简介
第一次接触缓存,是在学习hibernate的时候,hibernate可以将查询结果缓存起来,加快下次查询的速度。第一次自己写缓存(其实就是个map),是因为被告知某个查询操作,批量查询的效率更高,这个map用来暂存批量查询的处理结果。但要说将缓存系统作为应用服务器和数据库服务器的中间层(缓存系统作为单独的一层,并上升成为一个独立的组件),还是在学习redis的时候。
在计算机和网络领域,缓存无处不在。可以这么说,只要硬件性能不对等的地方都会有缓存的身影。
2018.4.9 cdn 也是一种变相的缓存系统。看不见摸不着的cdn是啥
缓存系统
使用缓存系统,最理想的效果是:应用系统尽量只与缓存系统交互,只有在查询缓存失败时,才访问数据库。进而,将读写压力从数据库转移到缓存系统上。
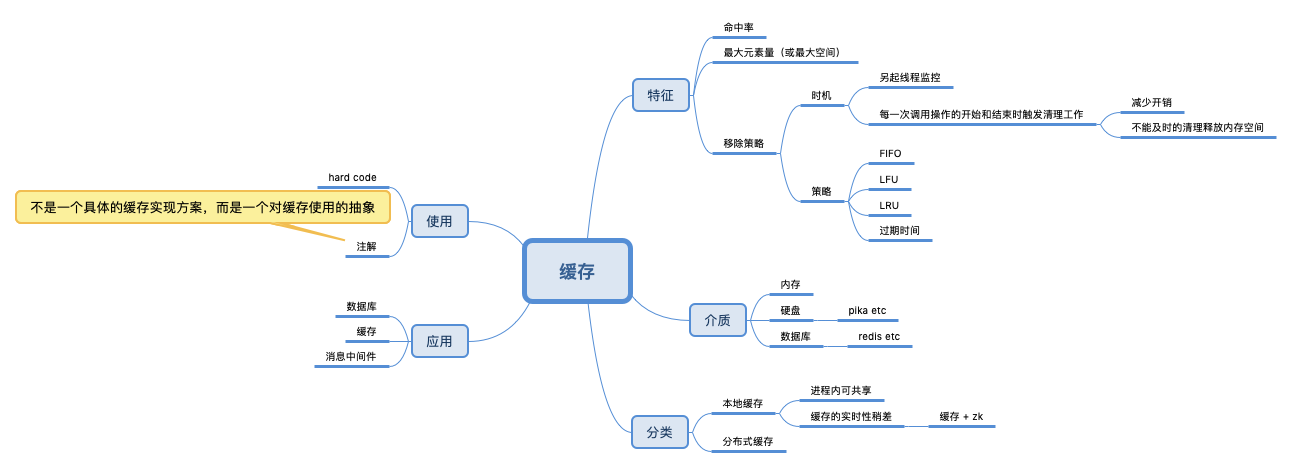
缓存系统有以下几类:
- 作为一个组件存在(或者说,本地缓存。比如一个jar提供的java类)
- 单机的、独立的应用
- 跨主机的、独立的应用
一个缓存系统应该考虑如下特性:
- 是否可以线性扩展,即通过增加主机,来增加缓存系统的存储能力,这涉及到分布式缓存系统。一旦涉及到分布式缓存系统,那么涉及到
- 如何将缓存的数据均摊到所有缓存节点
- 如果某个节点失效,如何处理
- 线程安全,在线程操作时,维护数据的一致性
- 当实际数据发生改变时,如何及时感知并更新缓存
- 如果缓存系统容量一定,当添加新的数据时,没有剩余空间,如何处理?数据是否有有效期?
- 最重要的一点,不能太复杂,如果访问延迟稍高,缓存系统便失去了存在的意义。
缓存系统与数据库的一致性
-
数据加入缓存
- 客户端查询缓存,如果缓存中没有,则查询数据库,并将查询结果加入到缓存中。
-
数据从缓存清除或更新
- 数据库中数据部分加入缓存:在向数据库写入数据的同时,告诉缓存该数据应失效
- 缓存中数据设置过期时间
缓存系统的数据模型
很多事情联系起来想很有意思,比如rpc,跨主机进程通信。然后一些大牛搞出redis,可以理解为跨主机访问内存,360推出一个pika,可以理解为跨主机访问磁盘(支持redis协议)。
跨主机通信,当然免不了网络通信协议的一些约定,这不是本文的重点,所以不多谈。不管跨主机访问内存还是磁盘,都不是提供一个byte[]让客户端随便用,而是像rpc一样,传输一些约定好的数据结构。区别是,rpc传输的数据结构描述了调用信息,redis的客户端与服务端传输的数据结构是为了存储和使用。
把一些数据结构存在本机或存在远程主机,有一些隐含的意味:
- “本机的”数据结构包括:基本数据类型,复合类型(string,list,map等)。基本数据类型往往用不着跨主机存储,因为不值当。
- 对于本地访问内存而言,访问一个数据结构要指明两个要素:内存地址和类型。内存地址说明去哪取数据,类型说明取多少数据,取出的数据如何处理。远端访问内存类似,只不过”地址“不再是一个内存地址,而是一个具备唯一性的key,由远端主机完成key到该主机的内存地址的映射。
上述逻辑或许能够解释,很多类似redis的工具为什么是key-value的,并且value可以是各种数据结构。
缓存系统带来的一些问题
-
穿透,主要有两种情况
- 比如系统刚启动时,缓存中没有数据,突如其来的大量请求直接冲过缓存访问数据库
- 对于一个热门数据,缓存中没有,在第一个线程还未完成“查询数据库,写入缓存”过程时,便有多个线程冲过缓存访问数据库
解决办法主要是做请求合并
-
非法查询,缓存中存的大多数是有效的数据,那么对于一个非法的数据(或者说合法,但数据库中没有),缓存中没有,则查询压力还是由数据库承担。