简介
索引
全文索引
红黑树
基本要点:BST,Balanced BST,Red-Black Tree
- 二叉树在插入的时候会导致树倾斜,不同的插入顺序会导致树的高度不一样,而树的高度直接的影响了树的查找效率。平衡树在插入和删除的时候,会通过旋转操作将高度保持在logN。具有代表性的平衡树分别为AVL树和红黑树。AVL树由于实现比较复杂,而且插入和删除性能差,在实际环境下的应用不如红黑树。
- 二叉树通过旋转保持平衡,旋转算法是不同树的具有区分性的特质之一。红黑树通过引入颜色的概念,通过颜色这个约束条件的使用来保持树的高度平衡。
| 插入维持平衡 | 删除维持平衡 | |
|---|---|---|
| 二叉树 | 旋转 | 旋转 |
| B+Tree | 节点的分裂、元素的上浮 | 向兄弟节点借元素、合并节点、元素的下沉 |
二叉树与高阶(一个节点多于2个叉)树不同在于,高阶树中每个节点元素的个数,为旋转算法提供了决策依据,体现在:
- 是否需要分裂合并等操作
- 大多数时候,一个插入和删除操作影响节点本身、父亲和兄弟节点,通过父节点元素个数,可以简单的判断是否波及其他节点。
而对于二叉树来说,这些都可以实现,大不了整棵树遍历一遍。但没有类似于“节点个数”(因为都是一个)这样直接的信息来提供决策,这也是为什么说“AVL树实现比较复杂”的原因吧。红黑树,节点的颜色标记,估计与“节点个数”有异曲同工的作用。有一句话说,“纠结的原因通常是因为掌握的信息不够(或信息获取比较难)”,其存在标识一种平衡状态,通过局部的直接判断,即可进行旋转决策。
事务
《软件架构设计》通俗的讲,事务就是一个“代码块”,这个代码块要么不执行,要么全部执行。事务要操作数据(数据库里面的表),事务与事务之间会存在并发冲突,就好比在多线程编程中,多个线程操作同一份儿数据,存在线程间的并发冲突是一个道理。
理解事务 - MySQL 事务处理机制基本要点(太经典,要低水平的复制粘贴了):
重新理解一致性:在事务T开始时,此时数据库有一种状态,这个状态是所有的MySQL对象处于一致的状态,例如数据库完整性约束正确,日志状态一致等,当事务T提交后,这时数据库又有了一个新的状态,不同的数据,不同的索引,不同的日志等,但此时,约束,数据,索引,日志(binlog/redo/undo log)等MySQL各种对象还是要保持一致性(正确性)。 这就是 从一个一致性的状态,变到另一个一致性的状态。也就是事务执行后,并没有破坏数据库的完整性约束。有分布式一致性,其实一致性问题分布式和单机都有。
事务的原子性和持久性——redo/undo log
一次事务实际执行的伪代码
start transaction
写undo log1: 备份该行数据(update)
update 表1某行记录
写redo log1
写undo log2:备份该行数据(insert)
delete 表1某行记录
写redo log2
写undo log3:该行的主键id(delete)
insert 表2某行记录
写redo log3
commit
![]()
InnoDB将Undo Log看作数据,因此记录Undo Log的操作也会记录到redo log中,包含Undo Log操作的Redo Log,看起来是这样的:
记录1: <trx1, Undo log insert <undo_insert …>>
记录2: <trx1, insert …>
记录3: <trx2, Undo log insert <undo_update …>>
记录4: <trx2, update …>
记录5: <trx3, Undo log insert <undo_delete …>>
记录6: <trx3, delete …>
宕机恢复后
- 会把redo log 全部重放一遍,并不关心事务性,提交的事务和未提交的事务都被重放了,从而让数据库”原封不动“的回到宕机前的状态。
- 重放完成后,再把未完成的事务找出来,逐一利用undo log进行逻辑上的“回滚”。 undo log 记录了sql 的反操作,所谓回滚即 执行反操作sql
可以看出,redo log 不保证事务原子性, 只是保证了持久性, 不管提交未提交的事务都会进入redo log。
redo log和undo log所做的一切都是为了提高 数据本身的IO效率,已提交事务和未提交事务的数据 可以随意立即/延迟写入磁盘。代价是,事务提交时,redo log必须写入到磁盘,数据随机写转换为日志数据顺序写。PS,随机写优化为顺序写,也是一种重要的架构优化方法。
redo log
为什么需要redo log
- 数据写磁盘一般是随机的,单次较慢,也不允许频繁写入
- 数据写入一般先保存在内存中,然后定期将内存数据写入到磁盘
- 磁盘的顺序写性能较高,所以采用Write-Ahead log机制,将日志顺序持久化到磁盘。Write-Ahead log 就是redo log
在支付业务中,有一个用户账户表,还会有一个用户账户临时表,更新用户账户的金额数据时,经常先在临时表中先插入一条日志,因为只有插入操作,自然没有并发问题,然后再去更新用户账户。此时,临时表的作用就类似于redo日志。
![]()
应用层所说的事务都是”逻辑事务“,以上图为例,在逻辑层面事务是三条sql语句,涉及两张表。在物理层面,可能是修改了两个Page,修改每个page 产生一部分日志,生成一个LSN,存储到Redo log 的Block 里。不同事务的日志在 redo log 中是交叉存在的。
redo log 的格式
从逻辑上来说,日志就是一个无限延长的字节流,从数据库启动开始,日志便源源不断的追加,直到结束。但从物理上来看,日志不可能是一个永不结束的字节流, 磁盘是块设备,磁盘的读取和写入都是不是按照一个个字节来处理的,日志文件不可能无限膨胀,过了一定时间,之前的历史日志就不需要了。
存储格式:physiological logging
I/O 写入的原子性
要实现事务的原子性,先得考虑磁盘I/O的原子性。 一个Log block 是512 byte,os 一次write 写一半宕机了,怎么办?可以通过在日志中加入checksum 解决,宕机后重启,可以通过check sum 来判断一个Log block 是否完整,不完整则丢弃。
数据 page(16kb) 的写入也有类似问题,可以使用double write 等技术解决。
笔者的个人感受:一个大粒度的原子性,终究会归结到一个小粒度的原子性。基于小粒度的原子性上添加各种机制(说白了就是成就成,不成就重试,再不成就报错),可以支持大粒度的原子性。
undo log
undo log 不是log,而是数据,每个事务在修改记录之前,都会先把该记录拷贝出来一份,存在undo log里,也就是copyOnWrite。也正因为每条记录都有多个版本,才很容易实现隔离性。同时修改同一条数据是不可能的,只能读取历史版本。事务提交后,没用其它事务引用的“历史版本/undo log”就可以删除了。PS:跟cpu 缓存导致一条内存数据多个cpu 副本异曲同工
数据库的并发安全
本文是innodb的读书笔记,更宏观的看待并发问题请参考腾讯云李海翔:数据库的并发控制技术深度探索基本要点:
- 数据库一共会发生11种异常现象,脏读、不可重复读、幻读只是其中三种。
-
主流的并发控制技术
- 两阶段锁
- 基于时间戳
- 基于有效性检查
- MVCC,常与其它技术一起使用
- SCO
所谓并发控制技术就是抑制并发,或者发现数据异常并处理。 使各种共享资源在被并发访问变得有序所设计的一种规则
《软件架构设计》软件并发问题其实就是读写、写写冲突问题,读写冲突又可以细分为快照读与写冲突、当前读与写冲突
| 并发冲突 | 处理办法 | 示例 |
|---|---|---|
| 读读 | 无冲突 | |
| 快照读与写 | copyOnWrite/MVCC | select xx from xx |
| 当前读与写 | 加锁,但锁有强弱(互斥、读写),粒度有大小(表、行、范围),锁住的对象有不同(索引、数据行) 可以根据容忍的读错误类型加不同的锁 |
select xx for udpate select xx in share mode |
| 写写 | 加锁 |
事务的隔离性与一致性——MVCC与锁
mysql 作为一个数据库,其实就是sql的 解释执行器,这一点和jvm 作为字节码的解释执行器是一样一样的。但跟java语言层面的并发安全又有所不同,java语言层面就两个安全级别:安全,不安全。目的是为了保证一致性,但绝对的一致性要损失性能,因此允许某些异常便产生一致性强弱的区别,抽出几个常见的数据异常问题划分隔离性,总比不可重复读等说一堆,减少了沟通成本。一般mysql 引擎仅实现部分并发安全。隔离性描述了并发安全程度
| 事务 | 加解锁阶段 |
|---|---|
| begin; | 获取唯一自增的事务id等操作 |
| insert… | 加insert对应的锁 |
| update… | 加update对应的锁 |
| delete… | 加delete对应的锁 |
| commit; | 事务提交时,同时释放insert、update、delete对应的锁 |
- 可以看到,begin和commit除了标记一个事务的开始与结束外,在数据库实现中,是有对应的操作意义的。
-
具体到不同的sql 语句、不同的事务并发场景、不同的事务隔离级别、不同的索引类型,是不是加锁(比如用MVCC即可)、加的锁都可能不一样。
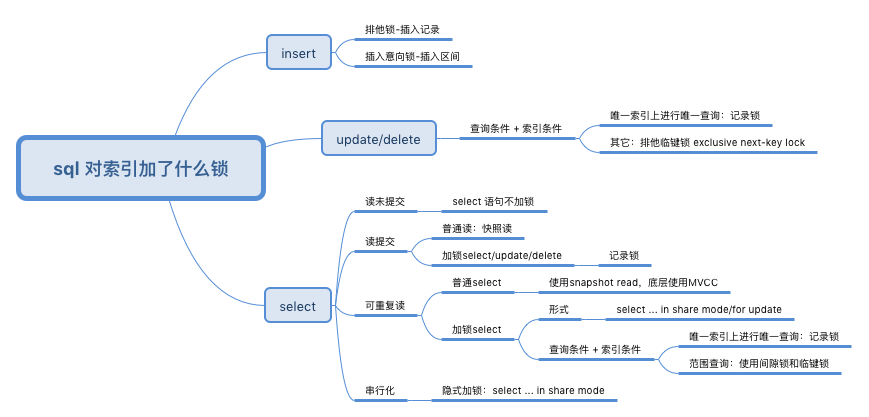
锁的实现
书中提到,在数据库中,锁有lock和latch,一般业务开发熟悉的锁对应的是latch,简单区别如下:
| 对象 | 保护 | 持续时间 | 存在于 | |
|---|---|---|---|---|
| lock | 事务 | 表、页、行 | 整个事务过程 | lock manager的哈希表中 |
| latch | 线程 | 内存数据结构 | 很短 | 被保护的数据结构中 |
比如在java中,一个object内存结构就相应有锁的标记位,意味着任何一个object都有可能被竞争访问,如果object已经被锁住(标记位是某个值),则线程会被挂起。
其实,锁的标记信息存储在被保护的数据结构上还是独立集中管理,都是一样的。
- 在操作系统中,一个文件在磁盘上的存在形式是一个个磁盘块,在内存中的存在形式除了磁盘块载入内存的缓冲块外,还有一个文件表,表中的文件结构体有锁的标志位。文件是否被某个线程独占,并不属于文件的内容信息,存入磁盘中是不恰当的。如果锁的信息存入磁盘块对应的缓冲块,则破坏了缓冲块与磁盘块的直接对应关系。
- 每个数据结构保有锁的标记信息有一个好处,即语言层面简化锁的使用,比如java的synchronized关键字, 比
lock unlock方便多了。
上层应用开发会加各种锁,有些锁是隐式的,数据库会主动加(比如update),有些锁是显式的,比如select xx for update。 因为开发的使用不当,数据库会发生死锁,就像jvm 也会死锁一样。作为数据库,必须有机制检测出死锁(判断一个有向图是否存在环),并解决死锁问题,比如强制让其中某个事务回滚,释放锁。
线程阻塞 还是事务 阻塞
文中提到 “事务会阻塞”,而不是我们常说的 “线程会阻塞”,这种 表述是不是意味着,执行事务的线程 如果发现事务阻塞了,就可以转而执行其它事务, 就像goroutine 那样? 从 MySQL锁阻塞分析,mysql锁阻塞 可以看到,就实现上来说, 事务阻塞也就意味着 执行事务的线程阻塞。进而可以推断,并发读写比较多时,会导致大量的数据库线程在同一时间处于阻塞状态,进而拖慢 数据库执行 任务队列中事务的速度。
$ show engine innodb status
------------
TRANSACTIONS
------------
Trx id counter 4131
Purge done for trx's n:o < 4119 undo n:o < 0 state: running but idle
History list length 126
LIST OF TRANSACTIONS FOR EACH SESSION:
---TRANSACTION 0, not started
MySQL thread id 2, OS thread handle 0x7f953ffff700, query id 115 localhost root init
show engine innodb status
---TRANSACTION 4130, ACTIVE 41 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 2 lock struct(s), heap size 360, 1 row lock(s)
MySQL thread id 4, OS thread handle 0x7f953ff9d700, query id 112 localhost root updating
delete from emp where empno=7788
------- TRX HAS BEEN WAITING 41 SEC FOR THIS LOCK TO BE GRANTED: ## 等待了41s
RECORD LOCKS space id 16 page no 3 n bits 88 index `PRIMARY` of table `test`.`emp` trx id 4130 lock_mode X locks rec but not gap waiting
Record lock, heap no 9 PHYSICAL RECORD: n_fields 10; compact format; info bits 0 ## 线程4在等待往test.emp中的主键上加X锁,page num=3
0: len 4; hex 80001e6c; asc l;;
1: len 6; hex 000000001018; asc ;;
2: len 7; hex 91000001420084; asc B ;;
3: len 5; hex 53434f5454; asc SCOTT;;
4: len 7; hex 414e414c595354; asc ANALYST;;
5: len 4; hex 80001d8e; asc ;;
6: len 4; hex 208794f0; asc ;;
7: len 4; hex 80000bb8; asc ;;
8: SQL NULL;
9: len 4; hex 80000014; asc ;;
------------------
---TRANSACTION 4129, ACTIVE 45 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 2 lock struct(s), heap size 360, 1 row lock(s)
MySQL thread id 7, OS thread handle 0x7f953ff6c700, query id 111 localhost root updating
update emp set sal=3500 where empno=7788
------- TRX HAS BEEN WAITING 45 SEC FOR THIS LOCK TO BE GRANTED: ## 等待了45s
RECORD LOCKS space id 16 page no 3 n bits 88 index `PRIMARY` of table `test`.`emp` trx id 4129 lock_mode X locks rec but not gap waiting
Record lock, heap no 9 PHYSICAL RECORD: n_fields 10; compact format; info bits 0 ## 线程7在等待往test.emp中的主键上加X锁,page num=3
0: len 4; hex 80001e6c; asc l;;
1: len 6; hex 000000001018; asc ;;
2: len 7; hex 91000001420084; asc B ;;
3: len 5; hex 53434f5454; asc SCOTT;;
4: len 7; hex 414e414c595354; asc ANALYST;;
5: len 4; hex 80001d8e; asc ;;
6: len 4; hex 208794f0; asc ;;
7: len 4; hex 80000bb8; asc ;;
8: SQL NULL;
9: len 4; hex 80000014; asc ;;
------------------
---TRANSACTION 4128, ACTIVE 51 sec
2 lock struct(s), heap size 360, 1 row lock(s)
MySQL thread id 3, OS thread handle 0x7f953ffce700, query id 110 localhost root clean
从show engine innodb status 输出可以看到, 一个事务id 通常 对应一个 thread id。
数据库和文件系统
书中有多处提到数据库和文件系统的关系:
- 事务是数据库区别于文件系统的重要特性之一
- 数据库的主要任务就是协调对数据记录的并发访问