前言
到目前为止,关于docker网络的博客写了四篇,零零碎碎,那时docker libnetwork还没有推出,cnm概念也没人提,大家自己基于底层工具弄个神器(比如pipework之于iproute),或者利用现有工具(比如ovs)整个互联互通的方案,我们把过去的经验和方法汇总汇总,提出一些概念性的东西,从更高的角度来看待docker网络方面的一些技术。(毛选中的大部分文章,就是毛主席在经历了一段时间的观察后,对过去的经验教训加以总结和概括,再进一步指导实践。)
本文章主要针对跨主机容器互联问题
A Docker container created using an image works the same regardless of where it runs as long as the same image is used. Similarly, when the application developer defines their application stack as a set of distributed applications, it should work just the same whatever infrastructure it runs on.(一个容器可以处处运行,延伸的说,我定义了一个分布式应用,也应能处处运行,而不管底层架构的差异) This heavily depends on what abstractions we expose to the application developer and more importantly what abstractions we do not expose to the application developer.
单机网络模型
图解几个与Linux网络虚拟化相关的虚拟网卡-VETH/MACVLAN/MACVTAP/IPVLAN
Linux 用户想要使用网络功能,不能通过直接操作硬件完成,而需要直接或间接的操作一个 Linux 为我们抽象出来的设备,既通用的 Linux 网络设备来完成。一个常见的情况是,系统里装有一个硬件网卡,Linux 会在系统里为其生成一个网络设备实例,如 eth0,用户需要对 eth0 发出命令以配置或使用它了。更多的硬件会带来更多的设备实例,虚拟的硬件也会带来更多的设备实例。
| host1 | host2 | ||||
| root network namespace | network namespace 1 | network namespace 2 | root network namespace | root network namespace | |
| 网络层 | 网络协议栈 | 网络协议栈 | 网络协议栈 | 网络协议栈 | 网络协议栈 |
| 网卡设备 | 物理网卡 | MACVLAN网卡 | 虚拟网卡 | 物理网卡 | 物理网卡 |
| 连通网卡设备/容器 | 交换机(支持macvlan) | 网桥 | |||
| 跨主机网卡设备 | 交换机 | ||||
单单在一个主机内,实现数据在宿主网卡和虚拟网卡之间的连通,就有bridge、bonding、macvlan和ipvlan等方式。
汇总下就是,两个network namespace连通的几个办法:
| 备注 | 单机状态 | 跨主机状态 | |
|---|---|---|---|
| 通过veth pair连通 | 只能两两连通 | 不支持 | |
| 通过网桥连通 | 相当于内置switch | 支持 | 通过下文的隧道或路由方案 |
| 通过macvlan vepa连通 | 外置switch | 支持 | 支持 |
CNM
涉及到的知识点
- 网络的基础知识,比如一些网络拓扑结构,网络节点的原理和作用
- 虚拟网络(或sdn)的基础知识,实现网络虚拟化的一些原理和手段
- linux网络的基础知识,网络协议栈、iptable表、路由表以及linux对网络设备的虚拟化
- docker网络的基础知识,network namespace,network driver等
2018.2.24 新增
docker 网络这块,强烈推荐一本gitbook,SDN网络指南,其内容包括网络知识的方方面面
- 网络基础
- SDN网络
- 容器网络
- Linux网络
- OVS以及DPDK
- SD-WAN
- NFV
- 实践案例
知识点之间的相互关系
cnm将上述不同的知识点进行了划分。
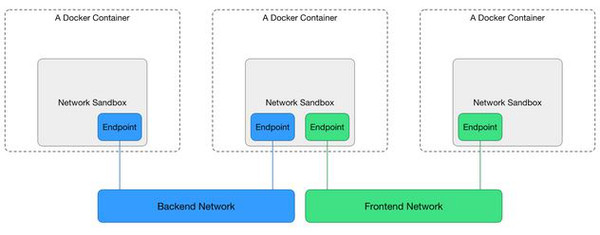
- Sandbox:对应一个容器内的网络环境(没有实体),包括相应的网卡配置、路由表、DNS配置等。CNM很形象的将它表示为网络的『沙盒』,因为这样的网络环境是随着容器的创建而创建,又随着容器销毁而不复存在的; 对应的实现如:Linux Network Namespace;一个Sandbox可以包含多个Network;
- Endpoint:实际上就是一个容器中的虚拟网卡,做为Sandbox接入Network的介质,对应的实现如:veth pair、TAP、macvlan设备等;一个Endpoint只能属于一个Network,也只能属于一个Sandbox;
- Network:一组可以相互通信的Endpoints;对应的实现如:Linux bridge、VLAN;
we segmented the plugin API into separate extension points corresponding to logical configuration groupings:
- The network driver extension point provides the API needed to configure and achieve network connectivity
- The IPAM extension point to configure, discover and manage IP address ranges
Docker Networking allows for separation of concerns for two different users and it was only natural to design two distinct commands in Docker UI. The UI and API are designed in a way that network IT can configure the infrastructure with as little coordination with the application developers as possible.
| user | work | detail |
|---|---|---|
| network IT | 1. create, administer and precisely control which network driver and IPAM driver combination is used for the network. 2. specify various network specific configurations like subnets, gateway, IP ranges etc.3. pass on driver specific configuration | |
| application developers | connect any container to the created network. | their concern is mainly one of connectivity and discoverability. |
CNM 和 CNI的差异
新增于2018.2.24
CNI的基本思想:Container Runtime在创建容器时,先创建好network namespace,然后调用CNI插件为这个netns配置网络,其后再启动容器内的进程。有以下几个tip
-
docker 网络模型的配置,本质有以下几个事情。通过linux 工具集(比如
ip netns exec)可以直接设置- 创建veth pair
- 为容器内veth pair 分配ip
- 为容器外veth pair 分配一个合适的地方
- 不准确的说,docker作为一个container runtime 只是创建了容器和空的network namespace,network namespace的配置是“外力” 在设置。具体到k8s,pod是运行容器的基本单位,每一个pod会有一个pause容器,k8s先配置该容器的network namespace,再启动实际的容器(共用pause的network namespace) CNI (Container Network Interface)
- 在cni模型中,docker 不再包揽容器创建的所有过程,上层编排工具介入的更多
- 在cni模型中,不再有类似cnm中原生(none、bridge、host等)和第三方插件的区别。
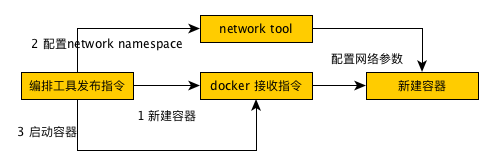
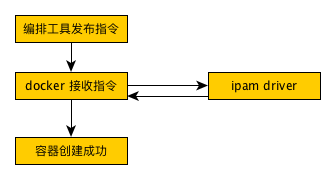
一个不准确的对比如下图所示:
cni
cnm
为容器分配ip,保持容器互通,并不是k8s/cni 介入网络的必要理由,因为docker也可以做到。它是一套组合拳,k8s中有namespace以及network-policy的概念,即想自由控制一个容器集群的不同namespace的容器是否互通。
实现方案
docker网络模型有一个基本原则:每个容器有一个ip,docker network的工作就是连通这些ip。通常状态下,容器数据无法直接通过物理网卡发送,如何实现 container_hosta ip 到container_hostb ip 可达,有以下两种方案:
隧道方案
通过隧道,或者说Overlay Networking的方式:
- Weave,UDP广播,本机建立新的BR,通过PCAP互通。
- Open vSwitch(OVS),基于VxLAN和GRE协议,但是性能方面损失比较严重。
- Flannel,UDP广播,VxLan。 隧道方案在IaaS层的网络中应用也比较多,大家共识是随着节点规模的增长复杂度会提升,而且出了网络问题跟踪起来比较麻烦,大规模集群情况下这是需要考虑的一个点。
路由方案
还有另外一类方式是通过路由来实现,比较典型的代表有:
- Calico,基于BGP协议的路由方案,支持很细致的ACL控制,对混合云亲和度比较高。
- Macvlan,从逻辑和Kernel层来看隔离性和性能最优的方案,基于二层隔离,所以需要二层路由器支持,大多数云服务商不支持,所以混合云上比较难以实现。
路由方案的基本特点是:容器的ip即为网络中流通的ip,也就不需要网络地址转换(NAT)。
calico与macvlan 的区别是:容器仍然使用物理机网卡的mac地址,macvlan中,每个容器 都是一个全新的mac地址(MACVLAN可以从一个主机接口虚拟出多个macvtap,且每个macvtap设备都拥有不同的mac地址(对应不同的linux字符设备)。)。