简介
一些体会
有时候不得不承认,一些概念可能都火了五六年了, 但在实践层面仍然是滞后。能用是不够的,好用才行。有一个大牛说过:ci/cd 和 devops 是一体两面的。比如对于java 开发来说,用物理机部署(拷贝文件、配置nginx等) 和使用k8s 发布服务一样复杂(虽说k8s可以一键发布,但理解k8s对他来说是个负担),至少前者他还懂一点。
Kubernetes何时才会消于无形却又无处不在?一项技术成熟的标志不仅仅在于它有多流行,还在于它有多不起眼并且易于使用。Kubernetes依然只是一个半成品,还远未达到像Linux内核及其周围操作系统组件在过去25年中所做到的那种“隐形”状态。
解读2018:我们处在一个什么样的技术浪潮当中?Kubernetes 还是太底层了,真正的云计算并不应该是向用户提供的 Kubernetes 集群。2014 年 AWS 推出 Lambda 服务,Serverless 开始成为热词。从理论上说,Serverless 可以做到 NoOps、自动扩容和按使用付费,也被视为云计算的未来。Serverless 是我们过去 25 年来在 SaaS 中走的最后一步,因为我们已经渐渐将越来越多的职责交给了服务提供商。——Joe Emison 《为什么 Serverless 比其他软件开发方法更具优势》
赢在orchestrator
一般orchestrator 包括但不限于以下功能:
- Organizational primitives,比如k8s的label
- Scheduling of containers to run on a ost
- Automated health checks to determine if a container is alive and ready to serve traffic and to relaunch it if necessary
- autoscaling
- upgrading strategies,from rolling updates to more sophisticated techniques such as A/B and canary deployments.
- service discovery to determine which host a scheduled container ended upon,usually including DNS support.
The unit of scheduling in Kubernetes is a pod. Essentially, this is a tightly coupled set of one or more containers that are always collocated (that is, scheduled onto a node as a unit); they cannot be spread over nodes.
- The number of running instances of a pod—called replicas—can be declaratively stated and enforced through controllers.
- The logical organization of all resources, such as pods, deployments, or services, happens through labels. label 的作用不小啊
Kubernetes is highly extensible, from defining new workloads and resource types in general to customizing its user-facing parts, such as the CLI tool kubectl (pronounced cube cuddle).
Julia Evans 系列
once you have a working Kubernetes cluster you really can set up a production HTTP service (“run 5 of this application, set up a load balancer, give it this DNS name, done”) with just one configuration file. 然后业务开发会说,我基于物理机虽然没有这么快,但tomcat、nginx、dns 这些都是一次就好了呀,后续的开发也是一键发布呀。k8s 优势在于:它可以横推,对开发来说部署java application 和 部署mysql 是两个事情,但对于k8s 来说,就是一个事情。
这个事情在商业上是类似,最开始都是先垂直发展,然后面横向打通。你搞电商,我搞外卖,但到最后发现物流、资金流、云计算可以打通。
Container Engine cluster
本小节主要来自对https://cloud.google.com/container-engine/docs的摘抄,有删减。
本小节主要讲了Container Engine cluster和Pod的概念
A Container Engine cluster is a group of Compute Engine instances running Kubernetes. It consists of one or more node instances, and a Kubernetes master instance. A cluster is the foundation of a Container Engine application—pods,services, and replication controllers all run on top of a cluster.
一个Container Engine cluster主要包含一个master和多个slave节点,它是上层的pod、service、replication controllers的基础。
- The Kubernetes master, Every cluster has a single master instance. The master provides a unified view into the cluster and, through its publicly-accessible endpoint, is the doorway(途径) for interacting with the cluster.
- Nodes, A cluster can have one or more node instances. These are managed from the master, and run the services necessary to support Docker containers. Each node runs the Docker runtime and hosts a Kubelet agent(管理docker runtime), which manages the Docker containers scheduled on the host. Each node also runs a simple network proxy(网络代理程序).
The master runs the Kubernetes API server, which services REST requests, schedules pod creation and deletion on worker nodes, and synchronizes pod information (such as open ports and location) with service information.
- 提供统一视图
- service REST requests
- 调度
- 控制,使得actual state满足desired state
设计理念
- 声明式 VS 命令式, 声明式优点很多,一个很重要的点是:在分布式系统中,任何组件都可能随时出现故障。当组件恢复时,需要弄清楚要做什么,使用命令式 API 时,处理起来就很棘手。但是使用声明式 API ,组件只需查看 API 服务器的当前状态,即可确定它需要执行的操作。
- 显式的 API, Kubernetes 是透明的,它没有隐藏的内部 API。换句话说 Kubernetes 系统内部用来交互的 API 和我们用来与 Kubernetes 交互的 API 相同。这样做的好处是,当 Kubernetes 默认的组件无法满足我们的需求时,我们可以利用已有的 API 实现我们自定义的特性。
- 无侵入性, 我们的应用达到镜像后, 不需要改动就可以遨游在 Kubernetes 集群中。 Kubernetes 以一种友好的方式将 Secret、Configuration等注入 Pod,减少了大家的工作量,而无需重写或者很大幅度改变原有的应用代码。
- 有状态的移植, 比如 PersistentVolumeClaim 和 PersistentVolume
整体结构
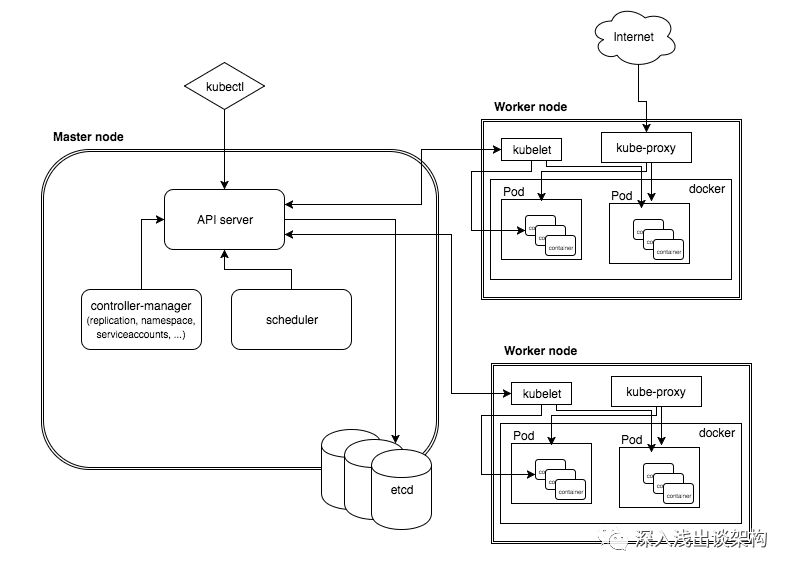
调整后的架构图
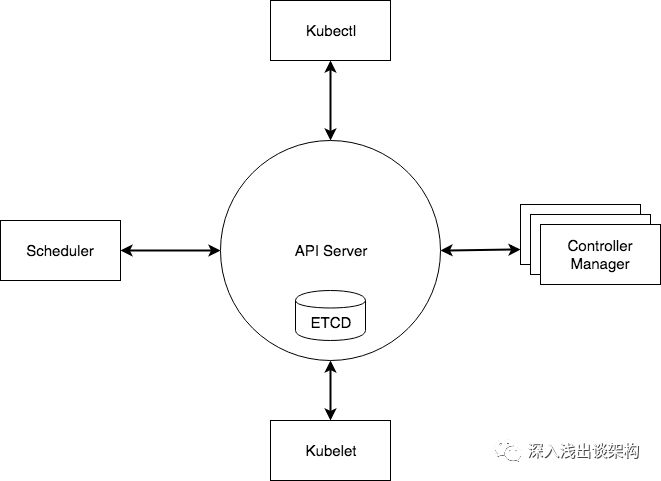
- etcd,各个组件通信都并不是互相调用 API 来完成的,而是把状态写入 ETCD(相当于写入一个消息),其他组件通过监听 ETCD 的状态的的变化(相当于订阅消息),然后做后续的处理,然后再一次把更新的数据写入 ETCD。
- api server,各个组件并不是直接访问 ETCD,而是访问一个代理,这个代理是通过标准的RESTFul API,重新封装了对 ETCD 接口调用,除此之外,这个代理还实现了一些附加功能,比如身份的认证、缓存等
- Controller Manager 是实现任务调度的
- Scheduler 是用来做资源调度的
一位大牛的整理