简介
资源调度泛谈
Kubernetes架构为什么是这样的?在 Google 的一篇关于内部 Omega 调度系统的论文中,将调度系统分成三类:单体、二层调度和共享状态三种,按照它的分类方法,通常Google的 Borg被分到单体这一类,Mesos被当做二层调度,而Google自己的Omega被当做第三类“共享状态”。我认为 Kubernetes 的调度模型也完全是二层调度的,和 Mesos 一样,任务调度和资源的调度是完全分离的,Controller Manager承担任务调度的职责,而Scheduler则承担资源调度的职责。
| Mesos | K8S | |
|---|---|---|
| 资源分配 | Mesos Master Framework |
Scheduler |
| 任务调度 | Framework | Controller Manager |
Kubernetes和Mesos调度的最大区别在于资源调度请求的方式
- 主动 Push 方式。是 Mesos 采用的方式,就是 Mesos 的资源调度组件(Mesos Master)主动推送资源 Offer 给 Framework,Framework 不能主动请求资源,只能根据 Offer 的信息来决定接受或者拒绝。
- 被动 Pull 方式。是 Kubernetes 的方式,资源调度组件 Scheduler 被动的响应 Controller Manager的资源请求。
集群调度系统的演进Kubernetes 是一个集群调度系统,今天这篇文章主要是介绍 Kubernetes 之前一些集群调度系统的架构,通过梳理他们的设计思路和架构特点,我们能够学习到集群调度系统的架构的演进过程,以及在架构设计时需要考虑的主要问题,对理解 Kubernetes 的架构会非常有帮助。(未细读)
为什么不支持横向扩展?
几乎所有的集群调度系统都无法横向扩展(Scale Out),集群调度系统的架构看起来都是这个样子的
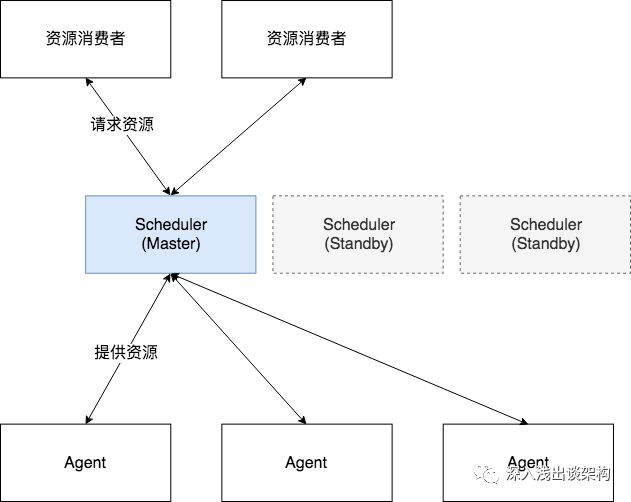
中间的 Scheduler(资源调度器)是最核心的组件,虽然通常是由多个(通常是3个)实例组成,但是都是单活的,也就是说只有一个节点工作,其他节点都处于 Standby 的状态。
每一台服务器节点都是一个资源,每当资源消费者请求资源的时候,调度系统的职责就是要在全局内找到最优的资源匹配:拿到全局某个时刻的全局资源数据,找到最优节点——这是一个独占操作。
Kubernetes 资源模型与资源管理
在 Kubernetes 里,Pod 是最小的原子调度单位。这也就意味着,所有跟调度和资源管理相关的属性都应该是属于 Pod 对象的字段。而这其中最重要的部分,就是 Pod 的CPU 和内存配置
在 Kubernetes 中,像 CPU 这样的资源被称作“可压缩资源”(compressible resources)。它的典型特点是,当可压缩资源不足时,Pod 只会“饥饿”,但不会退出。
而像内存这样的资源,则被称作“不可压缩资源(incompressible resources)。当不可压缩资源不足时,Pod 就会因为 OOM(Out-Of-Memory)被内核杀掉。
Kubernetes 里 Pod 的 CPU 和内存资源,实际上还要分为 limits 和 requests 两种情况:在调度的时候,kube-scheduler 只会按照 requests 的值进行计算。而在真正设置 Cgroups 限制的时候,kubelet 则会按照 limits 的值来进行设置。这个理念基于一种假设:容器化作业在提交时所设置的资源边界,并不一定是调度系统所必须严格遵守的,这是因为在实际场景中,大多数作业使用到的资源其实远小于它所请求的资源限额。
QoS 划分的主要应用场景,是当宿主机资源(主要是不可压缩资源)紧张的时候,kubelet 对 Pod 进行 Eviction(即资源回收)时需要用到的。“紧张”程度可以作为kubelet 启动参数配置,默认为
memory.available<100Mi
nodefs.available<10%
nodefs.inodesFree<5%
imagefs.available<15%
Kubernetes 计算 Eviction 阈值的数据来源,主要依赖于从 Cgroups 读取到的值,以及使用 cAdvisor 监控到的数据。当宿主机的 Eviction 阈值达到后,就会进入 MemoryPressure 或者 DiskPressure 状态,从而避免新的 Pod 被调度到这台宿主机上。
limit 不设定,默认值由 LimitRange object确定
| limits | requests | Qos模型 | |
|---|---|---|---|
| 有 | 有 | 两者相等 | Guaranteed |
| 有 | 无 | 默认两者相等 | Guaranteed |
| x | 有 | 两者不相等 | Burstable |
| 无 | 无 | BestEffort |
而当 Eviction 发生的时候,kubelet 具体会挑选哪些 Pod 进行删除操作,就需要参考这些 Pod 的 QoS 类别了。PS:怎么有一种 缓存 evit 的感觉。limit 越“模糊”,物理机MemoryPressure/DiskPressure 时,越容易优先被干掉。
DaemonSet 的 Pod 都设置为 Guaranteed 的 QoS 类型。否则,一旦 DaemonSet 的 PPod 被回收,它又会立即在原宿主机上被重建出来,这就使得前面资源回收的动作,完全没有意义了。
实现
在 Kubernetes 项目中,默认调度器的主要职责,就是为一个新创建出来的 Pod,寻找一个最合适的节点(Node)而这里“最合适”的含义,包括两层:
- 从集群所有的节点中,根据调度算法挑选出所有可以运行该 Pod 的节点;
- 从第一步的结果中,再根据调度算法挑选一个最符合条件的节点作为最终结果。
所以在具体的调度流程中,默认调度器会首先调用一组叫作 Predicate 的调度算法,来检查每个 Node。然后,再调用一组叫作 Priority 的调度算法,来给上一步得到的结果里的每个 Node 打分。最终的调度结果,就是得分最高的那个Node。
调度器对一个 Pod 调度成功,实际上就是将它的 spec.nodeName 字段填上调度结果的节点名字。 这在k8s 的很多地方都要体现,k8s 不仅将对容器的操作“标准化” ==> “配置化”,一些配置是用户决定的,另一个些是系统决定的
调度主要包括两个部分
- 组件交互,包括如何与api server交互感知pod 变化,如何感知node 节点的cpu、内存等参数。PS:任何调度系统都有这个问题。
- 调度算法,上文的Predicate和Priority 算法
调度这个事情,在不同的公司和团队里的实际需求一定是大相径庭的。上游社区不可能提供一个大而全的方案出来。所以,将默认调度器插件化是 kube-scheduler 的演进方向。
算法
Predicate
- GeneralPredicates
- PodFitsResources,检查的只是 Pod 的 requests 字段
- PodFitsHost,宿主机的名字是否跟 Pod 的 spec.nodeName 一致。
- PodFitsHostPorts,Pod 申请的宿主机端口(spec.nodePort)是不是跟已经被使用的端口有冲突。
- PodMatchNodeSelector,Pod 的 nodeSelector 或者 nodeAffinity 指定的节点,是否与待考察节点匹配
- 与 Volume 相关的过滤规则
- 是宿主机相关的过滤规则
- Pod 相关的过滤规则。比较特殊的,是 PodAffinityPredicate。这个规则的作用,是检查待调度 Pod 与 Node 上的已有 Pod 之间的亲密(affinity)和反亲密(anti-affinity)关系
在具体执行的时候, 当开始调度一个 Pod 时,Kubernetes 调度器会同时启动 16 个 Goroutine,来并发地为集群里的所有 Node 计算 Predicates,最后返回可以运行这个 Pod 的宿主机列表。
Priorities
在 Predicates 阶段完成了节点的“过滤”之后,Priorities 阶段的工作就是为这些节点打分。这里打分的范围是 0-10 分,得分最高的节点就是最后被 Pod 绑定的最佳节点。
-
LeastRequestedPriority + BalancedResourceAllocation
- LeastRequestedPriority计算方法
score = (cpu((capacity-sum(requested))10/capacity) + memory((capacity-sum(requested))10/capacity))/2实际上就是在选择空闲资源(CPU 和 Memory)最多的物理机 - BalancedResourceAllocation,计算方法
score = 10 - variance(cpuFraction,memoryFraction,volumeFraction)*10每种资源的 Fraction 的定义是 :Pod 请求的资源/ 节点上的可用资源。而 variance 算法的作用,则是资源 Fraction 差距最小的节点。BalancedResourceAllocation 选择的,其实是调度完成后,所有节点里各种资源分配最均衡的那个节点,从而避免一个节点上 CPU 被大量分配、而 Memory 大量剩余的情况。
- LeastRequestedPriority计算方法
- NodeAffinityPriority
- TaintTolerationPriority
- InterPodAffinityPriority
- ImageLocalityPriority
优先级和抢占
优先级和抢占机制,解决的是 (高优先级的)Pod 调度失败时该怎么办的问题
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority
Pod 通过 priorityClassName 字段,声明了要使用名叫 high-priority 的 PriorityClass。当这个 Pod 被提交给 Kubernetes 之后,Kubernetes 的 PriorityAdmissionController 就会自动将这个 Pod 的 spec.priority 字段设置为 PriorityClass 对应的value 值。
如果确定抢占可以发生,那么调度器就会把自己缓存的所有节点信息复制一份,然后使用这个副本来模拟抢占过程。
- 找到牺牲者,判断抢占者是否可以部署在牺牲者所在的Node上
-
真正开始抢占
- 调度器会检查牺牲者列表,清理这些 Pod 所携带的 nominatedNodeName 字段。
- 调度器会把抢占者的 nominatedNodeName,设置为被抢占的 Node 的名字。
- 调度器会开启一个 Goroutine,同步地删除牺牲者。
- 调度器就会通过正常的调度流程把抢占者调度成功