前言
Java Memory Model 它是一系列文章 Java Concurrency 中的一篇文章。
文章系统阐述了 java 内存模型的 知识,提出了一个描述体系。
- The Java memory model specifies how the Java virtual machine works with the computer’s memory (RAM). The Java virtual machine is a model of a whole computer so this model naturally includes a memory model - AKA the Java memory model. java内存模型 specifies 了jvm如何与物理机内存协同(work with)。因为jvm 是一个完整的计算机模型,因此java内存模型 很自然的包含了一个内存模型。
- The Java memory model specifies how and when different threads can see values written to shared variables by other threads, and how to synchronize access to shared variables when necessary.The Java memory model specifies
基于上述基本思想,文章从以下三个方面 来描述java 内存模型:
- java memory model。因为jvm 也是一个计算机模型,计算机模型都有一个内存模型,因此,jvm 自然也有自己的内存模型。
- harware memory Architecture
- Bridging The Gap Between The Java Memory Model And The Hardware Memory Architecture
Java和操作系统交互细节为了让应用程序免于数据竞争的干扰, Java 内存模型中定义了 happen-before 来描述两个操作的内存可见性,也就是 X 操作 happen-before 操作 Y , 那么 X 操作结果 对 Y 可见。
java memory model
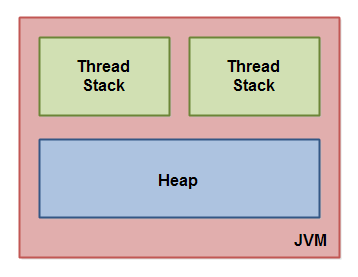
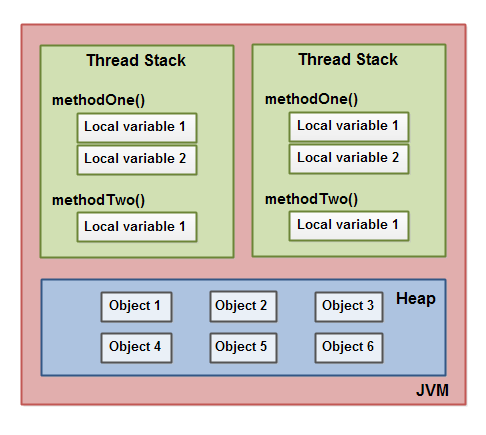
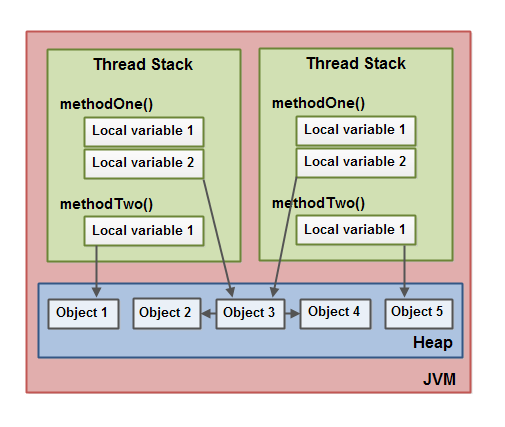
这几张图从粗到细,逐步引出了jvm 内存组成,栈的组成,堆的组成,栈和堆内数据的关系。逐步介绍了 thread stack、call stack(方法栈、栈帧)等概念
harware memory Architecture
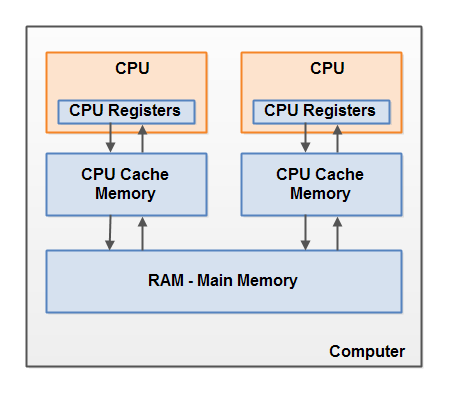
cpu ==> 寄存器 ==> cpu cache ==> main memory,cpu cache 由cache line 组成,cache line 是 与 main memory 沟通的基本单位,就像mysql innodb 读取 一行数据时 实际上不是 只读取一行,而是直接读取一页到内存一样。
java memory model 与 harware memory Architecture
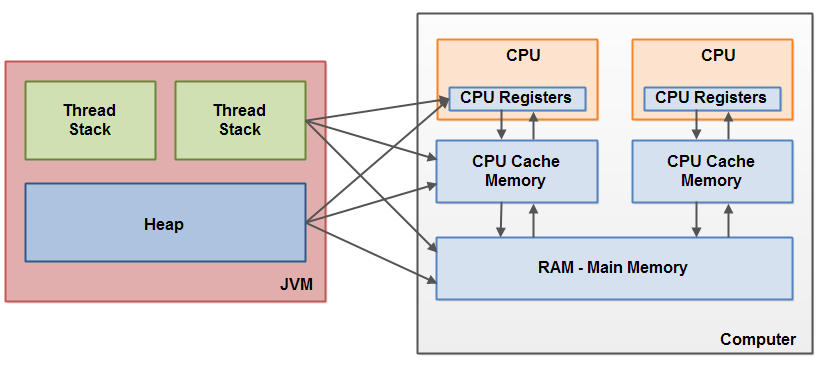
The hardware memory architecture does not distinguish between thread stacks and heap. On the hardware, both the thread stack and the heap are located in main memory. Parts of the thread stacks and heap may sometimes be present in CPU caches and in internal CPU registers. jvm 和 物理机 对“内存/存储” 有不同的划分,jvm 中没有cpu、cpu core 等抽象存在,也没有寄存器、cpu cache、main memory 的区分,因此 stack、heap 数据 可能分布在 寄存器、cpu cache、main memory 等位置。
When objects and variables can be stored in various different memory areas in the computer, certain problems may occur. The two main problems are:
- Visibility of thread updates (writes) to shared variables. 可以用volatile 关键字解决
- Race conditions when reading, checking and writing shared variables. 让两个线程 不要同时执行同一段代码,可以用synchronized block 解决,本质就是将竞争转移(从竞争同一个变量 到去竞争 同一个锁)。或者使用cas 保证竞争是原子的。
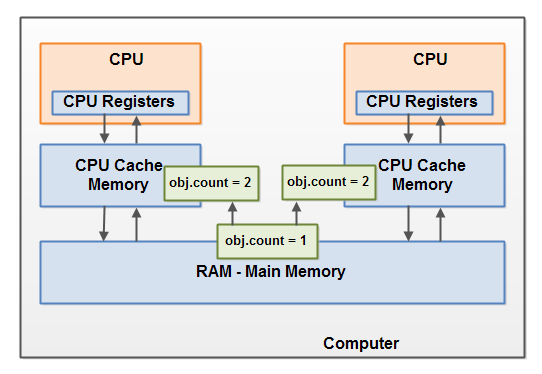
就着上图 去理解《java并发编程实战》中的有序性、原子性及可见性 ,会有感觉很多。
可以脑补一下 基于jvm 内存模型,多线程执行 访问 对象的局部变量 的图,直接的观感是jvm 是从内存(heap)中直接拿数据的,会有原子性问题,但没有可见性问题。但实际上,你根本搞不清楚,从heap 中拿到的对象变量的值 是从寄存器、cpu cache、main memory 哪里拿到的,写入问题类似。jvm 提供volatile 等微操工具,介入两种内存模型的映射过程,来确保预期与实际一致,从这个角度看,jvm 并没有完全屏蔽硬件架构的特性(当然,也是为了提高性能考虑),不过确实做到了屏蔽硬件架构的差异性。
到这里小结一下,当我们在说jvm 内存模型时,我在说什么?其实就是:jvm 内存区域构成(栈、堆等,栈由哪些构成,堆由哪些构成?) 以及 其与 硬件内存架构的 映射关系。
内存模型与语言
函数式编程 和 命令式编程中的 消息传递 模型,线程之间不会共享内存,也就没有 内存模型的问题。
JMM属于语言级的内存模型,它确保在不同的编译器和不同的处理器平台之上,通过禁止特定类型的编译器重排序和处理器重排序,为程序员提供一致的内存可见性保证。
Java内存模型FAQ(二) 其他语言,像C++,也有内存模型吗?大部分其他的语言,像C和C++,都没有被设计成直接支持多线程。这些语言对于发生在编译器和处理器平台架构的重排序行为的保护机制会严重的依赖于程序中所使用的线程库(例如pthreads),编译器,以及代码所运行的平台所提供的保障。也就是,语言上没有final、volatile 关键字这些,可以对编译器和处理器重排序 施加影响。
内存模型对代码和编程的影响
java 内存模型与并发读写控制
极客时间《深入拆解Java虚拟机》
- happens-before 关系是用来描述两个操作的内存可见性的。如果操作 X happens-before 操作 Y,那么 X 的结果对于 Y 可见。
- 规定的happens-before 关系:Java 内存模型定义了六七种线程间的 happens-before 关系。比如 线程的启动操作(即 Thread.starts()) happens-before 该线程的第一个操作。
- 可以手动控制的happens-before 关系:Java 内存模型通过定义了一系列的 happens-before 操作(包括锁、volatile 字段、final 字段与安全发布),让应用程序开发者能够轻易地表达不同线程的操作之间的内存可见性。
- Java 内存模型是通过内存屏障来禁止重排序的。对于即时编译器来说,内存屏障将限制它所能做的重排序优化。对于处理器来说,内存屏障会导致缓存的刷新操作。
法无禁止即允许,在遵守happens-before规则的前提下,即时编译器以及底层体系架构能够调整内存访问操作(也就是重排序),以达到性能优化的效果。
《mysql技术内幕》笔记2 提到 数据库一共会发生11种异常现象,脏读、不可重复读、幻读只是其中三种,数据库提出隔离性的概念,用这三种异常现象的出现情况来描述并发读写的安全程度。java 有可见性的概念,提供关键字(而不是配置,比如隔离级别是mysql的一种配置)给用户来描述期望的可见性。
| 为什么提出 | 实现原理 | |
|---|---|---|
| 隔离性 | 实现mysql 需要大量彼此关联的数据结构,并发读写 | 锁 |
| java内存模型 | java内存模型与硬件内存模型的映射,并发读写 + 编译器、cpu重排序 | happens-before 关系 + 内存屏障 |
如果只对一个共享变量并发访问,则读写异常的可能性只有有限的几种,若是多个并发变量或结构的并发读写,则异常现象则多了去了(比如上文提到的数据库一共会发生11种异常现象)。从mysql 并发控制 可以看到,一次mysql 记录的写入 包括索引、表等多个结构的写入。锁可以保证并发安全,在多个共享变量/结构的场景,
而所谓的多个线程共享结构的并发读写控制,目前看来,一般有几种处理方式
- 一些基本的业务逻辑的并发读写,由底层强制保证,比如jvm 默认的一些happens-before 关系
- 一些可选的,由用户指定。这方面,jvm 和 数据库隔离性暴露在上层 就不是锁的样子了
其它材料
JSR 133 (Java Memory Model) FAQ及其译文Java内存模型FAQ(一) 什么是内存模型,深入理解Java内存模型(一)——基础系列文章
首先,什么是内存模型,为何引入内存模型? one or more layers of memory cache。缓存能够大大提升性能,但是它们也带来了许多挑战。例如,当两个CPU同时检查相同的内存地址时会发生什么?在什么样的条件下它们会看到相同的值?
| 表现 | |
|---|---|
| 在cpu层面上 | 操作因为缓存的原因是否可见 |
| 在编译器层面上 | 重排序 |
The Java Memory Model describes what behaviors are legal in multithreaded code, and how threads may interact through memory(java 内存模型 描述了在多线程环境下哪些行为是合法的,线程之间如何通过共享内存的方式来通信). It describes the relationship between variables in a program and the low-level details of storing and retrieving them to and from memory or registers in a real computer system. It does this in a way that can be implemented correctly using a wide variety of hardware and a wide variety of compiler optimizations.
Java includes several language constructs, including volatile, final, and synchronized, which are intended to help the programmer describe a program’s concurrency requirements to the compiler. The Java Memory Model defines the behavior of volatile and synchronized, and, more importantly, ensures that a correctly synchronized Java program runs correctly on all processor architectures.
重排序
为什么会出现重排序
重排序的背景,参见从JVM并发看CPU内存指令重排序(Memory Reordering)
单cpu时代,因为流水线技术,多个指令同时开始执行,因每个指令的耗时不同,会出现后一个指令先于前一个指令执行完毕的情况。
我们知道现代CPU的主频越来越高,与cache的交互次数也越来越多。当CPU的计算速度远远超过访问cache时,会产生cache wait,过多的cache wait就会造成性能瓶颈。 针对这种情况,多数架构(包括X86)采用了一种将cache分片的解决方案,即将一块cache划分成互不关联地多个 slots (逻辑存储单元,又名 Memory Bank 或 Cache Bank),CPU可以自行选择在多个 idle bank 中进行存取。这种 SMP(指在一个计算机上汇集了一组处理器,各CPU之间共享内存子系统以及总线结构) 的设计,显著提高了CPU的并行处理能力,也回避了cache访问瓶颈。
Memory Bank的划分
一般 Memory bank 是按cache address来划分的。比如 偶数adress 0×12345000分到 bank 0, 奇数address 0×12345100分到 bank1。
重排序的种类
-
编译期重排。编译源代码时,编译器依据对上下文的分析,对指令进行重排序,使其更适合于CPU的并行执行。
-
运行期重排,CPU在执行过程中,动态分析依赖部件的效能(CPU0检查 bank0 的可用性,发现 bank0 处于 busy 状态,那么本来写入cache bank0的数据操作会延后),对指令做重排序优化。
前者是编译器进行的,不同语言不同。后者是cpu 层面的,所有使用共享内存模型进行线程通信的语言都要面对的。
重排序的影响
主要体现在两个方面,详见Java内存访问重排序的研究
-
对代码执行的影响
常见的是,一段未经保护的代码,因为多线程的影响可能会乱序输出。少见的是,重排序也会导致乱序输出。
-
对编译器、runtime的影响,这体现在两个方面:
- 运行期的重排序是完全不可控的,jvm经过封装,要保证某些场景不可重排序(比如数据依赖场景下)。提炼成理论就是:happens-before规则(参见《Java并发编程实践》章节16.1),Happens-before的前后两个操作不会被重排序且后者对前者的内存可见。
- 提供一些关键字(主要是加锁、解锁),也就是允许用户介入某段代码是否可以重排序。这也是“which are intended to help the programmer describe a program’s concurrency requirements to the compiler” 的部分含义所在。
Java内存访问重排序的研究文中提到,内存可见性问题也可以视为重排序的一种。比如,在时刻a,cpu将数据写入到memory bank,在时刻b,同步到内存。cpu认为指令在时刻a执行完毕,我们呢,则认为代码在时刻b执行完毕。