简介
Nginx 公司的 Michael Hausenblas 发布了一本关于 docker 和 kubernetes 中的容器网络的小册子,本文是其读书笔记。
容器网络仍然非常年轻,年轻就意味着多变,笔者之前博客总结几套方案都落伍了, 这更加需要我们对容器网络有一个梳理。
service discovery and container orchestration are two sides of the same idea.
建议先看下程序猿视角看网络
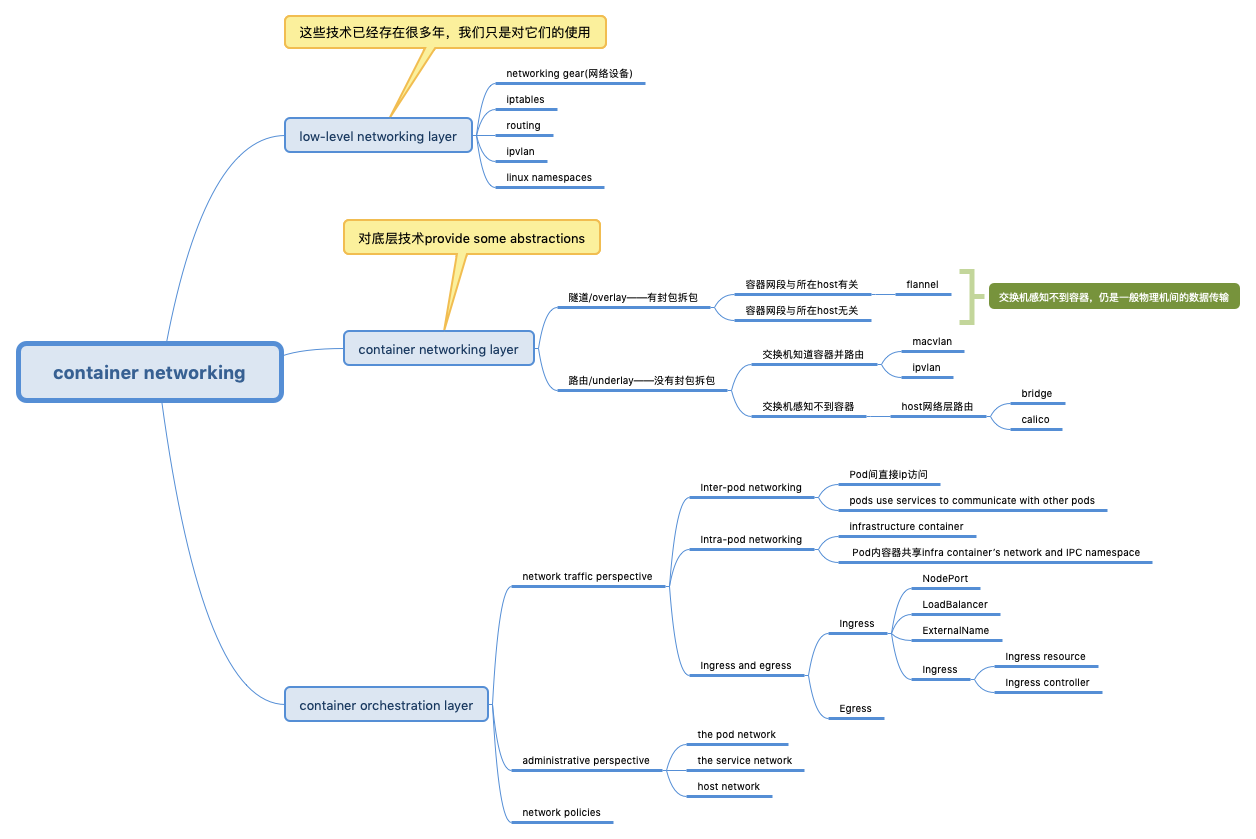
container networking stack
| 分层 | 包括哪些 | 作用 |
|---|---|---|
| the low-level networking layer | networking gear(网络设备),iptables,routing,ipvlan,linux namespaces | 这些技术已经存在很多年,我们只是对它们的使用 |
| the container networking layer | single-host bridge mode,multi-host,ip-per-container | 对底层技术provide some abstractions |
| the container orchestration layer | service discovery,loadbalance,cni,kubernetes networking | marrying the container scheduler’s decisions on where to place a container with the primitives provided by lower layers. |
一个 Network Namespace 的网络栈包括:网卡(Network Interface)、回环设备(Loopback Device)、路由表(Routing Table)和 iptables 规则。这句话框定了下文CNI plugin 的功能边界
多机
- 容器的一个诉求:To make a VM mobile you want to be able to move it’s physical location without changing it’s apparent network location.
- vlan 和vxlan 都是 virtual lan(局域网),但vlan 是隔离出来的,借助了交换机的支持(或者说推出太久了,以至于交换机普遍支持),vxlan 是虚拟出来的,交换机无感知。这种视角,有点像docker 与传统虚拟机的区别,隔离的好处是轻量也受交换机相关特性的限制(比如mac地址表上限)。虚拟的好处是灵活度高,但需要专门的中间组件。
- VXLAN与VLAN的最大区别在于,VLAN只是修改了原始的Ethernet Header,但是整个网络数据包还是原来那个数据包,而VXLAN是将原始的Ethernet Frame隐藏在UDP数据里面。经过VTEP封装之后,在网络线路上看起来只有VTEP之间的UDP数据传递,原始的网络数据包被掩盖了。
-
为什么构建数据中心用VXLAN?
- VXLAN evolved as a Data Center technology,所以分析vxlan 优势时一切以 数据中心的需求为出发点。一个超大型数据中心,交换机怎么联都是有技术含量的 What is a Networking Switch Fabric
- vlan 4096 数量限制 不是问题
- TOR(Top Of Rack)交换机MAC地址表限制。数据中心的虚拟化给网络设备带来的最直接影响就是:之前TOR(Top Of Rack)交换机的一个端口连接一个物理主机对应一个MAC地址,但现在交换机的一个端口虽然还是连接一个物理主机但是可能进而连接几十个甚至上百个虚拟机和相应数量的MAC地址。
- VTEP 在微服务领域有点像现在的service mesh,一个vm/container 是一个微服务,微服务只需和sevice mesh sidecar 沟通
Macvlan and ipvlan are Linux network drivers that exposes underlay or host interfaces directly to VMs or Containers running in the host.
| 特点 | ip/mac address | 从交换机的视角看vlan方案 | |
|---|---|---|---|
| vlan | A virtual LAN (VLAN) is any broadcast domain that is partitioned and isolated in a computer network at the data link layer (OSI layer 2). each sub-interface belongs to a different L2 domain using vlan |
all sub-interfaces have same mac address. | 交换机要支持 vlan tag,vlan 学习参见程序猿视角看网络 |
| Macvlan | Containers will directly get exposed in underlay network using Macvlan sub-interfaces. Macvlan has 4 types(Private, VEPA, Bridge, Passthru) 可以在vlan sub-interface 上创建 macvlan subinterface |
Macvlan allows a single physical interface to have multiple mac and ip addresses using macvlan sub-interfaces. |
交换机的port一般只与一个mac绑定,使用macvlan 后必须支持绑定多个 且 无数量限制 |
| ipvlan | ipvlan supports L2 and L3 mode. | the endpoints have the same mac address | 省mac地址 |
| vxlan | Virtual Extensible LAN (VXLAN) is a network virtualization technology that attempts to address the scalability problems associated with large cloud computing deployments. VXLAN endpoints, which terminate VXLAN tunnels and may be either virtual or physical switch ports, are known as VXLAN tunnel endpoints (VTEPs) |
交换机无感知 |
CNI
The cni specification is lightweight; it only deals with the network connectivity of containers,as well as the garbage collection of resources once containers are deleted.
cni 接口规范,不是很长Container Network Interface Specification,原来技术的世界里很多规范用Specification 来描述。
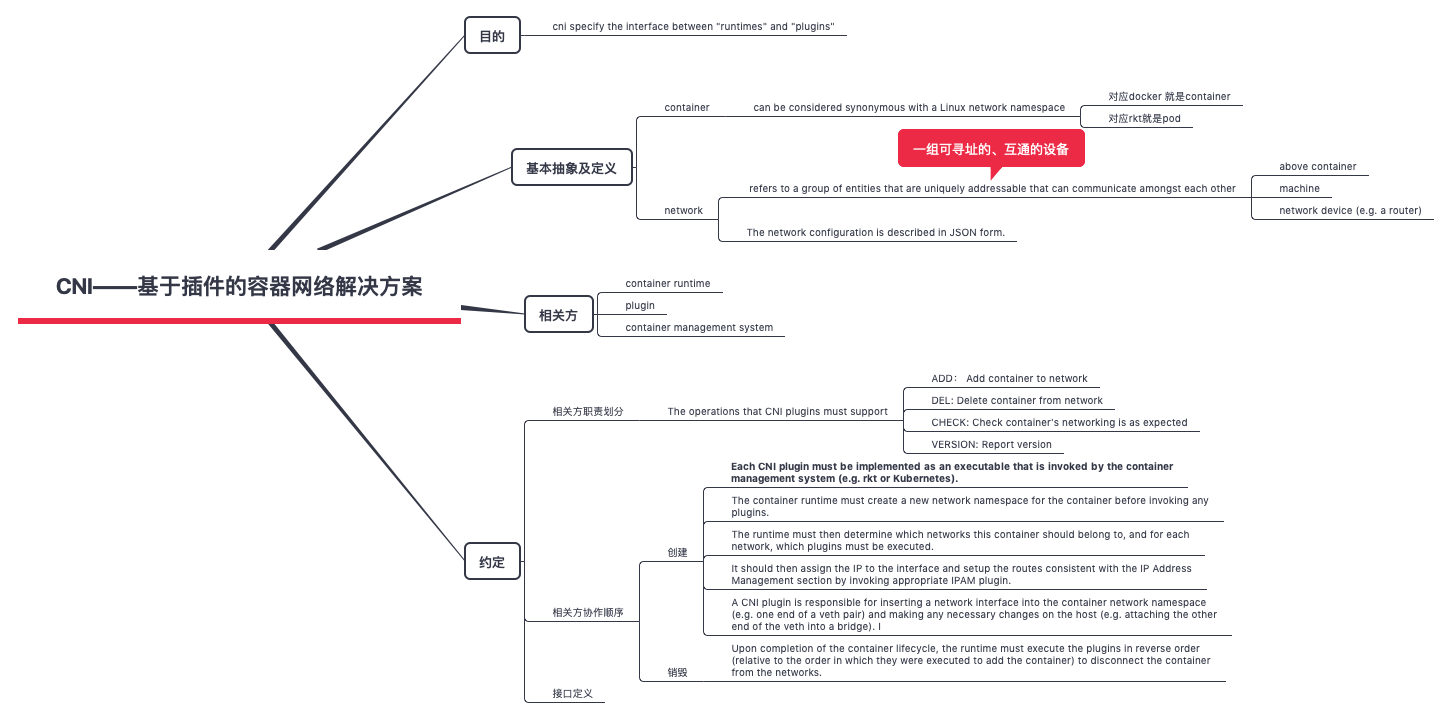
对 CNI SPEC 的解读 Understanding CNI (Container Networking Interface)
- If you’re used to dealing with Docker this doesn’t quite seem to fit the mold. 习惯了docker 之后, 再看cni 有点别扭。原因就在于,docker 类似于操作系统领域的windows,把很多事情都固化、隐藏掉了,以至于认为docker 才是标准。
- The CNI plugin is responsible wiring up the container. That is – it needs to do all the work to get the container on the network. In Docker, this would include connecting the container network namespace back to the host somehow. 在cni 的世界里,container刚开始时没有网络的,是container runtime 操作cni plugin 将container add 到 network 中。
“裸机” 使用cni
Understanding CNI (Container Networking Interface)
mkdir cni
user@ubuntu-1:~$ cd cni
user@ubuntu-1:~/cni$ curl -O -L https://github.com/containernetworking/cni/releases/download/v0.4.0/cni-amd64-v0.4.0.tgz
user@ubuntu-1:~/cni$ tar -xzvf cni-amd64-v0.4.0.tgz
user@ubuntu-1:~/cni$ ls
bridge cni-amd64-v0.4.0.tgz cnitool dhcp flannel host-local ipvlan loopback macvlan noop ptp tuning
创建一个命名空间
sudo ip netns add 1234567890
调用cni plugin将 container(也就是network namespace) ADD 到 network 上
cat > mybridge.conf <<"EOF"
{
"cniVersion": "0.2.0",
"name": "mybridge",
"type": "bridge",
"bridge": "cni_bridge0",
"isGateway": true,
"ipMasq": true,
"ipam": {
"type": "host-local",
"subnet": "10.15.20.0/24",
"routes": [
{ "dst": "0.0.0.0/0" },
{ "dst": "1.1.1.1/32", "gw":"10.15.20.1"}
]
}
}
EOF
sudo CNI_COMMAND=ADD CNI_CONTAINERID=1234567890 CNI_NETNS=/var/run/netns/1234567890 CNI_IFNAME=eth12 CNI_PATH=`pwd` ./bridge < mybridge.conf
mybridge.conf 描述了network 名为mybridge的配置,然后查看1234567890 network namespace 配置
sudo ip netns exec 1234567890 ifconfigeth12 Link encap:Ethernet HWaddr 0a:58:0a:0f:14:02
inet addr:10.15.20.2 Bcast:0.0.0.0 Mask:255.255.255.0
inet6 addr: fe80::d861:8ff:fe46:33ac/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:16 errors:0 dropped:0 overruns:0 frame:0
TX packets:8 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:1296 (1.2 KB) TX bytes:648 (648.0 B)
user@ubuntu-1:~/cni$ sudo ip netns exec 1234567890 ip route
default via 10.15.20.1 dev eth12
1.1.1.1 via 10.15.20.1 dev eth12
10.15.20.0/24 dev eth12 proto kernel scope link src 10.15.20.2
这个例子并没有什么实际的价值,但将“cni plugin操作 network namespace” 从cni繁杂的上下文中抽取出来,让我们看到它最本来的样子。从这也可以看到,前文画了图,整理了脑图,但资料看再多,都不如实操案例来的深刻。才能不仅让你“理性”懂了,也能让你“感性”懂了
Using CNI with container runtime
Using CNI with Docker net=none 创建的容器:sudo docker run --name cnitest --net=none -d jonlangemak/web_server_1,为其配置网络 与 上文的为 network namespace 配置网络是一样的。
I mentioned above that rkt implements CNI. In other words, rkt uses CNI to configure a containers network interface.
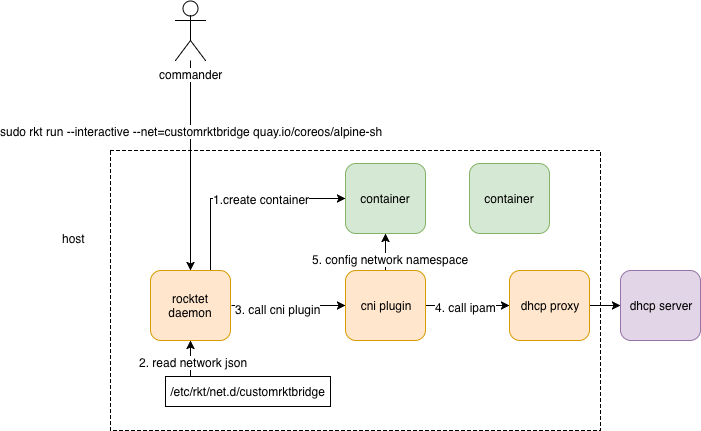
- network 要有一个json 文件描述,这个文件描述 放在rkt 可以识别的
/etc/rkt/net.d/目录下 sudo rkt run --interactive --net=customrktbridge quay.io/coreos/alpine-sh便可以创建 使用customrktbridge network 的容器了。类似的,是不是可以推断docker network create便是 将 network json 文件写入到相应目录下- 表面上的
sudo rkt run --interactive --net=customrktbridge quay.io/coreos/alpine-sh关于网络部分 实际上 是sudo CNI_COMMAND=ADD CNI_CONTAINERID=1234567890 CNI_NETNS=/var/run/netns/1234567890 CNI_IFNAME=eth12 CNI_PATH=pwd ./bridge < mybridge.conf执行,要完成这样的“映射”,需要规范定义 以及 规范相关方的协作,可以从这个角度再来审视前文对CNI SPEC 的一些梳理。
笔者以前一直有一个困惑,network、volume 可以作为一个“资源”随意配置,可以是一个json的存在,尤其是network,docker network create 完了之后 就可以在docker run -net=xx 的时候使用。kubernetes 中更是 yaml 中声明一下network即可使用,是如何的背景支撑这样做? 结合源码来看 加载 CNI plugin Kubelet 会根据 network.json cmd:=exec.Command(ctx,"bridge");cmd.Run()
{
"cniVersion": "0.2.0",
"name": "mybridge",
"type": "bridge",
"bridge": "cni_bridge0",
"isGateway": true,
"ipMasq": true,
"ipam": {
"type": "host-local",
"subnet": "10.15.20.0/24",
"routes": [
{ "dst": "0.0.0.0/0" },
{ "dst": "1.1.1.1/32", "gw":"10.15.20.1"}
]
}
}
答案就在于:我们习惯了主体 ==> 客体,比如docker早期版本,直接docker ==> container/network namespace。 而cni体系中则是runtime ==> cni plugin ==> container/network namespace。container runtime看作是一个network.json文件的“执行器”,通过json 文件找到cni plugin binary 并驱动其执行。一个network 不是一个真实实体,netowrk.json描述的不是如何创建一个网络,而是描述了如何给一个container 配置网络。
CNI 小结
有了整体的感觉时候,我们再来说
- 我们要为container 配置不同的网络
- 网络连通有不同的方案
-
如何将它们统一起来?
- 基本抽象contaienr + network
- 静态组件:container 即 network namespace ,network 定义规范
- 动态逻辑:container runtime、orchestrator 协作规范
CNI SPEC 做了建设性的抽象,在架构设计中有指导意义:如果你自己做架构设计,你定义的接口/规范 能hold住这么繁杂的 容器插件方案么?
kubernetes networking
想给一个容器连上网,办法实在太多,就好比现实世界中给你的电脑/手机连上网一样。但作为一个通用解决方案,就不得不做一定限制,好在k8s限制不太多。Rather than prescribing a certain networking solution, Kubernetes only states three fundamental requirements:
- Containers can communicate with all other containers without NAT.
- Nodes can communicate with all containers (and vice versa) without NAT.
- The IP a container sees itself is the same IP as others see it. each pod has its own IP address that other pods can find and use. 很多业务启动时会将自己的ip 发出去(比如注册到配置中心),这个ip必须是外界可访问的。 学名叫:flat address space across the cluster.
Kubernetes requires each pod to have an IP in a flat networking namespace with full connectivity to other nodes and pods across the network. This IP-per-pod model yields a backward-compatible way for you to treat a pod almost identically to a VM or a physical host(ip-per-pod 的优势), in the context of naming, service discovery, or port allocations. The model allows for a smoother transition from non–cloud native apps and environments. 这样就 no need to manage port allocation
A service provides a stable virtual IP (VIP) address for a set of pods. It’s essential to realize that VIPs do not exist as such in the networking stack. For example, you can’t ping them. They are only Kubernetes- internal administrative entities. Also note that the format is IP:PORT, so the IP address along with the port make up the VIP. Just think of a VIP as a kind of index into a data structure mapping to actual IP addresses.
k8s的service discovery 真的是 service 组件的discovery
- kube-proxy,给service 一个host 可访问的ip:port
- kube-dns/CNCF project CoreDNS,给service 一个域名
- Ingress,给service 一个可访问的http path
Using CNI with CRI
在 Kubernetes 中,处理容器网络相关的逻辑并不会在kubelet 主干代码里执行,而是会在具体的 CRI(CContainer Runtime Interface,容器运行时接口)实现里完成。对于 Docker 项目来说,它的CRI 实现叫作 dockershim
为什么pod中要有一个pause 容器?
Kubernetes networking 101 – Pods
all containers within a single pod share the same network namespace. 那么现在假设一个pod定义了三个容器(container1, container2, container3),你如何实现共享网络的效果呢?直接的想法:启动一个容器(比如container1),然后container2、container3 挂在container1上,但这样做有几个问题:
- 启动顺序无法保证,正常都是先拉到谁的镜像就先启动哪个
- 假设container1 挂了(比如业务代码问题),则就殃及container2, container3 。
- 尤其container3 还没有启动的时候,container1 挂了,那container3 怎么办呢?
the pause container servers as an anchoring point for the pod and make it easy to determine what network namespace the pod containers should join.
pause container 被称为 infrastructure container,中文有的文章简称 Infra 容器。Infra 容器一定要占用极少的资源,所以它使用的是一个非常特殊的镜像,叫作:k8s.gcr.io/pause。这个镜像是一个用汇编语言编写的、永远处于“暂停”状态的容器,解压后的大小也只有 100~200 KB 左右。