前言
TCP/IP不是一个协议,而是一个协议族的统称,里面包括了IP协议、IMCP协议、TCP协议以及我们更加熟悉的http、ftp、pop3协议等等。
TCP/IP协议族按照层次由上到下,层层包装。发送协议的主机从上自下将数据按照协议封装,而接收数据的主机则按照协议从得到的数据包解开,最后拿到需要的数据。这种结构非常有栈的味道,所以某些文章也把tcp/ip协议族称为tcp/ip协议栈。
TCP的“假”连接/状态机
《软件架构设计》在客户端与服务器之间并不存在一条可靠的“物理管道”,只是在逻辑层面,通过一定的机制,让TCP 之上的应用层就像有一个可靠地连接一样。具体的说, 每条连接用 client ip,client port,server ip,server port 唯一确定,在代码中是一个个的socket,仅在逻辑层面连接是存在的,要经历建立、数据传输、关闭阶段,要完整的维护三个阶段中连接的每种可能的状态。
TCP使用了三种基础机制来实现面向连接的服务:
- 消息顺序编号:使用序列号进行标记,以便TCP接收服务在向目的应用传递数据之前修正错序的报文排序;
- 客户端重发
- 服务端顺序ACK。服务端虽然接收数据包是并发的(数据包到达的顺序性无法保证),但数据包的ack是按照编号从小到大逐一确认的。比如服务端已收到了数据包123,又收到了567,服务端会回复ack=3,等到客户端重发4567后收到了4,才回复ack=7。这样只需一个变量,便表达了哪些数据包收到哪些未收到。顺序确认在一致性协议Raft中也有应用。
![]()
- 对于建立连接来说,都是由客户端发起,所以client 是主动方,server 是被动方。 对于关闭连接来说, client 和 server 都可以发起(通常由客户端发起)
- 起初,client 和server 都处于closed状态,连接建立好后,双方都处于established状态,开始传输数据。最后连接关闭, 双方再次回到closed状态
tcp协议字段组成
一个协议由:字段 + 基于字段之上的策略 组成
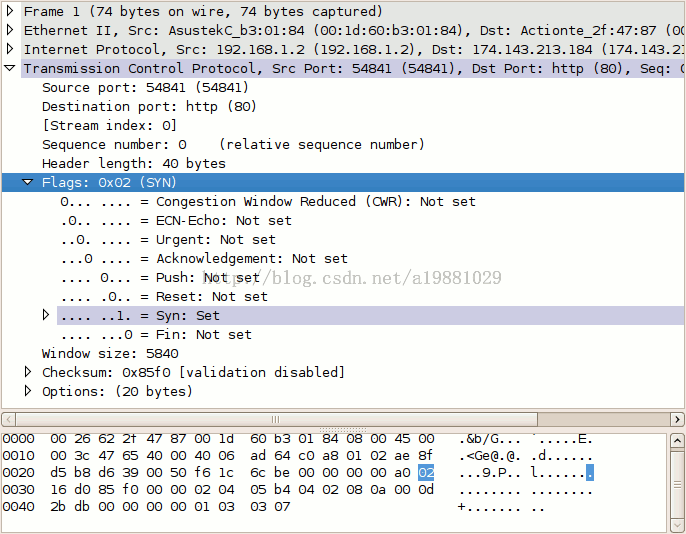
比如图中的“window size”,是不是看起来很耳熟。
序列号和确认号
TCP会话的每一端都包含一个32位(bit)的序列号,该序列号被用来跟踪该端发送的数据量。每一个包中都包含确认号,在接收端则通过确认号用来通知发送端数据成功接收。
从序列号和确认号的角度看,三次握手是这样的:
-
客户端向服务器发送一个同步数据包请求建立连接,该数据包中,初始序列号(ISN)是客户端随机产生的一个值。
-
服务器收到这个同步请求数据包后,会对客户端进行一个同步确认ACK(确认号是客户端的初始序列号+1 )。这个数据包中,序列号是服务器随机产生的一个值。
-
客户端收到这个同步确认数据包后,再对服务器进行一个确认。该数据包中,序列号是上一个同步请求数据包中的确认号值,确认号是服务器的初始序列号+1。
假设初始序列号是0(不管是客户端请求,还是服务端响应),那么序列号为当前端成功发送的数据位数,确认号为当前端成功接收的数据位数。握手过程中,尽管没有传输有效数据,确认号还是被加1,这是因为接收的包中包含SYN或FIN标志位(占1bit)。
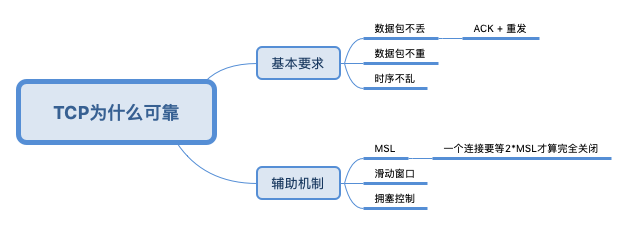
由此,我们就可以知道为什么一些linux命令可以统计流量,为什么说tcp是可靠地?序列号、确认号、checksum即可以保证交互双方正确传输了n字节的数据。序列号来保证所有传输的数据可以按照正常的顺序进行重组,从而保障数据传输的完整。
tcp连接建立与释放
tcp为了数据通信的可靠性,增加了很多操作(比如数据通信前后,要建立和释放连接),不像udp直接把包发出去就可以。
三次握手(从程序层面看,大致对应socket.connect函数)
- 客户端向服务器发送连接请求,
- 服务端向客户端发送确认
- 客户端收到服务端确认后,向服务端发送确认
为什么一定要进行三次握手呢?
前两次的握手很显然是必须的,主要是最后一次,即客户端收到服务端发来的确认后为什么还要向服务端再发送一次确认呢?这主要是为了防止已失效的请求报文段突然又传送到了服务端而产生连接的误判。
理论上:在TCP传送一个数据包时,它会把这个数据包放入重发队列中,同时启动计时器,如果收到了关于这个包的确认信息,便将此数据包从队列中删除,如果在计时器超时的时候仍然没有收到确认信息,则需要重新发送该数据包。
考虑如下的情况:客户端发送了一个连接请求报文段到服务端,但是在某些网络节点上长时间滞留了,而后客户端又超时重发了一个连接请求报文段该服务端,而后正常建立连接,数据传输完毕,并释放了连接。如果这时候第一次发送的请求报文段延迟了一段时间后,又到了服务端,很显然,这本是一个早已失效的报文段,但是服务端收到后会误以为客户端又发出了一次连接请求,于是向客户端发出确认报文段,并同意建立连接。
假设不采用三次握手,这时服务端只要发送了确认,新的连接就建立了,但由于客户端没有发出建立连接的请求,因此不会理会服务端的确认,也不会向服务端发送数据,而服务端却认为新的连接已经建立了,并在一直等待客户端发送数据,这样服务端就会一直等待下去,直到超出保活计数器的设定值,而将客户端判定为出了问题,才会关闭这个连接。这样就浪费了很多服务器的资源。而如果采用三次握手,客户端就不会向服务端发出确认,服务端由于收不到确认,就知道客户端没有要求建立连接,从而不建立该连接。
《软件架构设计》:无论两次、三次、四次,永远都不知道最后发出去的数据包对方是否收到了,问题无解。那为什么是三次呢?因为三次握手恰好可以保证client 和server 对自己的发送、接收能力做了一次确认
- client 发送seq=x,收到了回复的seq=y,ack=x+1 则客户端知道自己的发送、接收没问题
- 服务端发送 seq=y,收到了第三次的ack = y+1,可以确认自己的发送、接收也没问题
与基于拜占庭节点的复杂的一致性协议相比,笔者猜测,tcp 得以简单一点的因素包括但不限于
- 点对点两两通信
- 基于可信节点,“不可信”来自于网络通道的不可靠,但也只是丢包、延迟和重复,没有篡改。
关闭时为什么要TIME_WAIT?
一个连接由<client ip,client port,server ip,server port> 唯一标识,连接关闭之后再重开应该是一个新的连接,但用四元组无法区分新老连接。老连接关闭后,仍可能有数据包在网络上“闲逛”,新连接打开时可能会收到 老连接的 数据包。为此:
- TCP/IP 定义了一个MSL,任何一个IP数据包在网络上逗留的最长时间是MSL,默认120s,超过这个时间,中间的路由节点会将数据包丢弃
- 一个连接保持TIME_WAIT 2*MSL 时间,再进入closed状态,就可以避免老连接上闲逛的数据包串到新的连接上
综上,一个连接不是想关就能关的,关闭后要等2*MSL 才能重开,这就造成一个问题:如果频繁的创建连接,最后可能导致大量的连接处于TIME_WAIT状态,最终耗光所有的连接资源。这也是为什么client要建连接池。
“聪明的”tcp/ip
Sliding Window:TCP头里有一个字段叫Window,又叫Advertised-Window,这个字段是接收端告诉发送端自己还有多少缓冲区可以接收数据。于是发送端就可以根据这个接收端的处理能力来发送数据,而不会导致接收端处理不过来。
拥塞控制:TCP通过Sliding Window来做流控(Flow Control),但是TCP觉得这还不够,因为Sliding Window需要依赖于连接的发送端和接收端,其并不知道网络中间发生了什么。
如果网络上的延时突然增加,那么,TCP对这个事做出的应对只有重传数据,但是,重传会导致网络的负担更重,于是会导致更大的延迟以及更多的丢包,于是,这个情况就会进入恶性循环被不断地放大。试想一下,如果一个网络内有成千上万的TCP连接都这么行事,那么马上就会形成“网络风暴”,TCP这个协议就会拖垮整个网络。
拥塞控制主要是四个算法:1)慢启动,2)拥塞避免,3)拥塞发生,4)快速恢复。这四个算法不是一天都搞出来的,这个四算法的发展经历了很多时间,到今天都还在优化中。
backlog
tcp 连接机制 的缺陷 常见Dos攻击原理及防护(死亡之Ping、Smurf、Teardown、LandAttack、SYN Flood) 故意让服务端 维持一堆半连接,直到超过 backlog
To understand the backlog argument, we must realize that for a given listening socket, the kernel maintains two queues :
- An incomplete connection queue, which contains an entry for each SYN that has arrived from a client for which the server is awaiting completion of the TCP three-way handshake. These sockets are in the SYN_RCVD state .
- A completed connection queue, which contains an entry for each client with whom the TCP three-way handshake has completed. These sockets are in the ESTABLISHED state
A completed connection queue, which contains an entry for each client with whom the TCP three-way handshake has completed. These sockets are in the ESTABLISHED state.Berkeley-derived implementations add a fudge factor to the backlog: It is multiplied by 1.5
When a SYN arrives from a client, TCP creates a new entry on the incomplete queue and then responds with the second segment of the three-way handshake: the server’s SYN with an ACK of the client’s SYN (Section 2.6). This entry will remain on the incomplete queue until the third segment of the three-way handshake arrives (the client’s ACK of the server’s SYN), or until the entry times out. (Berkeley-derived implementations have a timeout of 75 seconds for these incomplete entries.)
If the queues are full when a client SYN arrives, TCP ignores the arriving SYN (pp. 930–931 of TCPv2); it does not send an RST. This is because the condition is considered temporary, and the client TCP will retransmit its SYN, hopefully finding room on the queue in the near future. If the server TCP immediately responded with an RST, the client’s connect would return an error, forcing the application to handle this condition instead of letting TCP’s normal retransmission take over. Also, the client could not differentiate between an RST in response to a SYN meaning “there is no server at this port” versus “there is a server at this port but its queues are full.”
端口
什么是端口号(port)?
注意,这个号码是用在TCP,UDP上的一个逻辑号码,并不是一个硬件端口,我们平时说把某某端口封掉了,也只是在IP层次把带有这个号码的IP包给过滤掉了而已。
Socket 是一个编程接口,(linux tcp/ip协议栈的实现通常有一个socket层),包括几个最基本的函数接口。比如create、listen、accept、connect、read和write等等。Socket可以支持不同的传输层协议(TCP或UDP ),Socket跟TCP/IP 并没有必然的联系,socket的出现只是可以更方便的使用TCP/IP 协议栈而已。
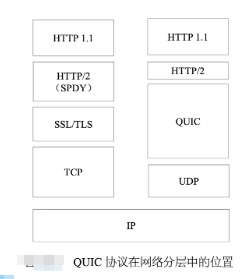
TCP 不是唯一
Tcp 有一些痼疾诸如队头阻塞、重传效率低等,因此Google 基于UDP 提出了一个QUIC(quick udp internet connection),在重传效率、减少RTT次数、连接迁移(以客户端生成的64位标识而不是4元组来表示一个连接,更适合移动客户端频繁建立连接的场景)等方面做了一些工作。