简介
从PaaS的大概念来理解mesos的小概念。在传统的IT架构里,我们分配资源的单位是服务器。PaaS讲究的是将计算、存储和网络三大资源标准化,然后对上提供api。原先部署某个服务,要自己到那个服务器上部署,而现在则是直接调接口。以docker为例,部署某个服务,就是命令某个主机执行docker run命令。
mesos 是什么
下面是来自apache官网的简介:
Apache Mesos abstracts CPU, memory, storage, and other compute resources away from machines (physical or virtual), enabling fault-tolerant and elastic distributed systems to easily be built and run effectively.
Mesos is built using the same principles as the Linux kernel, only at a different level of abstraction. The Mesos kernel runs on every machine and provides applications (e.g., Hadoop, Spark, Kafka, Elastic Search) with API’s for resource management and scheduling across entire datacenter and cloud environments.
这里有一句话很有意思,说mesos类似于linux kernel,但是集群层次的抽象。观察linux的进程控制块,是各种资源的结合(比如文件描述符)。启动进程,操作系统负责帮进程处理资源的获取和访问等问题。Mesos则允许更精细化的资源的切片和分割。底层的资源像CPU、内存等都完全抽象化,不在跟具体的物理机绑在一起分配。类似于,一个分布式文件系统将多个主机的存储能力聚合起来,mesos则是将多个主机的计算、内存等资源聚合起来。
引用Mesos paper里的一句话,来说明Mesos的设计理念:
define a minimal interface that enables efficient resource sharing across frameworks, and otherwise push control of task scheduling and execution to the frameworks
定义一个最小化的接口来支持跨框架的资源共享,其他的调度以及执行工作都委托给框架自己来控制。
mesos主要解决两个基本问题,更主要的是,以接口的、程序可感知可描述的方式来以下问题(在下文的程序实例中,会有更直观的感受)。
- 资源管理。n个主机的资源现在统一分配了,一个任务可以漂移了(一会儿运行在a主机上,一会儿运行在b主机上)。原先一个任务占用资源的上限是其所在主机的全部资源,现在资源共享后,一个任务占用资源的理论上限是整个集群。这就需要管理
- 任务调度。任务被调度在哪个机器上,任务挂了怎么办?但这个事儿还要和具体的框架来做。
资源管理和任务调度,是现在很多二元框架的标配,比如hadoop。mesos更侧重于资源管理,大学时,操作系统的笔记上写着,操作系统的两个目标:资源管理、方便操作(对应着mesos提供api接口)从这个角度讲,mesos也算一个os。
PS,进程和文件,真是一个伟大的抽象。
Container-Networking-Docker-Kubernetes:mesos is a general-purpose cluster resource manager that abstracts the resources of a cluster(cpu,ram etc) in such a way that the cluster appears like one giant computer to the developer. In a sense, mesos acts like the kernel of a distributed operating system. It is hence never used on its own, but always togegher with so-called frameworks such as marathon(for long-running stuff like a web server) or chronos(for batch jobs), or big data and fast data frameworks like apache spark.
关键字
- general-purpose
- cluster resource manager
- 单纯的marathon + mesos 与k8s 对比是不公平的,因为marathon 本身就单单专注于 long-running service
集成
与数据处理框架集成
今天了解一下mesos,感觉老外就是牛,什么都想做一个框架出来,写一个分布式软件的难度一下子降低了好多,很多类似软件,都有用mesos重写一番,Mesos frameworks for a list of apps built on top of Mesos and instructions on how to run them.
以与hadoop集成为例,单纯的使用hadoop
- 加压*.tar.gz,修改xx.xml,向集群复制文件
- 执行
/hadoop_home/sbin/start-all.sh,启动hdfs及yarn - hdfs上准备input目录及数据文件,执行任务
/hadoop_home/bin/hadoop jar hadoop-examples.jar wordcount input output,即可在output目录查看结果。
使用集成mesos之后的hadoop代码,只需在etc/hadoop/mapred-site.xml设置如下必要的参数(针对1.x版本,配置不完整,只是举例说明):
<property>
<name>mapred.jobtracker.taskScheduler</name>
<value>org.apache.hadoop.mapred.MesosScheduler</value>
</property>
<property>
<name>mapred.mesos.master</name>
<value>zk://localhost:2181</value>
</property>
通过mapred.jobtracker.taskScheduler属性指定hadoop使用mesos来调度任务。
在mesos上运行服务
因为大多数状态下,我们用mesos来部署服务,以至于我们认为mesos就是用来部署服务的。其实,更准确的说,mesos是抽象了一套接口,并为这些接口的运行提供支持。
数据处理框架的作业一般是短暂的,比如wordcount计算完毕,则scheduler和executor进程都会退出。而服务一般都是长期的(怪不得叫marathon),并有一些自己的特点,比如服务发现(如何定位)、负载均衡(如何分发请求)、健康检查和失败重启等。marathon就是这样一个服务调度/管理器。
- 确保服务高可用,即当机器发生故障时可以将服务迁移。
- 支持比较多的服务类型,比如web服务、标准shell等
《Mesos大数据资源调度与大规模容器运行最佳实践》中提到,如果将mesos比做操作系统,那么marathon就好比它的init.d,可以确保在其上运行的服务一直运行着。再比如,chronos框架类似于cron,用来处理定时作业。
mesos接口
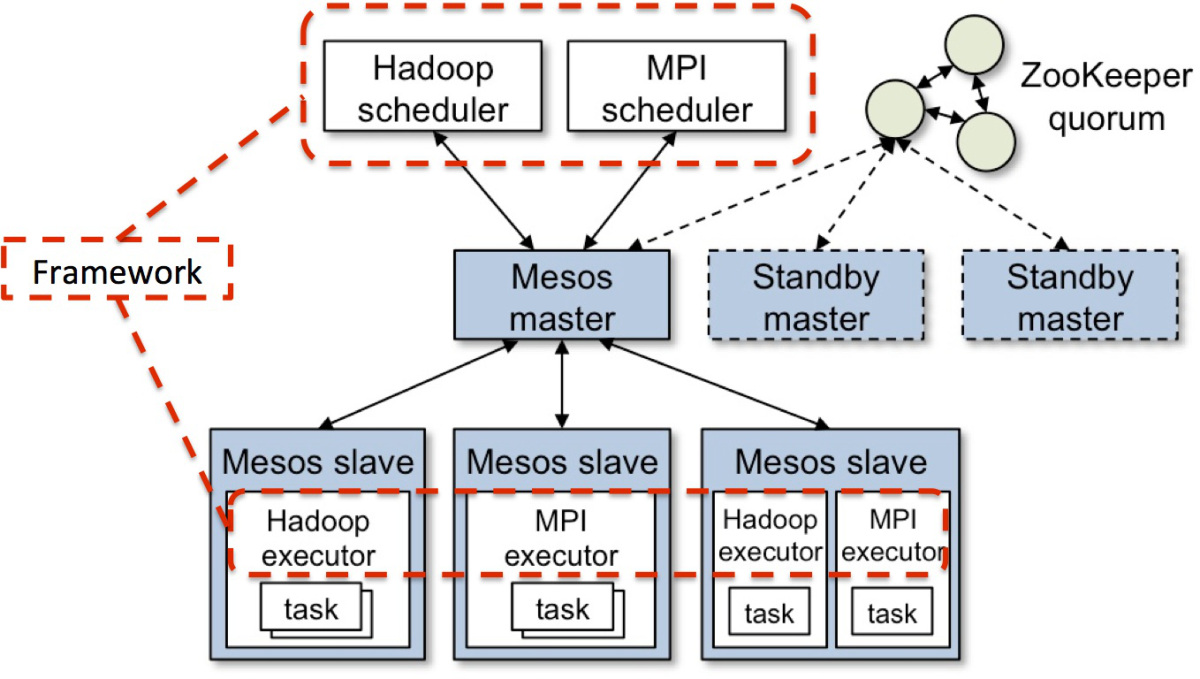
mesos包括以下概念:
- Master daemon
- Slave daemon
- Scheduler
-
Executor
为task提供上下文环境
-
task
具体的任务,类似hadoop中的map task和reduce task
master daemon和slave daemon提供mesos的服务能力,而对于Scheduler和Executor抽象,我们可以通过其接口来理解,接口包含了一系列回调函数:
public abstract interface org.apache.mesos.Scheduler {
// 向SchedulerDriver注册Scheduler
public abstract void registered(org.apache.mesos.SchedulerDriver arg0, org.apache.mesos.Protos.FrameworkID arg1, org.apache.mesos.Protos.MasterInfo arg2);
// 注册成功后
public abstract void reregistered(org.apache.mesos.SchedulerDriver arg0, org.apache.mesos.Protos.MasterInfo arg1);
// 处理来自各slave的Resource offer,以决定将task分配到哪个slave上
public abstract void resourceOffers(org.apache.mesos.SchedulerDriver arg0, java.util.List arg1);
// resource offer撤回
public abstract void offerRescinded(org.apache.mesos.SchedulerDriver arg0, org.apache.mesos.Protos.OfferID arg1);
// 某个task的状态发生改变
public abstract void statusUpdate(org.apache.mesos.SchedulerDriver arg0, org.apache.mesos.Protos.TaskStatus arg1);
// 收到来自某个Executor的消息
public abstract void frameworkMessage(org.apache.mesos.SchedulerDriver arg0, org.apache.mesos.Protos.ExecutorID arg1, org.apache.mesos.Protos.SlaveID arg2, byte[] arg3);
// "失联"后
public abstract void disconnected(org.apache.mesos.SchedulerDriver arg0);
// 某个slave"失联"后
public abstract void slaveLost(org.apache.mesos.SchedulerDriver arg0, org.apache.mesos.Protos.SlaveID arg1);
// 某个executor"失联"后
public abstract void executorLost(org.apache.mesos.SchedulerDriver arg0, org.apache.mesos.Protos.ExecutorID arg1, org.apache.mesos.Protos.SlaveID arg2, int arg3);
// 运行过程中发生错误时
public abstract void error(org.apache.mesos.SchedulerDriver arg0, java.lang.String arg1);
}
executor
public abstract interface org.apache.mesos.Executor {
// 向ExecutorDriver注册Executor
public abstract void registered(org.apache.mesos.ExecutorDriver arg0, org.apache.mesos.Protos.ExecutorInfo arg1, org.apache.mesos.Protos.FrameworkInfo arg2, org.apache.mesos.Protos.SlaveInfo arg3);
// 估计是注册成功后
public abstract void reregistered(org.apache.mesos.ExecutorDriver arg0, org.apache.mesos.Protos.SlaveInfo arg1);
// “失联”后
public abstract void disconnected(org.apache.mesos.ExecutorDriver arg0);
// 运行任务
public abstract void launchTask(org.apache.mesos.ExecutorDriver arg0, org.apache.mesos.Protos.TaskInfo arg1);
// 收到scheduler杀死task的命令
public abstract void killTask(org.apache.mesos.ExecutorDriver arg0, org.apache.mesos.Protos.TaskID arg1);
// 接受scheduler发送的消息
public abstract void frameworkMessage(org.apache.mesos.ExecutorDriver arg0, byte[] arg1);
// 收到scheduler shutdown的命令
public abstract void shutdown(org.apache.mesos.ExecutorDriver arg0);
// 运行过程中出错
public abstract void error(org.apache.mesos.ExecutorDriver arg0, java.lang.String arg1);
}
言而总之,scheduler和executor提供了一系列回调函数。从这些函数中,我们可以看到,假如我们将Scheduler/Executor(task)作为分布式框架的基本模型,那么mesos封装了大量细节,比如:
- slave信息的汇集
- slave有效性检测
- Scheduler与Executor通信(包括task status汇报等)
从而大大减少我们编写一个分布式任务的复杂性。
一个简单的Scheduler示例如下
public class MesosScheduler implements Scheduler {
// 各种回调方法的实现
public static void main(String[] args) {
FrameworkInfo framework = FrameworkInfo.newBuilder()
.setName("MesosSchedulerExample")
.setUser("")
.setRole("*")
.build();
String mesosAddress = args[0];
String executorScriptPath = args[1];
System.setProperty("executor_script_path", executorScriptPath);
MesosScheduler scheduler = new MesosScheduler(1);
MesosSchedulerDriver driver = new MesosSchedulerDriver(scheduler, framework, mesosAddress);
driver.run();
}
}
Executor示例类似
public class MesosExecutor implements Executor {
// 各种回调方法实现
public static void main(String[] args) {
MesosExecutor exec = new MesosExecutor();
new MesosExecutorDriver(exec).run();
}
}
Scheduler和Executor因为包含main函数,是一个java进程,进程执行Scheduler/Executor Driver。Driver会执行Scheduler逻辑(和master daemon交互)和Executor的业务逻辑(和slave daemon交互),在合适的时机调用自定义Scheduler和Executor的回调函数。
简单的例子参见sjarvie/mesos_example,只有三个java类。