简介(未完成)
为什么要监控
参见 容器狂打日志怎么办?
容器监控和Kubernetes监控不一样
Kubernetes监控在小米的落地 为了更方便的管理容器,Kubernetes对Container进行了封装,拥有了Pod、Deployment、Namespace、Service等众多概念。与传统集群相比,Kubernetes集群监控更加复杂:
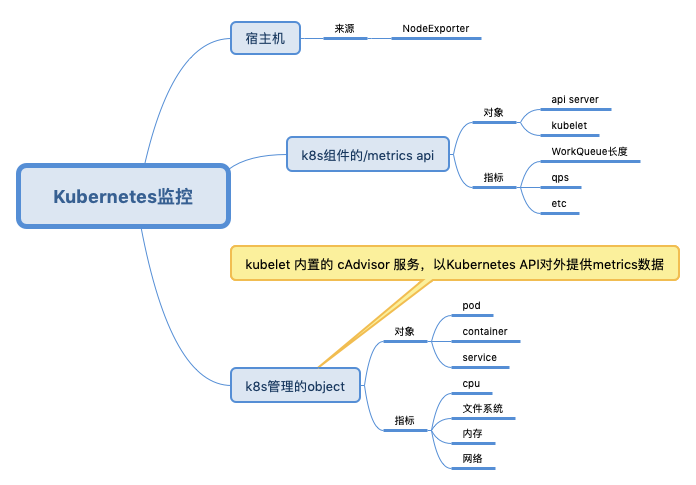
- 监控维度更多,除了传统物理集群的监控,还包括核心服务监控(apiserver,etcd等)、容器监控、Pod监控、Namespace监控等。
- 监控对象动态可变,在集群中容器的销毁创建十分频繁,无法提前预置。
- 监控指标随着容器规模爆炸式增长,如何处理及展示大量监控数据。
- 随着集群动态增长,监控系统必须具备动态扩缩的能力。
监控什么
类似于Prometheus的pull理念,应用要自己暴露出一个/metrics,而不是单纯依靠监控组件从”外面“ 分析它
- 依靠现成组件提供 通用metric
- 自己实现
自定义监控指标
在过去的很多 PaaS 项目中,其实都有一种叫作 Auto Scaling,即自动水平扩展的功能。只不过,这个功能往往只能依据某种指定的资源类型执行水平扩展,比如 CPU 或者 Memory 的使用值。而在真实的场景中,用户需要进行 Auto Scaling 的依据往往是自定义的监控指标。比如,某个应用的等待队列的长度,或者某种应用相关资源的使用情况。
已有方案
Heapster/Metrics-Server+ InfluxDB + Grafana
只适用于监控集群中各容器的资源信息,无法对Kubernetes集群整体监控
Exporter+Prometheus+Adapter
Kubernetes的核心组件提供了Prometheus的采集接口
可以根据监控数据做什么
- 根据容器内存的耗费统计,个性化容器的内存 limit
- cpu 负载过高时,报警提醒
- 混部
- Auto Scaling