前言
近日在学习go语言,go语言的一个重大特色就是支持协程(coroutine),即用户级线程。由运行在用户态程序实现“执行体”的调度和切换(本文将一个可并发执行的逻辑单元称为“执行体”),整个过程运行在一个或多个线程上,执行体切换过程不用“陷入”内核态,因此较为轻量。这种方式也有一定的缺点,因为协程概念提出的很早,主流语言却没有提供支持,必有原因,这个我们以后讨论。
当然,为了更好的了解goroutine,我们就有必要谈谈goroutine调度模型的实现。不过,作者是java开发人员,对分析c及汇编源码之类的事情能力有限,虽然有很多参考资料及公开的源码,分析来分析去,我也是醉了。所以在看了一些goroutine scheduler资料后,本文从另一个角度切入,描述下一个简单的协程调度模型如何实现。最后的分析可能与goroutine实际的实现不太一致,还望大家见谅。
单线程上的协程调度模型
假设只有一个线程,该线程运行一个调度程序,调度程序从其管理的执行体集合中取出一个执行体交给线程执行。该线程执行逻辑如下:
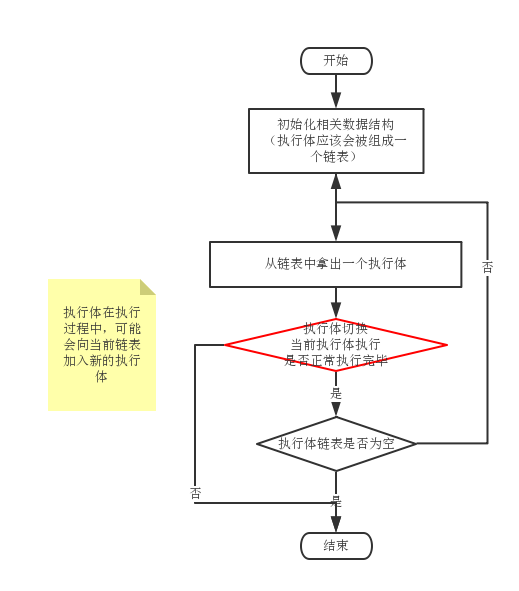
如果考虑执行体各种非正常退出的情况:
由此我们可以确定,实现该线程逻辑需要两个抽象:执行体和调度程序。
- 执行体包含:执行体的上下文环境,执行逻辑等
- 调度程序:执行体集合(链表),执行体切换等
该模型有两个问题:
- 除非执行体执行完毕、主动放弃或调用系统调用,执行体将一直“占用”线程。调度器因为没有“占用”线程,也只能干看着。这种非抢占式方式是协程调度模型的通病。
- 执行体执行过程中可能向执行体集合添加新的执行体,导致该线程负担过大。
tip
很难想象,在一个线程上,也能抽象出多个“执行体”,而操作系统的基本原理跟这个是非常类似的,不过,操作系统有一个利器“中断”,可以使得系统在必要的时候夺回“执行权”。
多个线程上协程调度模型
可以想见,如果只是运行在一个线程上,那么goroutine也太简单了,接下来谈谈运行在多个线程上的情况。
不管是运行在几个线程上,线程总得一个一个启动,下图是第一个线程的运行逻辑。当然,在第一个线程启动前,肯定要为整个调度模型做一些数据结构的初始化工作。
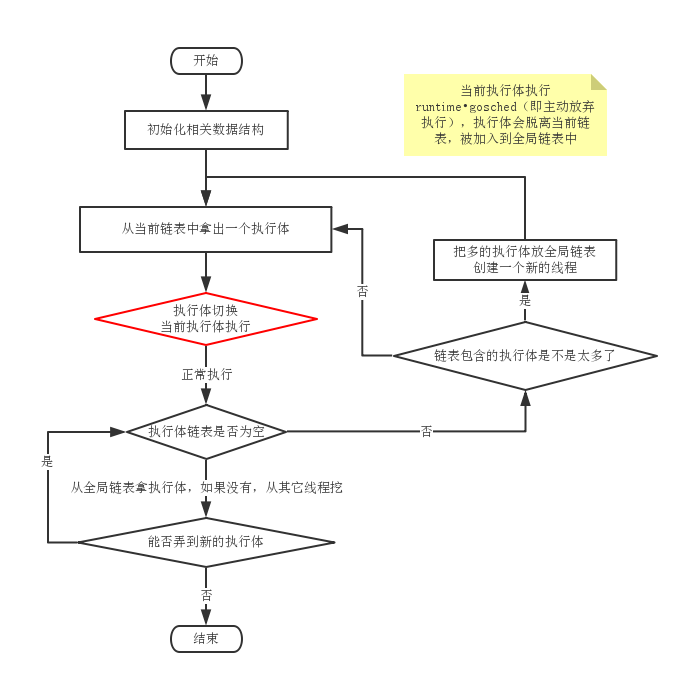
多个线程上调度跟单个线程调度有一个很大的不同就是:一旦执行体链表包含的执行体过多,就需要开启新的线程,转移部分执行体。反之,如果某个线程执行体链表为空,则需要从全局链表或其它线程那里“挖”执行体。
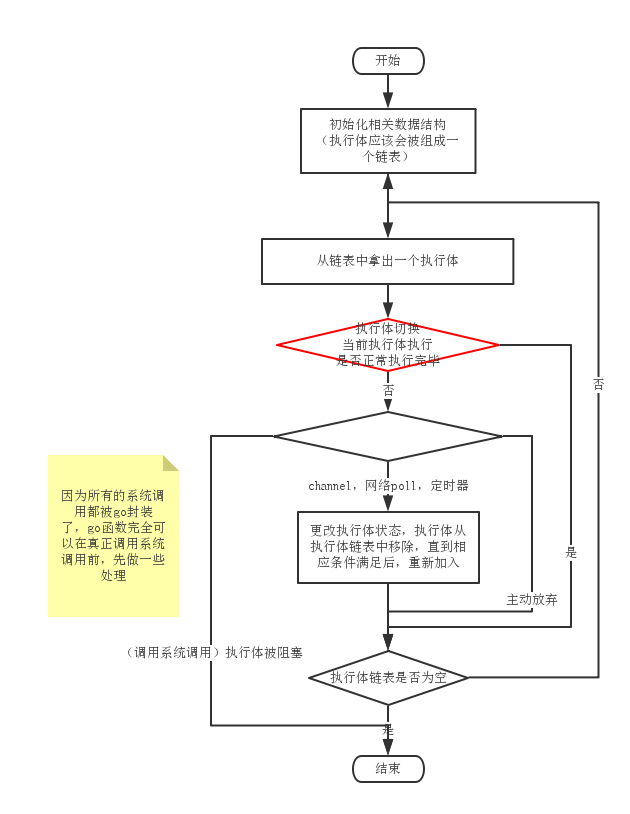
执行体本身是有状态的。
- 主动放弃执行。将执行体设置为runnable状态,然后放入到全局执行体集合。(看来执行体主动放弃执行,不仅是放弃所在线程的执行机会,还不想在本线程继续呆了)
- channel操作和网络操作等。执行体被置为wating状态,从本线程执行体集合中剥离,直到其依赖的条件满足。
- 调用系统调用。
第一个线程开始执行后,go调度模型还会创建一个sysmon线程(负责监控,不运行执行体)还有一个问题,那就是一旦执行体中调用系统调用,整个线程会被阻塞。为了不影响线程中其它执行体的执行,Go语言完全是自己封装的系统调用,所以在封装系统调用的时候,可以做不少手脚,也就是进入系统调用的时候执行entersyscall,退出后又执行exitsyscall函数。entersyscall将执行体从当前执行体链表中剥离,并将改变P的状态为syscall。Sysmon监控线程会扫描所有的P,发现一个P处于了syscall的状态,就知道这个P遇到了执行体在做系统调用,于是系统监控线程就会创建一个新的线程去把这个处于syscall的P给抢过来,开始干活,这样这个小车中的其它执行体就可以绕过之前系统调用的等待了。被抢走P的线程等系统调用返回后,发现自己的P没了,不能继续干活了,于是只能把执行系统调用的执行体放回到全局链表中,自己睡觉去了。
goroutine调度模型的四个抽象
有了上述铺垫,我们再来看goroutine调度模型4个重要结构,分别是M、G、P、Sched,前三个定义在runtime.h中,Sched定义在proc.c中。
- Sched结构就是调度器,它维护有存储M和G的队列(可能是全局的)以及调度器的一些状态信息等。
- M代表内核级线程,一个M就是一个线程,goroutine就是跑在M之上的;M是一个很大的结构,里面维护小对象内存cache(mcache)、当前执行的goroutine、随机数发生器等等非常多的信息。
- P全称是Processor,处理器,它的主要用途就是用来执行goroutine的,所以它也维护了一个goroutine队列,里面存储了所有需要它来执行的goroutine。
- G就是goroutine实现的核心结构了,G维护了goroutine需要的栈、程序计数器以及它所在的M等信息。
这样从前到后谈下来,是不是更顺一些。
补充
笔者今日学习Joe Armstrong的博士论文《面对软件错误构建可靠的分布式系统》,文中提到“在构建可容错软件系统的过程中要解决的本质问题就是故障隔离。”操作系统进程本身就是一种天然的故障隔离机制,当然从另一个层面,进程间还是因为共享cpu和内存等原因相互影响。因此,在go和erlang中,”进程和并发编程”是语言的一部分(语言本身提供这样的支持,比如“执行体调度程序”,而不是像其它语言一样,将线程映射到实际的操作系统线程上)。换句话说,一个由go语言完成的并发程序,虽然有很高的并发度,但在操作系统层面,go程序只是使用了几个线程而已(以及极少的线程间交互)。反过来讲,这种思想对编写高可靠性的程序意义重大。
进程要想达到容错性,就不能与其他进程有共享状态;它与其他进程的唯一联系就是由内核消息系统传递的消息。