简介
事务一致性属于 一致性问题的一种(另一种是副本一致性),建议先看下 串一串一致性协议
在实际的业务中,分布式事务有以下表现形式:
- 跨数据库操作
- 数据库与rpc 等混合操作
- 多rpc 操作
文章整体结构来自 实践丨分布式事务解决方案汇总:2PC、消息中间件、TCC、状态机+重试+幂等
![]()
一个问题不同层面解决
2018.9.26 补充:《左耳听风》中提到:
-
对于应用层上的分布式事务一致性
- 吞吐量大的最终一致性方案:消息队列补偿等
- 吞吐量小的强一致性方案:两阶段提交
- 数据存储层解决这个问题的方式 是通过一些像paxos、raft或是nwr这样的算法和模型来解决。 PS:这可能是因为存储层 主要是副本一致性问题
- 在实践中,还是尽量在数据存储层解决分布式事务问题。比如TiDB、OceanBase等,类似于一个无限容量的数据库 ==> 无需跨库操作 ==> 减少分布式事务问题。由此可见,一致性问题可以 “转嫁”
2PC/3PC
过程
正常情况
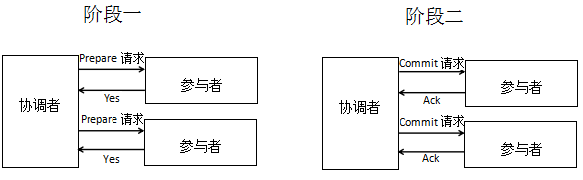
异常情况
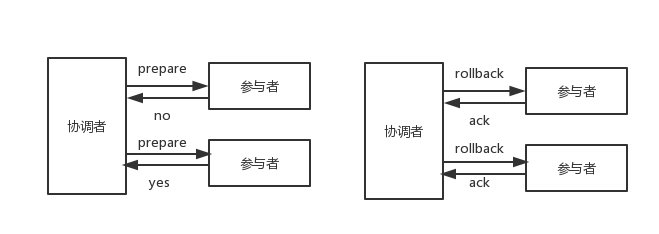
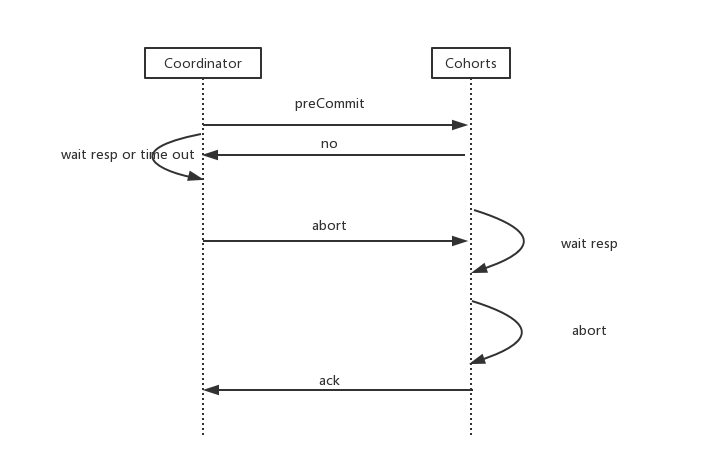
无论事务提交,还是事务回滚,都是两个阶段
2pc有很多问题,比如单点、同步阻塞等,此处我只讨论数据一致性问题:在二阶段提交协议的阶段二,即执行事务提交的时候,当协调者向所有的参与者发送Commit请求之后,发生了局部网络异常或者是协调者在尚未发送完Commit请求之前自身发生了崩溃,导致最终只有部分参与者收到了Commit请求。于是,这部分收到了Commit请求的参与者就会进行事务的提交,而其他没有收到Commit请求的参与者则无法进行事物提交,于是整个分布式系统便出现了数据不一致的现象。
正常情况
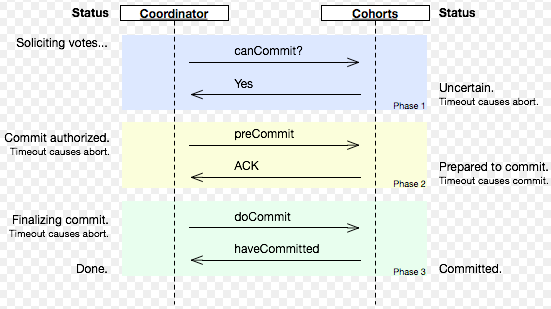
异常情况
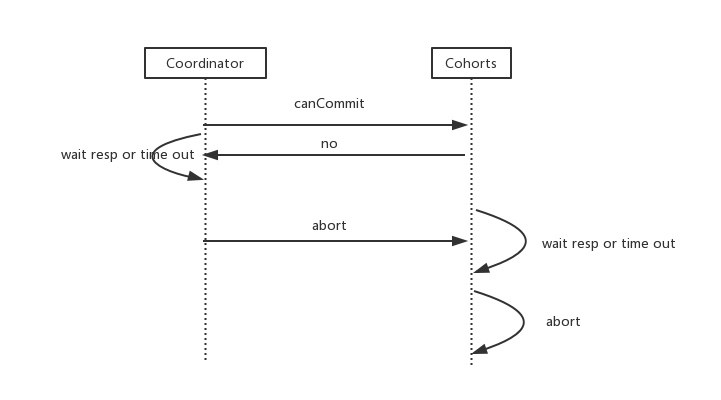
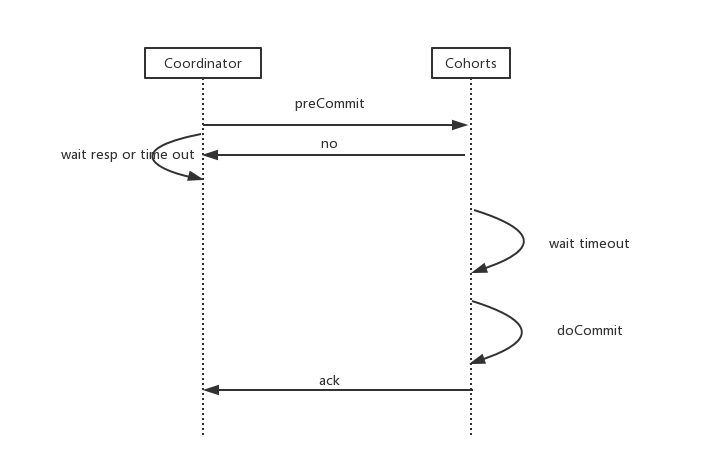
在分布式环境下,分布式系统的每一次请求和响应,存在特有的三态概念:即成功、失败、超时。相对于2pc,3pc处理了timeout问题。但3pc在数据一致性上也有问题:在参与者接收到preCommit消息后,如果出现网络分区,此时协调者所在的节点和参与者无法进行正常的网络通信,在这种情况下,参与者依然会进行事物的提交,就可能出现不同节点成功or失败,这必然出现数据的不一致。
2PC除本身的算法局限外,还有一个使用上的限制,就是它主要用在两个数据库之间(数据库实现了XA协议)。但以支付宝的转账为例,是两个系统之间的转账,而不是底层两个数据库之间直接交互,所以没有办法使用2PC。
在代码上的表现
- 声明式事务
- 编程式事务
本地事务处理
Connection conn = null;
try{
//若设置为 true 则数据库将会把每一次数据更新认定为一个事务并自动提交
conn.setAutoCommit(false);
// 将 A 账户中的金额减少 500
// 将 B 账户中的金额增加 500
conn.commit();
}catch(){
conn.rollback();
}
跨数据库事务处理
UserTransaction userTx = null;
Connection connA = null;
Connection connB = null;
try{
userTx.begin();
// 将 A 账户中的金额减少 500
// 将 B 账户中的金额增加 500
userTx.commit();
}catch(){
userTx.rollback();
}
代码的封装跟2pc的实际执行过程有所不同,可以参见JTA与TCC
TCC
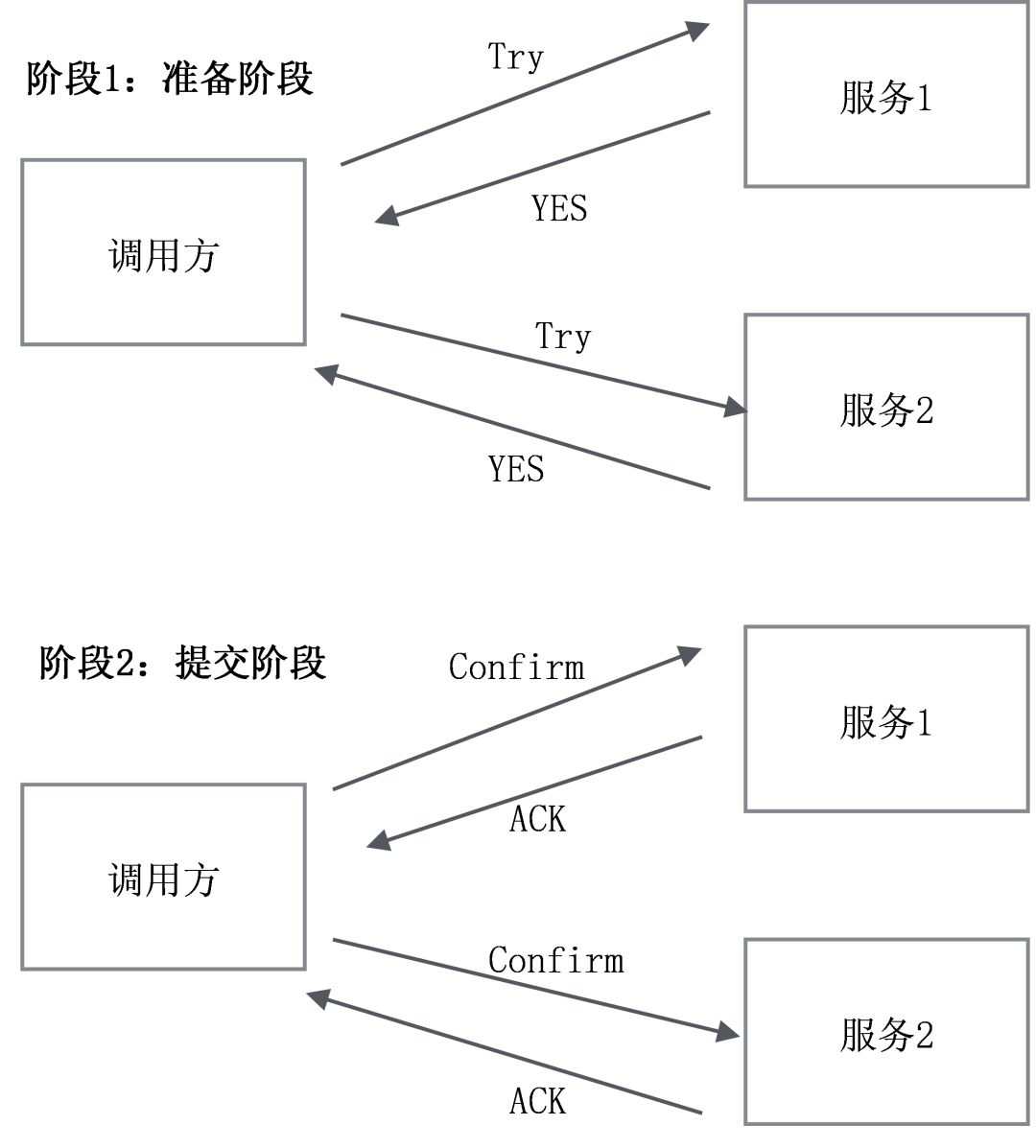
TCC借鉴2PC的思路,对比上一小节可以看到,调用方充当了协调者的角色。那么它是如何解决2PC的问题的呢?也就是说,在阶段2,调用方发生宕机,或者某个服务超时了,如何处理呢?答案是:不断重试(Confirm/Cancel)!不管是Confirm失败了,还是Cancel失败了,都不断重试。这就要求Confirm和Cancel都必须是幂等操作。注意,这里的重试是由TCC的框架来执行的,而不是让业务方自己去做。
github 案例项目
最终一致性+消息中间件
实践丨分布式事务解决方案汇总:2PC、消息中间件、TCC、状态机+重试+幂等一般的思路是通过消息中间件来实现“最终一致性”
错误的方案:网络调用(rpc/db/mq)和更新DB放在同一个事务里面
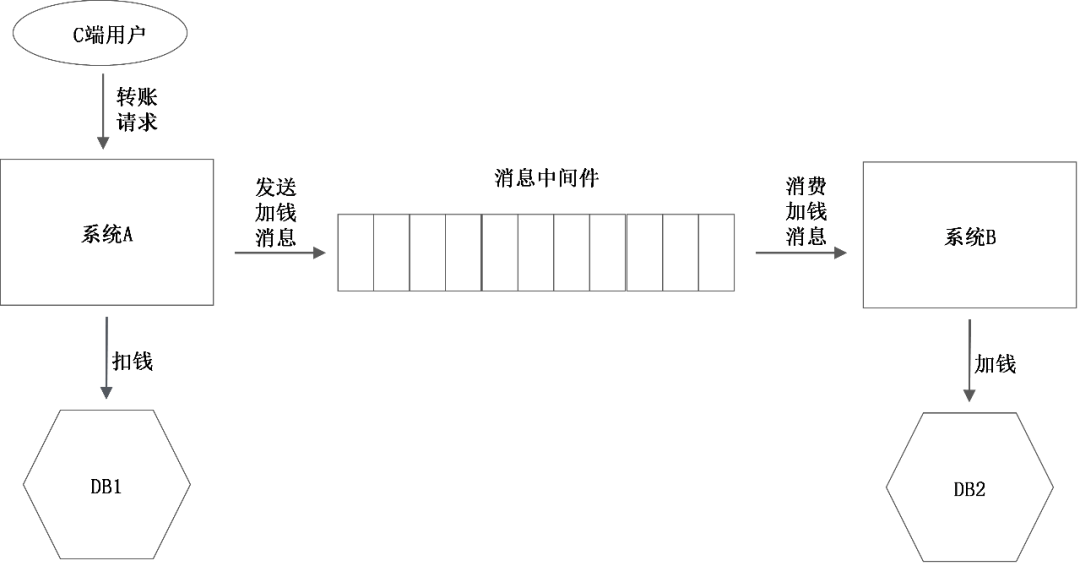
这个方案有两个问题
- 发送消息失败,发送方并不知道是消息中间件没有收到消息,还是消息已经收到了,只是返回response的时候失败了?
- 把网络调用放在数据库事务里面,可能会因为网络的延时导致数据库长事务。严重的会阻塞整个数据库,风险很大。
最终一致性:第1种实现方式(业务方自己实现)

- 系统A不再直接给消息中间件发送消息,而是把消息写入到消息表中。把DB1的扣钱操作(表1)和写入消息表(表2)这两个操作放在一个数据库事务里,保证两者的原子性。
- 系统A准备一个后台程序,源源不断地把消息表中的消息传送给消息中间件。如果失败了,也不断尝试重传。因为网络的2将军问题,系统A发送给消息中间件的消息网络超时了,消息中间件可能已经收到了消息,也可能没有收到。系统A会再次发送该消息,直到消息中间件返回成功。所以,系统A允许消息重复,但消息不会丢失,顺序也不会打乱。
- 系统A保证了消息不丢失
系统B对消息的消费要解决下面两个问题:
- 丢失消费,系统B从消息中间件取出消息(此时还在内存里面),如果处理了一半,系统B宕机并再次重启,此时这条消息未处理成功,怎么办?答案是通过消息中间件的ACK机制,凡是系统B(向mq)发送ACK的消息,系统B重启之后消息中间件不会再次推送;
- 重复消费。除了ACK机制,可能会引起重复消费;系统A的后台任务也可能给消息中间件重复发送消息。为此,系统B增加一个判重表(业务允许的话也可以直接业务判重)
如果消费失败了,则可以重试,但还一直失败怎么办?是否要自动回滚整个流程?答案是人工介入。从工程实践角度来讲,这种整个流程自动回滚的代价是非常巨大的,不但实现起来很复杂,还会引入新的问题。比如自动回滚失败,又如何处理?对应这种发生概率极低的事件,采取人工处理会比实现一个高复杂的自动化回滚系统更加可靠,也更加简单。
弱一致性+基于状态的补偿
如果用最终一致性方案,因为是异步操作,如果库存扣减不及时会导致超卖,因此最终一致性的方案不可行;如果用TCC方案,则意味着一个用户请求要调用两次(Try和Confirm)订单服务、两次(Try和Confirm)库存服务,性能又达不到要求。如果用事务状态表,要写事务状态,也存在性能问题。
既要满足高并发,又要达到一致性,鱼和熊掌不能兼得。可以利用业务的特性,采用一种弱一致的方案。
比如对于电商的购物来讲,允许少卖,但不能超卖。
先扣库存再创建订单
| 扣库存 | 提交订单 | 调用方处理 |
|---|---|---|
| 成功 | 成功 | 返回成功 |
| 成功 | 失败 | 告诉用户失败,用户重试(扣库存+提交订单),可能会导致多扣库存 |
| 失败 | 不提交订单 | 告诉用户失败,用户重试(扣库存+提交订单),可能会导致多扣库存 |
先创建订单再扣库存
| 提交订单 | 扣库存 | 调用方处理 |
|---|---|---|
| 成功 | 成功 | 返回成功 |
| 成功 | 失败 | 告诉用户失败,用户重试(提交订单+扣库存),可能会导致多扣库存 |
| 失败 | 不提扣库存 | 告诉用户失败,用户重试(提交订单+扣库存) |
也就是数据库中可能存在 库存记录无法对应订单,但不可能存在订单记录无法对应库存。
库存每扣一次,都会生成一条流水记录。这条记录的初始状态是“占用”,等订单支付成功后,会把状态改成“释放”。通过比对,得到库存系统的“占用又没有释放的库存流水”与订单系统的未支付的订单,就可以回收这些库存,同时把对应的订单取消。类似12306网站,过一定时间不支付,订单会取消,将库存释放。
对账
岂止事务有状态,系统中的各种数据对象都有状态,或者说都有各自完整的生命周期,同时数据与数据之间存在着关联关系。我们可以很好地利用这种完整的生命周期和数据之间的关联关系,来实现系统的一致性,这就是“对账”。
在前面的方案中,无论最终一致性,还是TCC、事务状态表,都是为了保证“过程的原子性”,也就是多个系统操作(或系统调用),要么全部成功,要么全部失败。但所有的“过程”都必然产生“结果”,过程是我们所说的“事务”,结果就是业务数据。一个过程如果部分执行成功、部分执行失败,则意味着结果是不完整的。从结果也可以反推出过程出了问题,从而对数据进行修补,这就是“对账”的思路!
假定从“已支付”到“下发给仓库”最多用1个小时;从“下发给仓库”到“出仓完成”最多用8个小时。意味着只要发现1个订单的状态过了1个小时之后还处于“已支付”状态,就认为订单下发没有成功,需要重新下发,也就是“重试”。同样,只要发现订单过了8个小时还未出仓,这时可能会发出报警,仓库的作业系统是否出了问题……诸如此类。
小结
- “最终一致性”是一种异步的方法,数据有一定延迟。异步就离不了队列,方法调用改为消息传递,方法调用成功转换为消息发送一定要成功,消费方一定要消费成功,实在是消费失败了就人工处理。
- TCC是一种同步方法,但TCC需要两个阶段,性能损耗较大。因为是同步操作,所以子服务成功与失败是明确知道的,调用方通过重试失败的子服务来确保一定成功,调用失败后不断重试,重试一定次数后同样转入人工处理。
- 弱一致性,有一个子服务失败则中断调用(已经成功的子服务“补偿”处理),整体重试。
- “对账”是一个事后过程,相当于对 对关联服务的成功与失败放任不管了