控和记录日志等。而映射策略等,主要通过haproxy的配置文件进行配置。
安装
源码安装
-
准备
- linux
- haproxy-1.4.8.tar.gz download website http://www.haproxy.org/#down
-
安装过程
以安装到
/usr/local/下为例$ cd /usr/local $ cp ../haproxy-1.4.8.tar.gz . $ tar -zxvf haproxy-1.4.8.tar.gz $ cd haproxy-1.4.8 $ uname -a # check version of kernel $ make TARGET=linux26 PREFIX=/usr/local/haproxy #TARGET是内核版本,2.6就写作26 $ make install PREFIX=/usr/local/haproxy到/usr/local/haproxy/sbin目录下执行
haproxy,如果能够看到帮助代码,说明安装成功。
一个简单地小例子
我们先讲一个简单地例子,由此建立对haproxy的感性认识,然后讲述haproxy的一些配置。
环境
windows 下 virtualbox 虚拟三个redhat vm,这里分别记作node0,node1,node2。详情如下:
node0:haproxy 192.168.56.10
node1:httpd 192.168.56.101
node2:httpd 192.168.56.102
安装完毕后,为避免不必要的错误,请关闭防火墙。
node1和node2准备测试环境
此处以node1为例,node2操作类似
-
安装httpd
$ yum install -y httpd
-
提供测试文件
$ echo “node1.test.com” > /var/www/html/index.html
-
启动httpd服务
$ service httpd start
在node0上配置并运行haproxy
-
写haproxy的配置文件
$ cd /usr/local/haproxy $ mkdir conf $ cd conf $ vi haproxy.cfg global log 127.0.0.1 local2 info#定义日志 chroot /usr/local/haproxy #安全模式 pidfile /usr/local/haproxy/haproxy.pid #pid文件 maxconn 4000 #最大连接数 daemon defaults #配置默认参数的,这些参数可以被利用配置到frontend,backend,listen组件 mode http #默认的模式mode { tcp|http|health },tcp是4层, http是7层,health只会返回OK(注,health已经废弃) log global #采用全局定义的日志 option httplog #日志类别http日志格式 option dontlognull #不记录健康检查的日志信息 option http-server-close #每次请求完毕后主动关闭http通道 option forwardfor except 127.0.0.0/8 #不记录本机转发的日志 option redispatch #serverId对应的服务器挂掉后,强制定向到其 他健康的服务器 retries 3 #3次连接失败就认为服务不可用,也可以通过后面设置 timeout http-request 10s #请求超时 timeout queue 1m #队列超时 timeout connect 10s #连接超时 timeout client 1m #客户端连接超时 timeout server 1m #服务器连接超时 timeout http-keep-alive 10s #长连接超时 timeout check 10s #检查超时 maxconn 30000 #最大连接数 listen stats #listen是Frontend和Backend的组合体。这里定义的是haproxy监控! mode http #模式http bind 0.0.0.0:1080 #绑定的监控ip与端口 stats enable #启用监控 stats hide-version #隐藏haproxy版本 stats uri /haproxyadmin?stats #定义的uri stats realm Haproxy\ Statistics #定义显示文字 stats auth admin:admin #认证 stats admin if TRUE frontend http-in #接收请求的前端虚拟节点,Frontend可以根据规则直接指定具体使用后 端的 backend(可动态选择)。这里定义的是 http服务! bind *:8080 #绑定的监控ip与端口 mode http #模式http log global #定义日志 option httpclose #每次请求完毕后主动关闭http通道 option logasap # option dontlognull ##不记录健康检查的日志信息 capture request header Host len 20 capture request header Referer len 60 default_backend server1 #定义的默认backend backend server1 #后端服务集群的配置,是真实的服务器,一个Backend对应一个或者多个 实体服务器。 balance roundrobin #负载均衡方式为轮询 server node1 192.168.56.102:80 check maxconn 2000 #定义server,check 健康 检查,maxconn 定义最大连接数 server node2 192.168.56.101:80 check maxconn 2000 backup -
配置/etc/sysconfig/rsyslog
第二步和第三步的主要目的便是配置rsyslog服务,使haproxy可以使用rsyslog服务将自己的工作情况记录到日志中。
# Options for rsyslogd # Syslogd options are deprecated since rsyslog v3. # If you want to use them, switch to compatibility mode 2 by "-c 2" # See rsyslogd(8) for more details SYSLOGD_OPTIONS="-c 2 -r"
-
配置/etc/rsyslog.conf
在文件尾部加上(请先确保/var/log/haproxy目录存在,当然,你也可以将日志文件存放到其他目录)
local2.* /var/log/haproxy/haproxy.log
rsyslog 默认情况下,需要在514端口监听UDP,所以可以把/etc/rsyslog.conf如下的注释去掉
# Provides UDP syslog reception 这一行是注释,不用去 $ModLoad imudp $UDPServerRun 514
修改完毕后,需要重启rsyslog服务
service rsyslog restart
注意”local2.*” 跟 “/var/log/haproxy/haproxy.log“之间不是空格,读者在该配置文件中寻找类似的例子,复制并更改即可。由此,我们可以通过
/var/log/haproxy/haproxy.log查看haproxy的相关情况。 -
启动haproxy
$ cd /usr/local/haproxy/sbin $ ./haproxy -f ../conf/haproxy.cfg -
需要注意的地方
- 配置文件第2行
local2要与 在/etc/rsyslog.conf中添加的一致 - 配置文件最后一行,
backup参数,表示将node2作为备份机,只有在node1 down掉时才会对外提供服务。
- 配置文件第2行
测试
在node0节点下
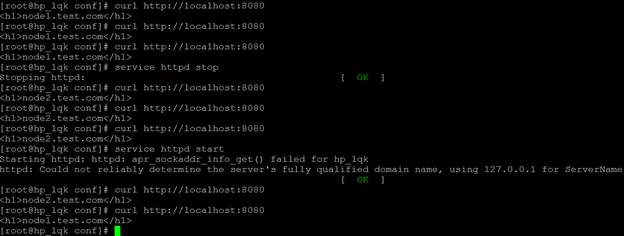
我们可以看到,执行curl http://localhost:8080,将返回nod1.test.com。当停止node1的httpd服务后,haproxy将自动将请求转发至node2。当启动node1的httpd服务后,haproxy又将请求切换至node1。
其它
如果碰到错误,可以打开两个应用(rsyslogd和haproxy)debug模式,抑或可以查看/var/log/syslog文件。