简介
一种新的模型
Kubernetes: Controllers, Informers, Reflectors and Stores
We really like the Kubernetes ideology of seeing the entire system as a control system. That is, the system constantly tries to move its current state to a desired state.The worker units that guarantee the desired state are called controllers.
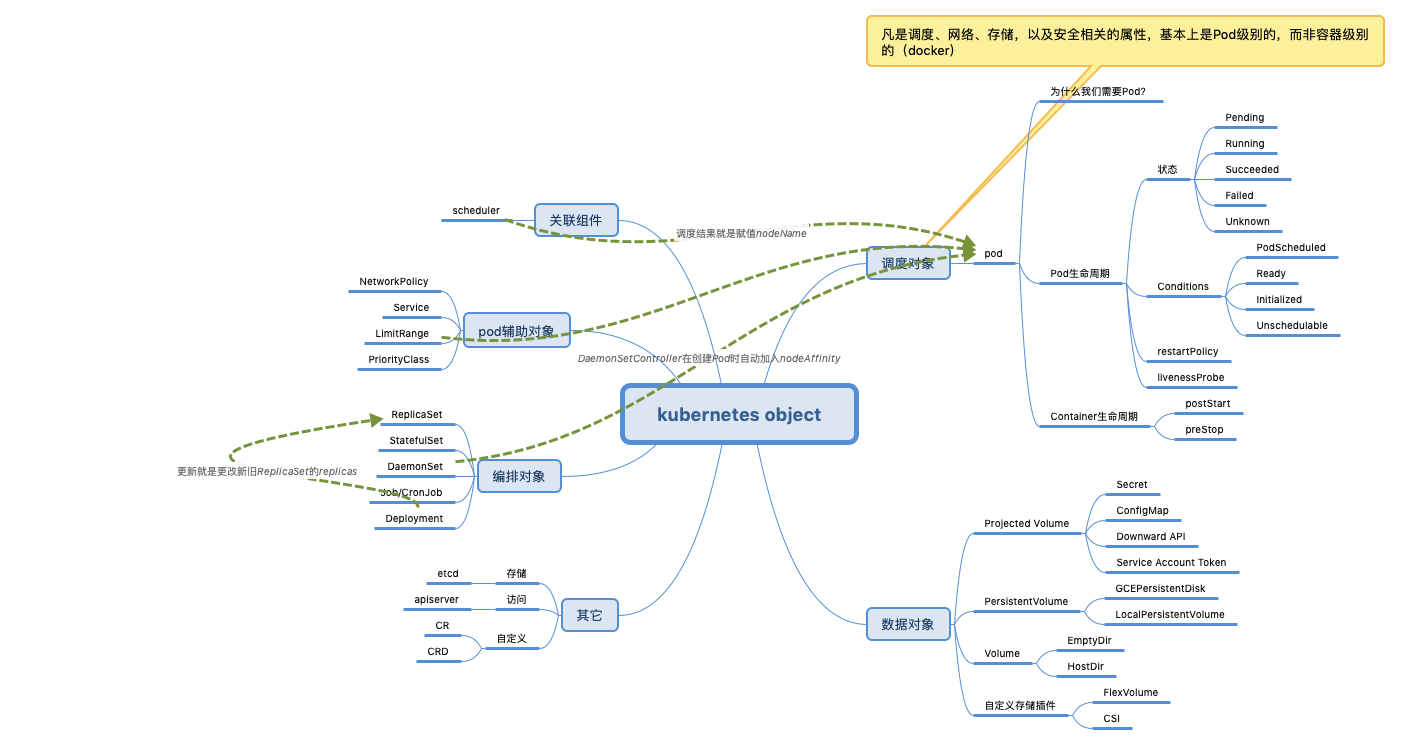
一切操作皆对象
在 Kubernetes 中,在编写 Pod 模板的时候,有一种“在 YAML 文件里编程序”的感觉
控制器模型
kube-controller-manager In applications of robotics and automation, a control loop is a non-terminating loop that regulates the state of the system(在自动化行业是常见方式). In Kubernetes, a controller is a control loop that watches the shared state of the cluster through the API server and makes changes attempting to move the current state towards the desired state. Examples of controllers that ship with Kubernetes today are the replication controller, endpoints controller, namespace controller, and serviceaccounts controller.
docker是单机版的,当我们接触k8s时,天然的认为这是一个集群版的docker,再具体的说,就在在集群里给镜像找一个主机来运行容器。经过 《深入剖析kubernetes》笔记的学习,很明显不是这样。比调度更重要的是编排,那么编排如何实现呢?控制器
有什么
controller是一系列控制器的集合,不单指RC。
$ cd kubernetes/pkg/controller/
$ ls -d */
deployment/ job/ podautoscaler/
cloud/ disruption/ namespace/
replicaset/ serviceaccount/ volume/
cronjob/ garbagecollector/ nodelifecycle/ replication/ statefulset/ daemon/
...
控制器是declarative API的重要组成部分,declarative API的内涵参见Kubernetes源码分析——apiserver
整体逻辑
这些控制器之所以被统一放在 pkg/controller 目录下,就是因为它们都遵循 Kubernetes 项目中的一个通用编排模式,即:控制循环(control loop)。 (这是不是可以解释调度器 和控制器 不放在一起实现,因为两者是不同的处理逻辑,或者说编排依赖于调度)
for {
实际状态 := 获取集群中对象 X 的实际状态(Actual State)
期望状态 := 获取集群中对象 X 的期望状态(Desired State)
if 实际状态 == 期望状态{
什么都不做
} else {
执行编排动作,将实际状态调整为期望状态
}
}
实际状态往往来自于 Kubernetes 集群本身。 比如,kubelet 通过心跳汇报的容器状态和节点状态,或者监控系统中保存的应用监控数据,或者控制器主动收集的它自己感兴趣的信息。而期望状态,一般来自于用户提交的 YAML 文件。 比如,Deployment 对象中 Replicas 字段的值,这些信息往往都保存在 Etcd 中。

Kubernetes 使用的这个“控制器模式”,跟我们平常所说的“事件驱动”,有点类似 select和epoll的区别。控制器模型更有利于幂等。
- 对于控制器来说,被监听对象的变化是一个持续的信号,比如变成 ADD 状态。只要这个状态没变化,那么此后无论任何时候控制器再去查询对象的状态,都应该是 ADD。
- 而对于事件驱动来说,它只会在 ADD 事件发生的时候发出一个事件。如果控制器错过了这个事件,那么它就有可能再也没办法知道ADD 这个事件的发生了。
实现
A Deep Dive Into Kubernetes Controllers
Controller获取数据——pull vs watch
控制器与api server的关系,从拉取到监听:In order to retrieve an object’s information, the controller sends a request to Kubernetes API server.However, repeatedly retrieving information from the API server can become expensive. Thus, in order to get and list objects multiple times in code, Kubernetes developers end up using cache which has already been provided by the client-go library. Additionally, the controller doesn’t really want to send requests continuously. It only cares about events when the object has been created, modified or deleted.
Controller处理数据——独占 vs 共享
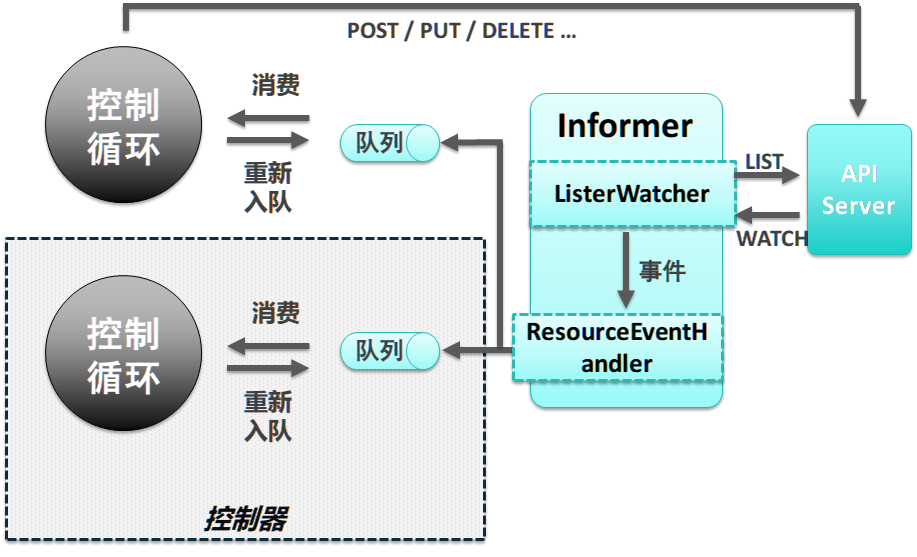
起初是一个controller 一个informer,informer 由两个部分组成
- Listwatcher is a combination of a list function and a watch function for a specific resource in a specific namespace.
-
Resource Event Handler is where the controller handles notifications for changes on a particular resource
type ResourceEventHandlerFuncs struct { AddFunc func(obj interface{}) UpdateFunc func(oldObj, newObj interface{}) DeleteFunc func(obj interface{}) }
The informer creates a local cache of a set of resources only used by itself.But, in Kubernetes, there is a bundle of controllers running and caring about multiple kinds of resources. This means that there will be an overlap - one resource is being cared by more than one controller. 但一个Controller 一个informer 引起了巨大的浪费:信息重复;api server 负载/连接数提高;序列化反序列化成本。
SharedInformer,因为SharedInformer 是共享的,所以其Resource Event Handler 也就没什么业务逻辑,Whenever a resource changes, the Resource Event Handler puts a key to the Workqueue. 这个Workqueue 支持优先级等高级特性
控制器的关键分别是informer/SharedInformer和Workqueue,前者观察kubernetes对象当前的状态变化并发送事件到workqueue,然后这些事件会被worker们从上到下依次处理。