简介
本文主要来自对[https://cloud.google.com/container-engine/docs](https://cloud.google.com/container-engine/docs ““)的摘抄,有删改。
2019.1.29补充:之前理解的服务对外部的访问,服务的“粒度”比较大,如一个支付接口,后面一堆服务支撑。而Kubernetes 是打算将pod 级别的对外访问也交给service,因为ip 是变化的 以及 多个pod 负载均衡的需求,这也是kubernetes 不提倡ip 访问而提供的替换方案。但service 是基于iptables实现的,在复杂系统中,网络处理越简单越好。iptables是万恶之源,给实际工作中的运维排错带来极大的麻烦。在一些大厂的实践中,一般很少使用service 方案。
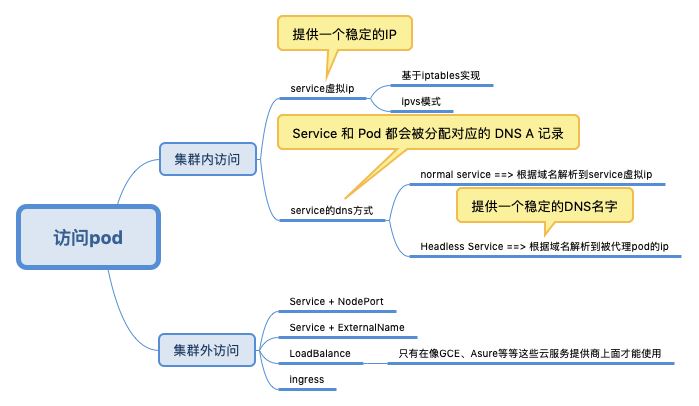
What is a service?
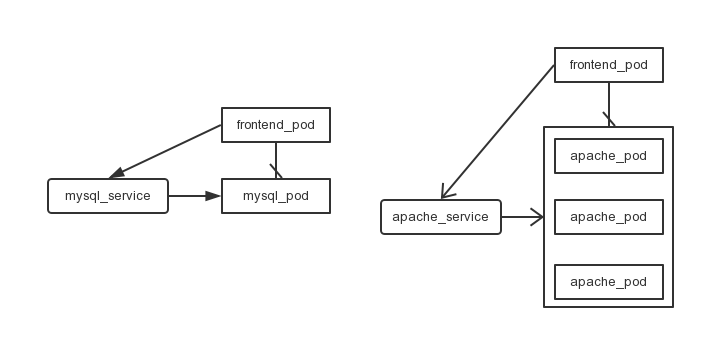
Container Engine pods are ephemeral(短暂的). They can come and go over time, especially when driven by things like replication controllers. While each pod gets its own IP address, those IP addresses cannot be relied upon to be stable over time(直接通过一个pod的ip来访问它是不可靠的). This leads to a problem: if some set of pods (let’s call them backends) provides functionality to other pods (let’s call them frontends) inside a cluster, how do those frontends find the backends? (Pod组件的状态经常变化,也可能存在多个副本,那么其他组件如何来访问它呢)
A Container Engine service is an abstraction which defines a logical set of pods and a policy by which to access them. The goal of services is to provide a bridge for non-Kubernetes-native applications to access backends without the need to write code that is specific to Kubernetes. A service offers clients an IP and port pair which, when accessed, redirects to the appropriate backends.(service会提供一个稳定的ip,作为桥梁,让其它pod访问。而service负责将请求转发到其对应的pod上) The set of pods targeted is determined by a label selector.
突然想起一句话:计算机里的事情,没什么问题是加一层解决不了的。
How do they work?——基于iptables实现
Service 是由 kube-proxy 组件,加上 iptables 来共同实现的。
Every node in a Kubernetes cluster runs a kube-proxy. This application watches the Kubernetes master for the addition and removal of Service and Endpoints objects. For each Service it opens a port (random) on the local node. Any connections made to that port will be proxied to one of the corresponding backend Pods.(这句非常关键) Which backend to use is decided based on the AffinityPolicy of the Service. Lastly, it installs iptables rules which capture traffic to the Service’s Port on the Service’s portal IP and redirects that traffic to the previously described port.
The net result is that any traffic bound for the Service is proxied to an appropriate backend without the clients knowing anything about Kubernetes or Services or Pods.
When a pod is scheduled, the master adds a set of environment variables for each active service.
两台主机192.168.56.101和192.168.56.102,假设我运行一个apache2 pod和apache2 service,查看:
$ kubectl get service
NAME LABELS SELECTOR IP PORT
apache2-service <none> name=apache2 10.100.62.248 9090
kubernetes component=apiserver,provider=kubernetes <none> 10.100.0.2 443
kubernetes-ro component=apiserver,provider=kubernetes <none> 10.100.0.1 80
$ kubectl get pods
POD IP CONTAINER(S) IMAGE(S) HOST LABELS STATUS
apache2-pod 10.100.83.5 apache2 docker-registry.sh/apache2 192.168.56.102/192.168.56.102 name=apache2 Running
Kubernetes内部如何访问这个Pod对应的Service?
- 通过DNS
-
环境变量
apache pod的ip是
10.100.83.5,pod的ip是不可靠的,所以其它pod要通过pod对应的service10.100.62.248:9090来访问这个pod。Kubernetes为minion节点添加iptables规则(将10.100.62.248:9090转发到一个任意端口),当minion收到来自10.100.62.248:9090请求时,将请求转发到任意端口,Kube-proxy进程再将其转发(根据一定的分发策略)到Pod上。
那么外界如何访问这个pod呢?我们可以看到这个pod被分配到了192.168.56.102这台主机上,查看这台主机的iptables。(192.168.56.101也为该service做了映射,此处不再赘述)
$ sudo iptables -nvL -t nat
Chain KUBE-PORTALS-CONTAINER (1 references)
pkts bytes target prot opt in out source destination
0 0 REDIRECT tcp -- * * 0.0.0.0/0 10.100.0.1 /* kubernetes-ro */ tcp dpt:80 redir ports 37483
0 0 REDIRECT tcp -- * * 0.0.0.0/0 10.100.0.2 /* kubernetes */ tcp dpt:443 redir ports 46593
0 0 REDIRECT tcp -- * * 0.0.0.0/0 10.100.62.248 /* apache2-service */ tcp dpt:9090 redir ports 36036
可以发现kube_proxy为其分配了36036端口,以后其它应用就可以通过192.168.56.102 :36036来访问10.100.62.248:9090,进而访问10.100.83.5:80
查看etcd:
$ etcdctl get /registry/services/endpoints/default/apache2-service
{"kind":"Endpoints","id":"apache2-service","uid":"09a711e5-c3d0-11e4-b06e-0800272b69e4","creationTimestamp":"2015-03-06T07:11:41Z","selfLink":"/api/v1beta1/endpoints/apache2-service?namespace=default","resourceVersion":14119,"apiVersion":"v1beta1","namespace":"default","endpoints":["10.100.83.5:80"]}
$ etcdctl get /registry/services/specs/default/apache2-service
{"kind":"Service","id":"apache2-service","uid":"07cc9702-c3d0-11e4-b06e-0800272b69e4","creationTimestamp":"2015-03-06T07:11:37Z","apiVersion":"v1beta1","namespace":"default","port":9090,"protocol":"TCP","selector":{"name":"apache2"},"containerPort":80,"portalIP":"10.100.62.248","sessionAffinity":"None"}
可以看到,一些相关信息都会被记录到etcd中。
Service 的 VIP 只是一条 iptables 规则上的配置,并没有真正的网络设备,所以你 ping 这个地址,是不会有任何响应的。
A service, through its label selector(a key:value pair), can resolve to 0 or more pods. Over the life of a service, the set of pods which comprise that service can grow, shrink, or turn over completely. Clients will only see issues if they are actively using a backend when that backend is removed from the service (and even then, open connections will persist for some protocols).
kubernetes和kubernetes-ro
kubernetes启动时,默认有两个服务kubernetes和kubernetes-ro
$ kubectl get services
NAME LABELS SELECTOR IP PORT
kubernetes component=apiserver,provider=kubernetes <none> 10.100.0.2 443
kubernetes-ro component=apiserver,provider=kubernetes <none> 10.100.0.1 80
Kubernetes uses service definitions for the API service as well(kubernete中的pod可以通过10.100.0.1:80/api/xxx来向api server发送控制命令,kubernetes-ro可操作的api应该都是只读的).
PublicIPs
service configure文件中有一个PublicIPs属性
{
"id": "myapp",
"kind": "Service",
"apiVersion": "v1beta1",
"selector": {
"app": "example"
},
"containerPort": 9376,
"port": 8765
"PublicIPs": [192.168.56.102,192.168.56.103]
}
在这里192.168.56.102和192.168.56.103是k8s集群从节点的ip(主节点ip不行)。这样,我们就可以通过192.168.56.102:8765和192.168.56.102:8765来访问这个service了。其好处是,kube-proxy为我们映射的端口是确定的。
NodePort
所谓 Service 的访问入口,其实就是每台宿主机上由 kube-proxy 生成的 iptables 规则,以及 kube-dns 生成的 DNS 记录。而一旦离开了这个集群,这些信息对用户来说,也就自然没有作用了。比如,一个集群外的host 对service vip 一点都不感冒。
Ingress
Ingress 示例
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: cafe-ingress
spec:
tls:
- hosts:
- cafe.example.com
secretName: cafe-secret
rules:
- host: cafe.example.com
http:
paths:
- path: /tea
backend:
serviceName: tea-svc
servicePort: 80
- path: /coffee
backend:
serviceName: coffee-svc
servicePort: 80
host 字段定义的值,就是这个 Ingress 的入口,当用户访问 cafe.example.com 的时候,实际上访问到的是这个 Ingress 对象。每一个 path 都对应一个后端 Service
一个 Ingress 对象的主要内容,实际上就是一个“反向代理”服务(比如:Nginx)的配置文件的描述。
Ingress Controller 部署和实现
Ingress和Pod、Servce等等类似,被定义为kubernetes的一种资源。本质上说Ingress只是存储在etcd上面一些数据,我们可以通过kubernetes的apiserver添加删除和修改ingress资源。真正让整个Ingress运转起来的一个重要组件是Ingress Controller,但并不像其它Controller一样作为kubernetes的核心组件在master启动的时候一起启动起来
部署 Nginx Ingress Controllerkubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/master/deploy/mandatory.yaml
在上述 YAML 文件中,我们定义了一个使用 nginx-ingress-controller 镜像的 Pod,这个 Pod 本身,就是一个监听 Ingress 对象以及它所代理的后端 Service 变化的控制器。
当一个新的 Ingress 对象由用户创建后,nginx-ingress-controller 就会根据Ingress 对象里定义的内容,生成一份对应的 Nginx 配置文件(/etc/nginx/nginx.conf),并使用这个配置文件启动一个 Nginx 服务。而一旦 Ingress 对象被更新,nginx-ingress-controller 就会更新这个配置文件。如果这里只是被代理的 Service 对象被更新,nginx-ingress-controller 所管理的 Nginx 服务是不需要重新加载(reload)的,因为其通过Nginx Lua方案实现了 Nginx Upstream 的动态配置。
具体实现参见 扩展Kubernetes
其它材料
Kubernetes networking 101 – Services
Kubernetes networking 101 – (Basic) External access into the cluster
Kubernetes Networking 101 – Ingress resources
Getting started with Calico on Kubernetes(未读)My goal with these posts has been to focus on the primitives and to show how a Kubernetes cluster handles networking internally as well as how it interacts with the upstream or external network.