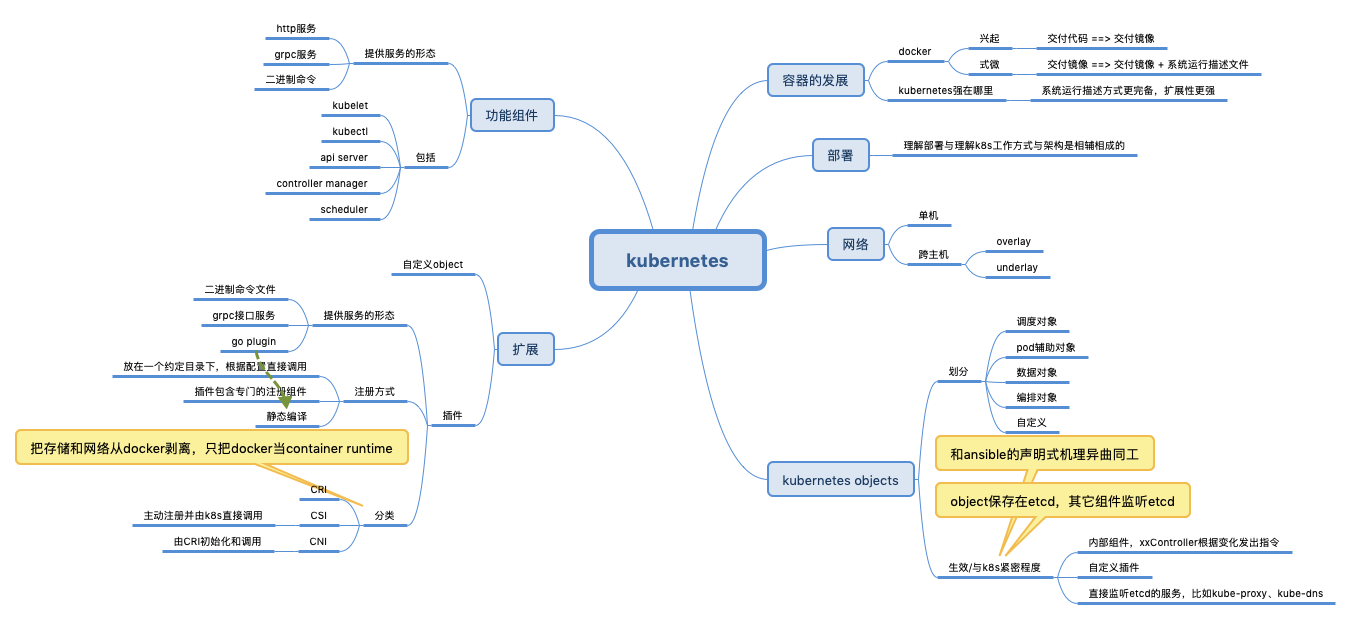
简介
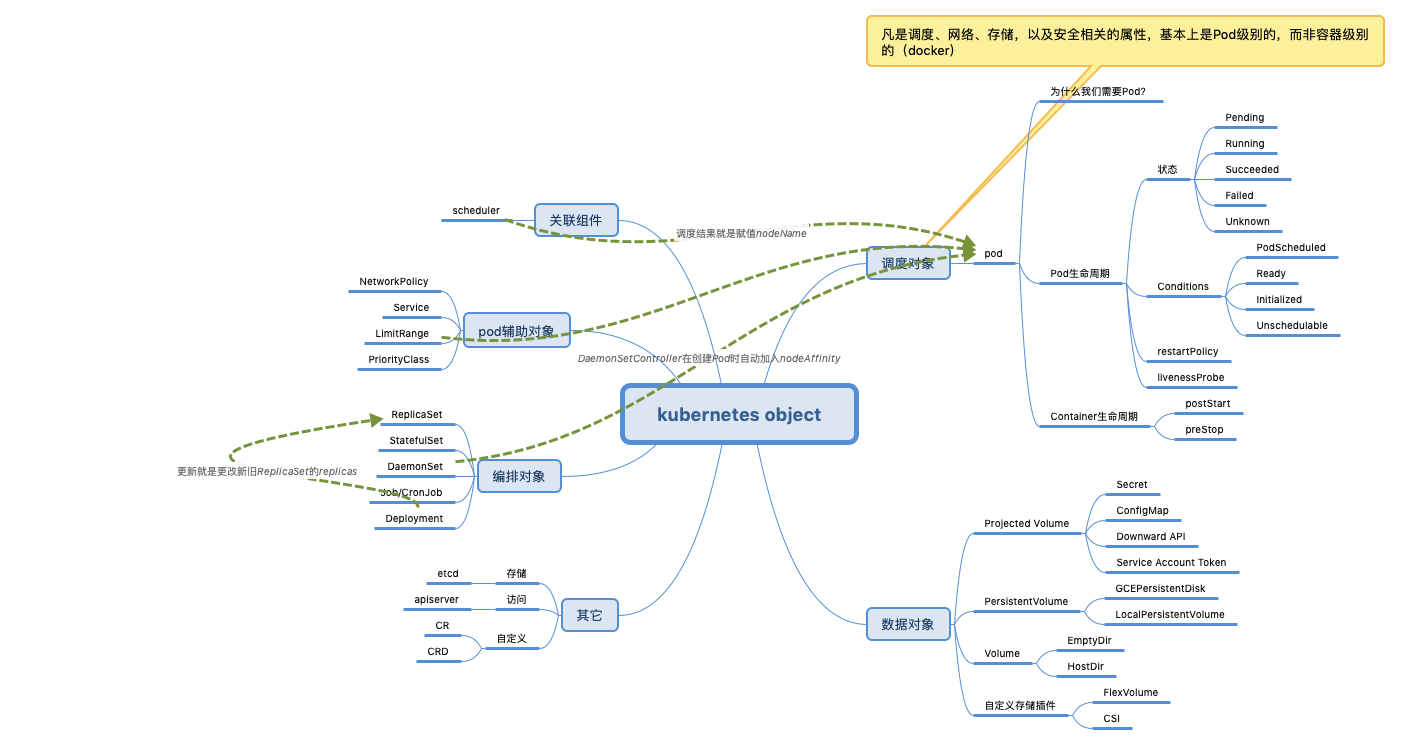
A Volume is a directory, possibly with some data in it, which is accessible to a Container. Kubernetes Volumes are similar to but not the same as Docker Volumes.
A Pod specifies which Volumes its containers need in its ContainerManifest property.
A process in a Container sees a filesystem view composed from two sources: a single Docker image and zero or more Volumes(这种表述方式很有意思). A Docker image is at the root of the file hierarchy. Any Volumes are mounted at points on the Docker image; Volumes do not mount on other Volumes and do not have hard links to other Volumes. Each container in the Pod independently specifies where on its image to mount each Volume(一个pod中的container各自挂自己的volume). This is specified a VolumeMounts property.
The storage media (Disk, SSD, or memory) of a volume is determined by the media of the filesystem holding the kubelet root dir (typically /var/lib/kubelet)(volumn的存储类型(硬盘,固态硬盘等)是由kubelet所在的目录决定的). There is no limit on how much space an EmptyDir or PersistentDir volume can consume(大小也是没有限制的), and no isolation between containers or between pods.
可以与 docker volume 对比下异同
Persistent Volume(PV)和 Persistent Volume Claim(PVC)
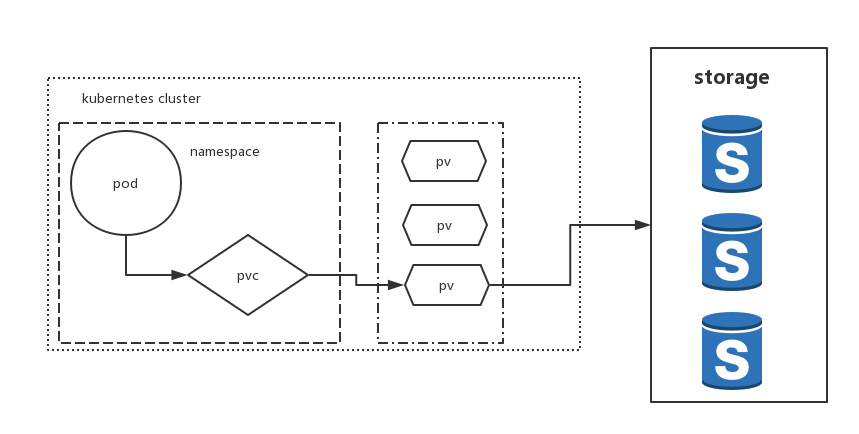
| Volume | Persistent Volume | |
|---|---|---|
| 持久性 | 有可能被 kubelet 清理掉,也不能被“迁移”到其他节点 | 不会因为容器的删除而被清理掉,也不会跟当前的宿主机绑定 |
| 依赖 | 依赖远程文件存储比如NFS、GlusterFS 远程块存储(比如,公有云提供的远程磁盘) |
|
| 载体 | 宿主机上的目录 | 宿主机上的目录,该目录同时还是一个远程文件存储比如NFS目录的挂载点 |
PVC 和 PV 的设计,其实跟“面向对象”的思想完全一致。
PV 对象是由运维人员事先创建在 Kubernetes 集群里待用的
apiVersion: v1 kind: PersistentVolume metadata: name: nfs spec: storageClassName: manual capacity: storage: 1Gi accessModes: - ReadWriteMany nfs: server: 10.244.1.4 path: “/”
PVC 对象通常由开发人员创建,描述的是 Pod 所希望使用的持久化存储的属性。
apiVersion: v1 kind: Pod metadata: labels: role: web-frontend spec: containers: - name: web image: nginx ports: - name: web containerPort: 80 volumeMounts: - name: nfs mountPath: “/usr/share/nginx/html” volumes: - name: nfs persistentVolumeClaim: claimName: nfs
PVC 可以理解为持久化存储的“接口”,它提供了对某种持久化存储的描述,但不提供具体的实现;而这个持久化存储的实现部分则由 PV 负责完成。这样做的好处是,作为应用开发者,我们只需要跟 PVC 这个“接口”打交道,而不必关心具体的实现是 NFS 还是 Ceph
在 Kubernetes 中,实际上存在着一个专门处理持久化存储的控制器,叫作 Volume Controller。这个Volume Controller 维护着多个控制循环,其中有一个循环,扮演的就是撮合 PV 和 PVC 的“红娘”的角色。它的名字叫作 PersistentVolumeController
容器持久化存储体系,完全是 Kubernetes 项目自己负责管理的,并不依赖于 docker volume 命令和 Docker 的存储插件。这跟Persistent Volume 是一致的,docker 只知道mount 本地的一个目录,至于这个目录有什么特别的,由k8s 来保证。
Dynamic Provision
Types of Volumes
目前支持三种类型
EmptyDir(仅container或container之间使用)
An EmptyDir volume is created when a Pod is bound to a Node. It is initially empty, when the first Container command starts. Containers in the same pod can all read and write the same files in the EmptyDir(这是pod之间信息共享的另一种方式). When a Pod is unbound, the data in the EmptyDir is deleted forever.
Some uses for an EmptyDir are:
- scratch space, such as for a disk-based mergesort or checkpointing a long computation.
- a directory that a content-manager container fills with data while a webserver container serves the data. Currently, the user cannot control what kind of media is used for an EmptyDir. If the Kubelet is configured to use a disk drive, then all EmptyDirectories will be created on that disk drive. In the future, it is expected that Pods can control whether the EmptyDir is on a disk drive, SSD, or tmpfs.
HostDir(和主机共同使用某个目录)
A Volume with a HostDir property allows access to files on the current node.
Some uses for a HostDir are:
- running a container that needs access to Docker internals; use a HostDir of /var/lib/docker.
- running cAdvisor in a container; use a HostDir of /dev/cgroups.
Watch out when using this type of volume, because:
- pods with identical configuration (such as created from a podTemplate) may behave differently on different nodes due to different files on different nodes.
- When Kubernetes adds resource-aware scheduling, as is planned, it will not be able to account for resources used by a HostDir.
Sample
EmptyDir
apiVersion: "v1beta1"
id: "share-apache2-controller"
kind: "ReplicationController"
desiredState:
replicas: 1
replicaSelector:
name: "share-apache2"
podTemplate:
desiredState:
manifest:
version: "v1beta1"
id: "share-apache2"
containers:
- name: "share-apache2-1"
image: "docker-registry.sh/myapp"
ports:
- containerPort: 8080
volumeMounts:
- name: data
mountPath: /data
- name: "share-apache2-2"
image: "docker-registry.sh/apache2"
ports:
- containerPort: 80
volumeMounts:
- name: data
mountPath: /data
volumes:
- name: data
source:
emptyDir: {}
labels:
name: "share-apache2"
labels:
name: "share-apache2"
此时,share-apache2-1 container对/data目录所做操作都将反映到 share-apache2-2的/data目录中。
CSI
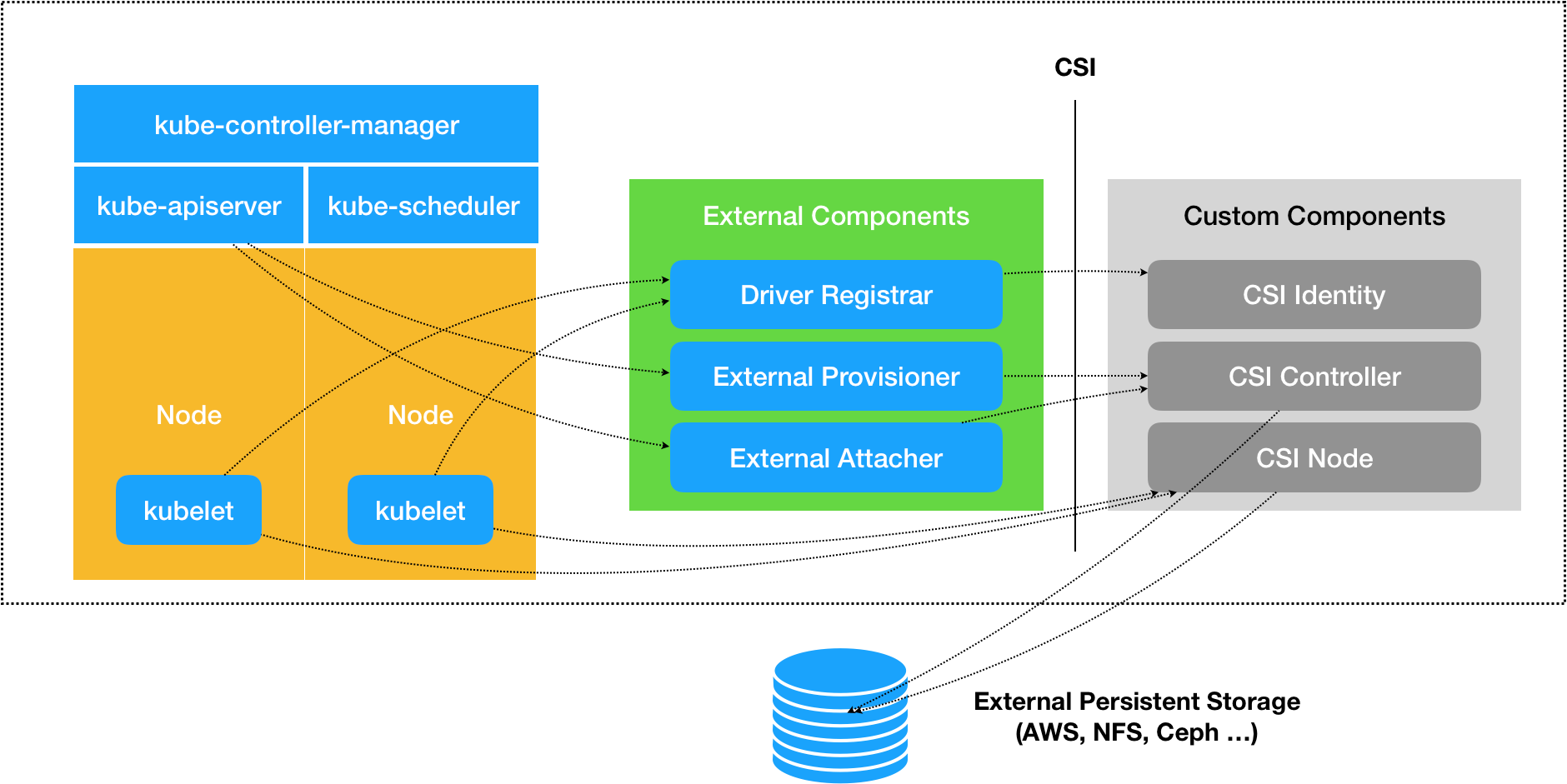
CSI 插件体系的设计思想,就是把Dynamic Provision 阶段以及 Kubernetes 里的一部分存储管理功能(比如“Attach 阶段”和“Mount 阶段”,实际上是通过调用 CSI 插件来完成的),从主干代码里剥离出来,做成了几个单独的组件。这些组件会通过 Watch API 监听 Kubernetes 里与存储相关的事件变化,比如 PVC 的创建,来执行具体的存储管理动作。
CSI 的设计思想,把插件的职责从“两阶段处理”,扩展成了Provision、Attach 和 Mount 三个阶段。其中,Provision 等价于“创建磁盘”,Attach 等价于“挂载磁盘到虚拟机”,Mount 等价于“将该磁盘格式化后,挂载在 Volume 的宿主机目录上”。
一个 CSI 插件只有一个二进制文件,但它会以 gRPC 的方式对外提供三个服务(gRPC Service),分别叫作:CSI Identity、CSI Controller 和 CSI Node。
关于k8s 插件,可以回顾下