前言
根据netty-demo的例子几乎做不了任何事,本文泛讲下netty对http协议的实现,从中可以学习到很多有益的东西
- 复杂协议如何解析
- 如何发送和接收较大数据(比如大文件)
ReplayingDecoder,解析复杂协议的利器
ReplayingDecoder 是 byte-to-message 解码的一种特殊的抽象基类,在ByteToMessageDecoder中,你bytebuf.readInt之前,要先判断下有没有四个字节。而在ReplayingDecoder中,你直接readint就好了。其原理的关键就是用了ReplayingDecoderBuffer,而不是ByteToMessageDecoder简单的bytebuf。
ReplayingDecoderBuffer是对一个普通的ChannelBuffer的Wrapper,它的很多方法都是直接调用被wrap后的ChannelBuffer的方法,它们使用了几个checkIndex和checkReadableBytes函数:
public int readInt() {
checkReadableBytes(4);
return buffer.readInt();
}
private void checkIndex(int index) {
if (index > buffer.writerIndex()) {
throw replay;
}
}
当要读的数据还没有在这次处理中到达时,将抛出一个Replay Signal。沿着这个Replay Signal就能知道它的工作原理了。ReplayingDecoder部分源码如下
private final ReplayingDecoderBuffer replayable = new ReplayingDecoderBuffer(); // 装饰类
void callDecode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) {
// 由replayable代理对ByteBuf的操作
replayable.setCumulation(in);
int oldReaderIndex = checkpoint = in.readerIndex();
int outSize = out.size();
S oldState = state;
try {
decode(ctx, replayable, out);
} catch (ReplayError replay) {
// Return to the checkpoint (or oldPosition) and retry.
int checkpoint = this.checkpoint;
if (checkpoint >= 0) {
cumulation.readerIndex(checkpoint);
} else {
// Called by cleanup() – no need to maintain the readerIndex
// anymore because the buffer has been released already.
}
}
}
假设decode方法中,buf没有四个字节,就调用了readint,decode方法会抛出Replay Signal,Replay Signal被ReplayingDecoder catch住。checkpoint两个目的:
- 处理buffer前(调用子类的decode方法前),事先记住当前buffer的readerIndex(学名叫checkpoint),假设数据没有四个字节,子类就调用了readint,子类的decode方法会抛出Replayerror,那么就当此次解析白干,恢复buffer的readerindex
- checkpoint还可以根据子类的状态做调整。第一点是数据到达不完全的情况,假设数据由header和body两部分组成,当header数据没有完全到达时,将header从buffer中清除掉(更新checkpoint成现在buf的readerIndex),那么在此之后收到消息的时候就不需要再处理header了,同时为了达到这个目的,解码器还需要保存当前的处理状态:记录当前是在处理header还是body,当处理完后,设置下一个状态。所以在Netty的Pipeline中,解码器也必须每一个channel一个,不能共用,因为它保存了处理的状态信息。
例子可以参见HttpObjectDecoder
HTTP请求处理
http的一些细节
http协议中支持内容编码和分块编码。httpchunk对应分块编码时的解析情况
http协议中的媒体类型有一种是multipart,这类报文中往往包含多个报文,它们合在一起作为一个复杂的报文发送。每一部分是独立的,不同的部分用分界字符串联系在一起。《http权威指南》第366页展示了,如果上传一个文件,那么http协议数据会是什么样子。同时,http对这类请求的响应也是多部分的。(注意不是多次发送)
一般请求处理
一般http消息的处理逻辑中,pipeline中包含HttpRequestDecoder,HttpResponseEncoder,HttpServerInboundHandler(自定义业务实现即可)
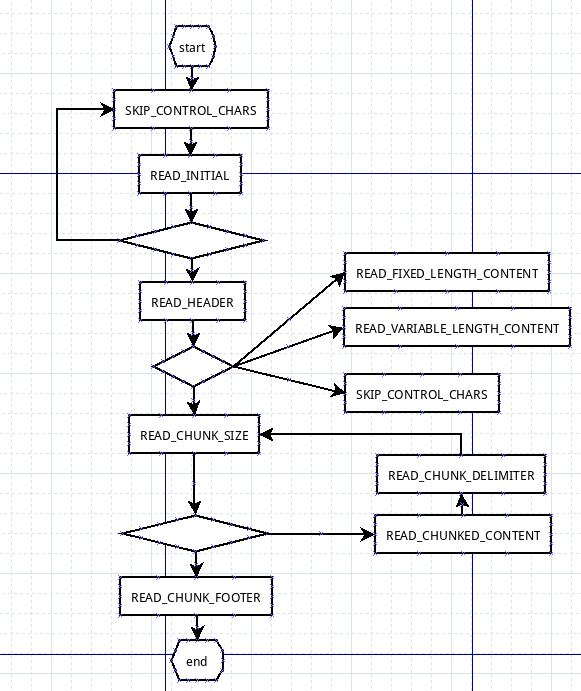
从HttpRequestDecoder开始,HttpRequestDecoder extends HttpObjectDecoder,HttpObjectDecoder extends ReplayingDecoder。这里用了模板模式,HttpRequestDecoder只是实现某个子方法,重点逻辑在HttpObjectDecoder中。作为一个ReplayingDecoder子类,其复杂性就体现在state的设计与转换上,如图所示:
NETTY Http协议对应的model类体系结构如下。(我们个人约定协议时,只是约定格式,读取和写入时,直接writeInt和readInt,简单粗暴,看来要向netty学习下)
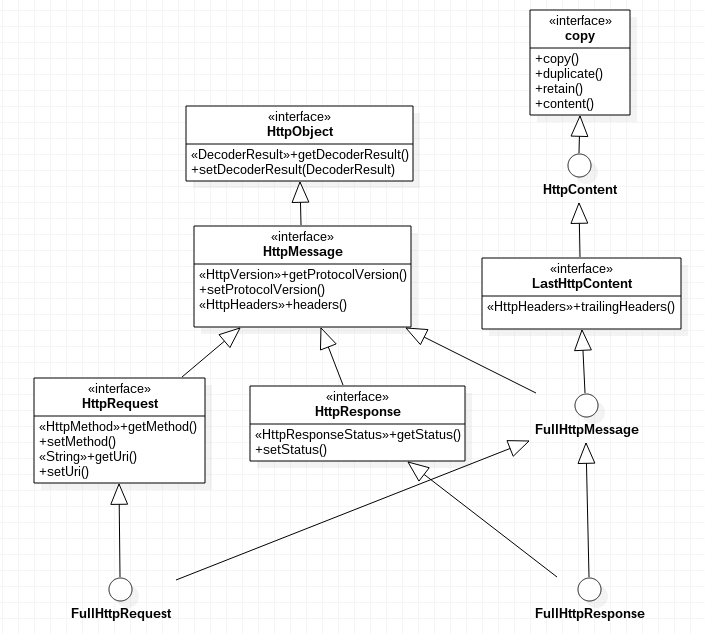
HttpContent会保有一个bytebuf,其主要方法来自bytebufholder,自己没增加什么新的方法,这说明它就是一个bytebufholder
带chunked的http请求处理
带chunk的http消息的处理逻辑中,pipeline中包含HttpRequestDecoder,HttpObjectAggregator,HttpResponseEncoder,ChunkedWriteHandler,HttpServerInboundHandler(自定义业务实现即可)
HttpRequestDecoder是ByteToMessage,HttpObjectAggregator是MessageToMessage。HttpRequestDecoder将字节转化为一个个对象,HttpObjectAggregator将一个个对象组合成FullHttprequest
HttpObjectDecoder中比较有意思的一点是,它的state切换,还收客户端传递参数的影响。read header之后,如果发现header中带有chunked相关配置,则更新下一个状态为READ_CHUNK_SIZE,读取chunk的时候,先读size,再读content,期间会一直添加HttpContent直到READ_CHUNK_FOOTER,添加一个LastHttpContent对象。
HttpRequestDecoder每次处理状态,构建一个新的对象(对应代码就是out.add(HttpMessage|HttpContent|LastHttpContent)),HttpObjectAggregator都会接收并处理一次,针对不同的类型做归并处理,HttpContent归并成一个CompositeByteBuf赋给FullHttpRequest,最后返回FullHttpRequest,触发业务Handler。
如何缓存较大的数据(multipart http请求处理)
在https://github.com/netty/netty.git中有一些netty示例代码,从中我们可以看到netty http处理大文件的方式。
在netty-example中,有一个io.netty.example.http.upload包,其pipeline构成是HttpRequestDecoder,HttpResponseEncoder,HttpContentCompressor,HttpUploadServerHandler。HttpUploadServerHandler的主角就是HttpPostRequestDecoder。在这个pipeline中,HttpRequestDecoder之后,不再使用HttpObjectAggregator,为什么不再pipeline中直接使用HttpPostRequestDecoder呢?估计HttpPostRequestDecoder没有实现ByteToMessage或者MessageToMessage,所以不能直接加到pipeline中。
HttpRequestDecoder在解析完http头部后,就会向HttpUploadServerHandler发送HttpMessage(这时还没有body),HttpUploadServerHandler就可以根据头部信息,使用相应HttpPostRequestDecoder来接收后面的HttpContent。
InterfaceHttpPostRequestDecoder有三个子类,HttpPostRequestDecoder,HttpPostStandardRequestDecoder HttpPostMultipartRequestDecoder。
HttpPostRequestDecoder的构造方法中有一个代码,暴露了三者之间的关系,HttpPostRequestDecoder就是一个装饰类。
public HttpPostRequestDecoder(HttpDataFactory factory, HttpRequest request, Charset charset) {
// Fill default values
if (isMultipart(request)) {
decoder = new HttpPostMultipartRequestDecoder(factory, request, charset);
} else {
decoder = new HttpPostStandardRequestDecoder(factory, request, charset);
}
}
以HttpPostMultipartRequestDecoder为例
HttpPostMultipartRequestDecoder{
private ByteBuf undecodedChunk;临时保存HttpContent(就是一个byteholder),因为此时HttpContent本质上是字节数组,所以叫undecoded
// offer是HttpPostMultipartRequestDecoder对外提供的主要方法
offer(HttpContent content){
ByteBuf buf = content.content();
数据给undecodedChunk
parseBody(); ==> parseBodyMultipart(); ==> InterfaceHttpData decodeMultipart(MultiPartStatus state) ==》 如果是文件上传类型 ==> getFileUpload(multipartDataBoundary); {
1. 拿到各种属性
2. 创建FileUpload currentFileUpload,根据文件大小的不同,会将数据直接写到磁盘上
3. currentFileUpload根据头信息中的文件分隔符加载undecodedChunk中的数据(可能加载完,也可能加载不完)
}
}
}
写回响应结果
如果返回的数据比较大,可以使用ChunkedWriteHandler,这个类其实跟http没什么关系,你写较大的数据时,都可以使用。
把较大的文件写入到网络,有两种优化方法,
-
零拷贝,将文件数据直接从文件系统弄到网络堆栈
FileInputStream in = new FileInputStream(file); //1 FileRegion region = new DefaultFileRegion(in.getChannel(), 0, file.length()); //2 channel.writeAndFlush(region).addListener(new ChannelFutureListener(){}); -
一块一块读写,不要一次把文件全部加载到内存
ctx.writeAndFlush(new ChunkedStream(new FileInputStream(file)));