简介(持续更新)
大部分时候,我们将队列作为一种数据容器,但在并发场景下,未获得锁的线程要进入队列等待。此时线程 作为一种“执行体” 成为队列的元素。而我们以线程排队一些事情会非常有意思。
什么决定了系统的并发数量
假设系统架构设计的时候,不考虑任何物理限制(比如机器的资源大小,带宽等),要求能并发处理 1000个请求,那么很显然,横向扩展的节点数量上限就是1000,因为就算部署了 1001个节点,在任何时候都有一个节点是处于空闲状态,部署更多的节点已经完全无法提高系统的性能。那系统的并发数量由什么决定呢?
以一个二手书交易平台为例,订单系统的理论上能够处理的并发请求(订购商品请求)数量是由什么来决定的呢?
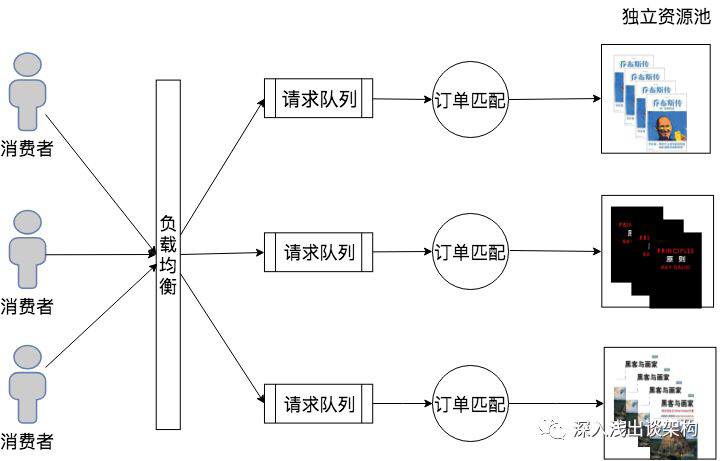
在订单请求来了之后,根据订单请求中的购买的商品来排队,购买同一个商品的请求被放在一个队列里面,然后订单的调度系统开始从队列里面依次处理请求,每次做订单匹配的时候,都需根据当前商品的所有库存,从里面挑选一个最佳匹配的库存(比如买家和卖家距离最近)。
在实现这个系统的时候,这个队列不见得是一个消息队列,可能会是一个关系型数据库的锁,比如一个购买《乔布斯传》的订单,系统在处理的时候需要先从所有库存里面查询出《乔布斯传》的库存,将库存记录锁住,并做订单匹配且更新库存(将生成订单的库存商品设置为”不可用”状态)之后,才会将数据库锁释放,这时候所有后续购买《乔布斯传》的订单请求都在队列中等待。
也有些系统在实现的时候采用“乐观锁”,就是每次订单处理时,并不会在一开始就锁住库存信息,而是在最后一步更新库存的时候才会锁住,如果发生两个订单匹配到了同一个库存物品,那么其中一个订单处理就需要完全放弃然后重试。这两种实现方式不太一样,但是本质都是相同的。
PS:排队是肯定要排队的,只是排队的表现形式不同,或是显式队列,或是(数据库)操作系统锁队列
之所以所有购买《乔布斯传》的订单需要排队处理,是因为每一次做订单匹配的时候,需要《乔布斯传》这个商品的所有库存信息,并且最后会修改(占用)一部分库存信息的状态。在该订单匹配的场景里面,我们就把《乔布斯传》的所有库存信息叫做一个“独立资源池”,订单匹配这个“调度系统”的最大并发数量就完全取决于独立资源池的数量,也就是商品的数量。我们假设一下,如果这个二手书的商城只卖《乔布斯传》一本书,那么最后所有的请求都需要排队
传统队列
synchronized
Java和操作系统交互细节如果线程进入 monitorenter 会将自己放入该 objectmonitor 的 entryset 队列,然后阻塞(PS: 注意这种表述方式,是线程自己将自己加入队列,然后线程自己阻塞了自己),如果当前持有线程调用了 wait 方法,将会释放锁,然后将自己封装成 objectwaiter 放入 objectmonitor 的 waitset 队列,这时候 entryset 队列里的某个线程将会竞争到锁,并进入 active 状态,如果这个线程调用了 notify 方法,将会把 waitset 的第一个 objectwaiter 拿出来放入 entryset (这个时候根据策略可能会先自旋),当调用 notify 的那个线程执行 moniterexit 释放锁的时候, entryset 里的线程就开始竞争锁后进入 active 状态。
AQS 的排队方式
guava cache的 请求合并
其它
全面异步化:淘宝反应式架构升级探索 消息驱动强调无阻塞、无 callback,所以不会有线程挂在那里,不会有持续的资源消耗。同时,事件驱动或消息驱动都是异步化,而异步化会将操作系统中的队列情况显式地提升到了应用层,使得应用层可以显式根据队列的情况来进行压力负载的感知。
操作系统的内存分配、进程/线程调度、队列等显式到应用层,看起来是一个趋势。这样,应用层线程一直是(尽量)跑满的,os 单纯的根据时间片切换线程即可。
笔者个人微信订阅号
