前言
apollo 是携程开源的配置管理平台,本文主要研究其apollo-client源码实现。
apollo-client 的使用参见 Java客户端使用指南
apollo-client 的主要包括以下几个部分:
- 提出一套数据结构以存储远端的配置信息
- 一套同步机制负责本地与远程配置的同步
- 和spring的整合
从功能上说,主要包括
- 为性能考虑,使用长连接。为防止长连接失效,支持周期性拉取。同时配置持久化到本地,以防止服务端失联。
- 支持多种格式的配置文件
- 配置更新时,要更新内存中bean的属性值,更新本地的缓存文件等。
这么多功能,我要实现的话,都不知到从何入手,这也是分析其实现的动力所在。
以前crud代码写太多了,通过对源码的学习,笔者对面向对象设计有一定认识,参见面向对象设计
类图分析
config
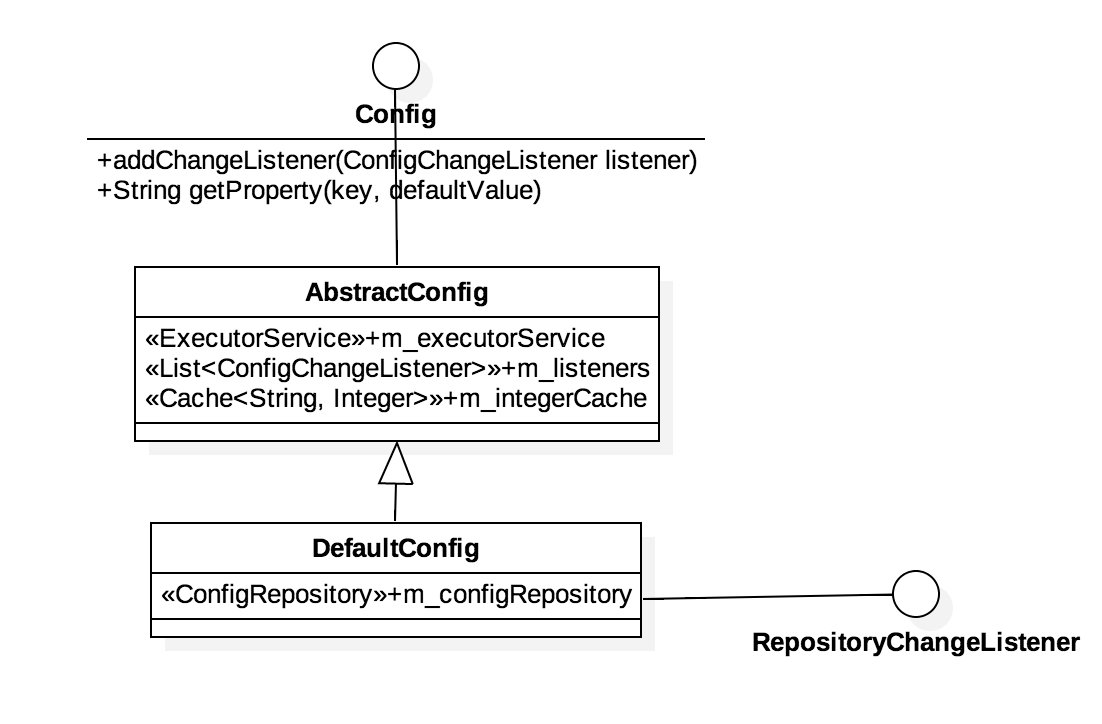
Config 定义外界使用接口,AbstractConfig处理掉Cache并用m_executorService处理掉ConfigChangeListener回调。真正配置的获取工作由DefaultConfig来完成(AbstractConfig并没有实现Config的String getProperty(name,defaultValue)),DefaultConfig将获取配置的工作交给ConfigRepository来负责,自己带上RepositoryChangeListener,对Config RepositoryChange事件作出处理。
或者说,从顶层设计上,DefaultConfigFactory.create将整体架构分为Config和ConfigRepository两个部分。
public Config create(String namespace) {
DefaultConfig defaultConfig =
new DefaultConfig(namespace, createLocalConfigRepository(namespace));
return defaultConfig;
}
此处可以有一个问题,为什么是DefaultConfig实现RepositoryChangeListener,而不是AbstractConfig实现RepositoryChangeListener?因为AbstractConfig重点在cache property和处理ConfigChangeListener回调。 其abstract 方法String getProperty(name,defaultValue) 并不要求底层跟ConfigRepository扯上关系,其简单实现可以是加载一个本地properties文件。
ConfigRepository
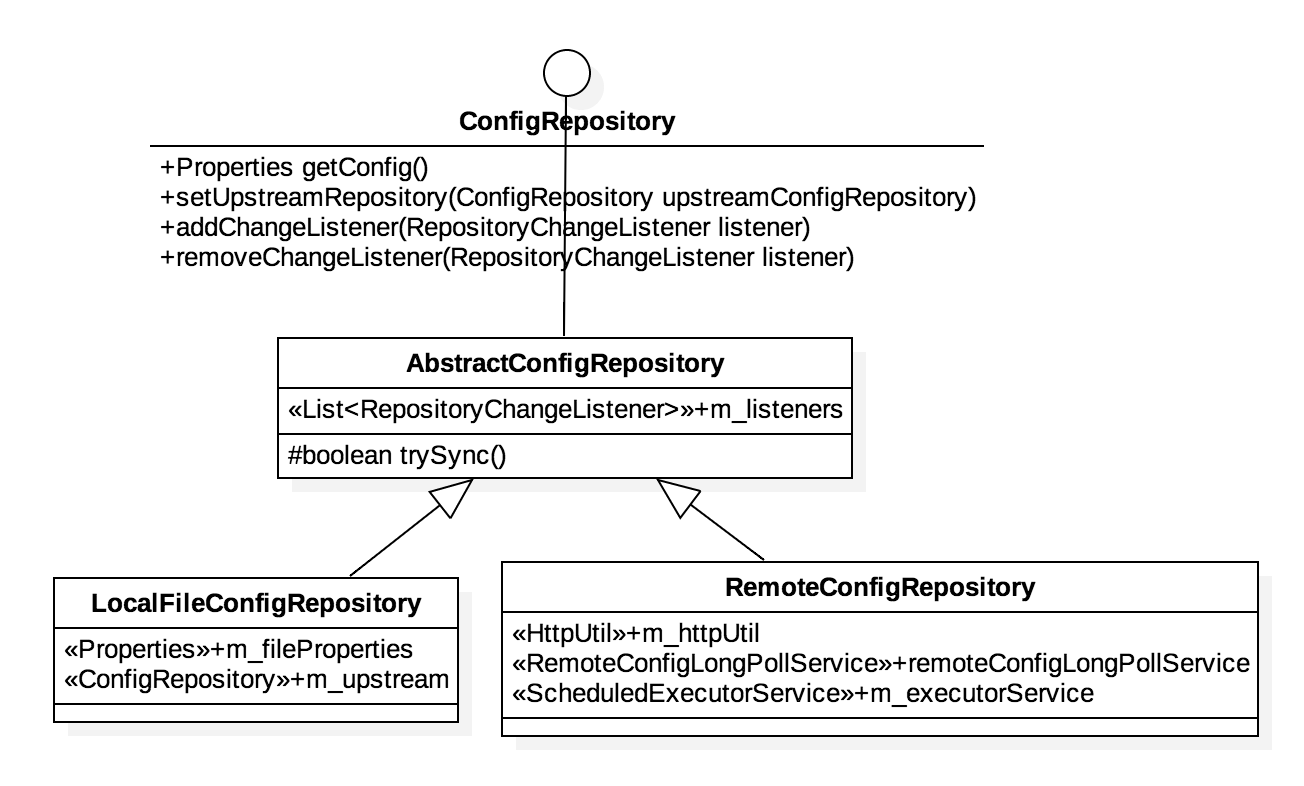
ConfigRepository 定义外界使用接口ConfigRepository和addChangeListener(in RepositoryChangeListener listener),同时ConfigRepository定义了setUpstreamRepository(in ConfigRepository upstreamConfigRepository)自用,以确保ConfigRepository 之间具备关联关系。
AbstractConfigRepository 处理RepositoryChangeListener回调,并提供了一个很有意义抽象trySync。对于LocalFileConfigRepository来说,其关联一个RemoteConfigRepository,sync逻辑就是将RemoteConfigRepository数据视情况同步到本地。对于RemoteConfigRepository,sync逻辑就是拉取远端配置。
Config和ConfigRepository 的关系
Config和ConfigRepository两个继承体系,在DefaultConfig那里分叉,但又双向关联,形成一个完善功能的整体。
| 说明 | |
|---|---|
| 正向关联 | DefaultConfig 操作 ConfigRepository |
| 反向关联 | ConfigRepository 操作 RepositoryChangeListener。在Config 继承体系中,由子类DefaultConfig 实现RepositoryChangeListener |
这是一种常见的设计方式,一个继承体系的顶层接口定义该继承体系的基本功能。其子类在继承上层接口或父类的同时,还继承其它接口,作为与其它继承体系互操作的基本约定。一个类实现很多功能,但面向不同的角色,只希望暴露有限的功能,这是子类继承其它接口的初衷。从另一个角度说,从一个继承体系抽离出另一个继承体系时,两个继承体系通过一个接口互操作。
ConfigService
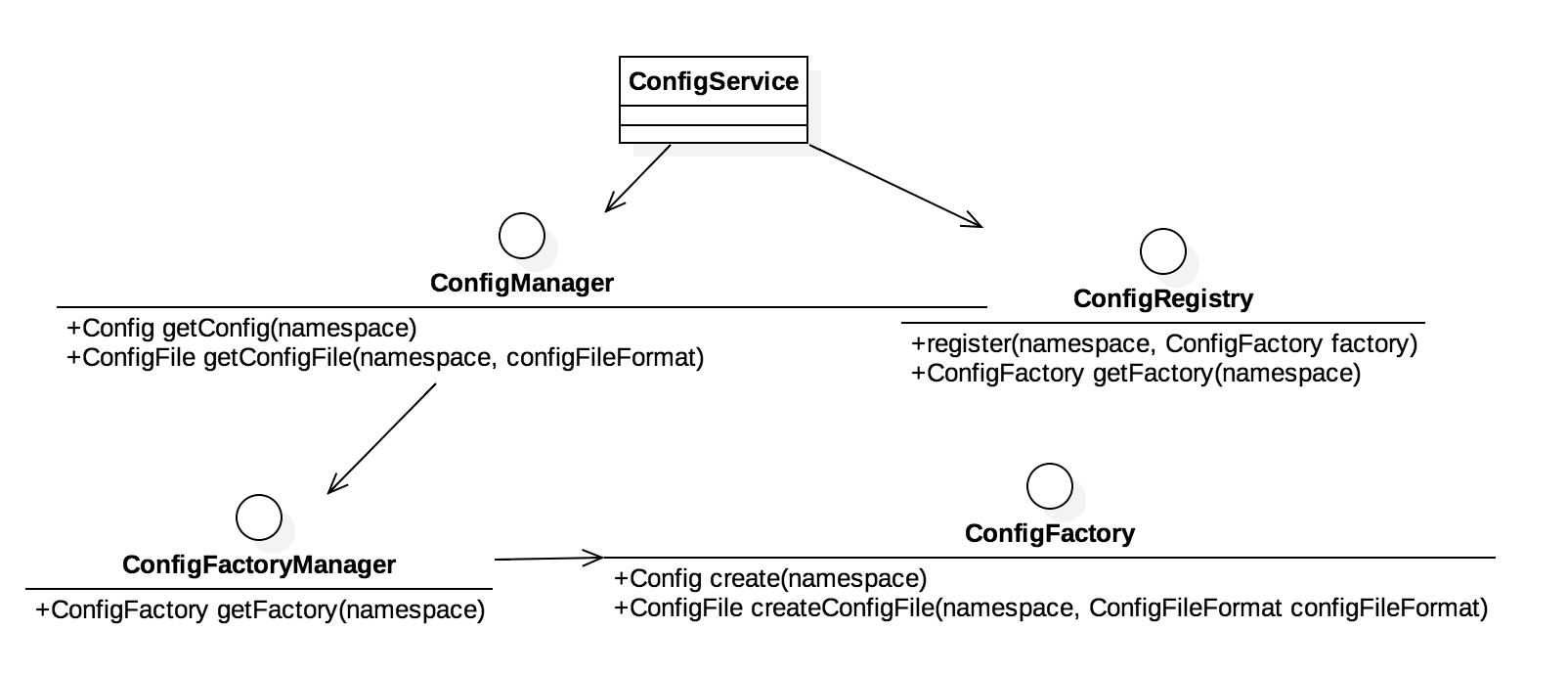
Config config = ConfigService.getConfig(namespace)是apollo-client的代码接口,ConfigService 缓存 namespace 和 Config的映射关系,通过map达成缓存和单例效果。 ConfigRegistry负责维护手动注入的namespace和Config映射(作用不明),ConfigFactoryManager 负责维护namespace和ConfigFactory的关系,ConfigFactory负责根据namespace创建Config。
有一个ConfigUtil 贯穿所有类,以在必要的时候获取配置(配置经过简单的处理)。
流程梳理
扳机在哪?哪些是主干,哪些是枝节?
首先为优化性能,各种缓存先不考虑。同样,为丰富功能,各种Listener也先省掉。我们发现主干就剩下Config和ConfigRepository,Config抽象配置使用,ConfigRepository抽象配置获取,它们的连接就是ConfigRepository 的Properties getConfig()
从中学习到的
分析代码
一个类有很多种成员,但一定有一个(最多两三个)跟这个类的功能关系最大。(哲学上说了,抓住问题的主要矛盾)
debug代码,从头到尾走一遍(在最后几步停下,看以前的堆栈),把涉及到的几个class diagram画出来。
自己从头到尾实现
代码是逐渐演化的,先实现最核心的功能。从配置中心的功能可以看出,最核心的是:从远程拉取配置存在内存中。附加功能涉及到
- 缓存配置以优化性能
- 本地持久化,与服务端失联时使用本地配置
- 单例、线程安全等问题
如何有一个通用的思维方法,可以导到作者的实现上?
以代码演化的角度看待架构设计,我们在实现附加功能的时候,不是简单的添加代码,这即涉及架构设计,也涉及到重构
- 提取超类、子类,纵向扩展继承体系
- 独立的功能分离,扩展成多个继承体系
作者关于ConfigRepository的设计还是非常精巧,自关联,由我来实现的话,或许还是要
ConfigRepository{
Properties remoteProperties; // 缓存远端结果,专职拉取线程拉到配置后存在这里
Properties getConfig(){
1. 连接状态正常,则从remoteProperties拿数据
2. 否则从本地Properties拿数据
}
sync(){
1. 从远端数据拿到后,更新remoteProperties及数据版本
2. 视数据版本更新本地Properties
}
}
但其实就本地Properties来说,根据配置读取Properties存储地址,Properties文件更新等,代码角度较多,抽取出来是一个很必要的选择。